rickawsb
用户暂无简介
rickawsb
最近提交ipo的ai芯片的新宠Cerebras火遍硅谷。
其芯片在小模型场景下,其推理速度最高可达 H100 的 20 倍;而超大规模模型(如 400B 参数量级),Cerebras CS-3 系统的单用户响应速度约为 B200 的 2.4 倍
那么cerebras究竟是如何做到的呢? 它是否会成为英伟达杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化
其芯片在小模型场景下,其推理速度最高可达 H100 的 20 倍;而超大规模模型(如 400B 参数量级),Cerebras CS-3 系统的单用户响应速度约为 B200 的 2.4 倍
那么cerebras究竟是如何做到的呢? 它是否会成为英伟达杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化

- 赞赏
- 点赞
- 评论
- 转发
- 分享
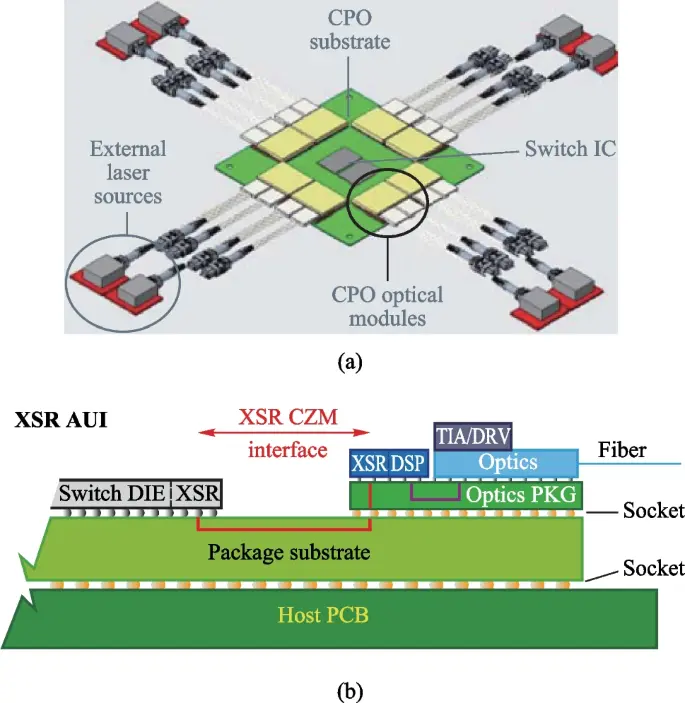
周末深度:从CPO + ELS光源趋势看独立激光器玩家的的位置、边界与终局
AI算力的瓶颈正在从计算转向带宽。随着GPU规模扩大,节点间通信接近N²增长,电互连在功耗与距离上触顶,光互连从“可选项”变成“刚需”。
在这一过程中,CPO(Co-Packaged Optics)与ELS(External Laser Source)开始重构产业链:激光器从模块内部被剥离,成为系统级资源。
独立激光器玩家SIVEF正处在这个变化的一个关键节点。
一、SIVEF做什么
公司核心是基于InP平台的WDM DFB laser array。
简单说:
DFB:稳定单波长激光器
WDM:多波长复用
array:多激光器一体化
本质不是卖“激光器”,而是提供多通道光带宽能力。
在CPO + ELS架构下:
传统:每个模块一个激光器
新架构:一个光源供多个通道
激光器从“分布式组件”变成“集中资源”,这就是价值重分配的起点。
二、为什么是WDM DFB array
AI数据中心的约束很清晰:单通道速率接近极限,电互连功耗不可扩展,带宽必须靠“并行化”
唯一可扩展路径是:
多波长(WDM)
而WDM的前提是:稳定、可控的单波长光源(DFB)
因此,WDM DFB array是当前工程上最优解。尽管不是最先进的理论方案,但它是唯一可规模化落地的方案。
三、SIVEF的优势本质
SIVEF的优势不在“技术独占
AI算力的瓶颈正在从计算转向带宽。随着GPU规模扩大,节点间通信接近N²增长,电互连在功耗与距离上触顶,光互连从“可选项”变成“刚需”。
在这一过程中,CPO(Co-Packaged Optics)与ELS(External Laser Source)开始重构产业链:激光器从模块内部被剥离,成为系统级资源。
独立激光器玩家SIVEF正处在这个变化的一个关键节点。
一、SIVEF做什么
公司核心是基于InP平台的WDM DFB laser array。
简单说:
DFB:稳定单波长激光器
WDM:多波长复用
array:多激光器一体化
本质不是卖“激光器”,而是提供多通道光带宽能力。
在CPO + ELS架构下:
传统:每个模块一个激光器
新架构:一个光源供多个通道
激光器从“分布式组件”变成“集中资源”,这就是价值重分配的起点。
二、为什么是WDM DFB array
AI数据中心的约束很清晰:单通道速率接近极限,电互连功耗不可扩展,带宽必须靠“并行化”
唯一可扩展路径是:
多波长(WDM)
而WDM的前提是:稳定、可控的单波长光源(DFB)
因此,WDM DFB array是当前工程上最优解。尽管不是最先进的理论方案,但它是唯一可规模化落地的方案。
三、SIVEF的优势本质
SIVEF的优势不在“技术独占
- 赞赏
- 点赞
- 评论
- 转发
- 分享
看了一下,现在不少美股知名大v喊单的小票,纯叙事啊
我的一阶思维:价值投资,赌博不参与
我的二阶思维:作为币圈土狗玩家,必须无脑梭哈🤣
我的一阶思维:价值投资,赌博不参与
我的二阶思维:作为币圈土狗玩家,必须无脑梭哈🤣
- 赞赏
- 点赞
- 评论
- 转发
- 分享
moonshots频道今天一个观点:
ai会让科斯定律失效
醍醐灌顶!
组织的存在,最重要原因之一是因为组织内协调成本低于市场交易成本
当ai让交易成本降幅远超组织成本降幅的时候,组织存在的意义就大大降低了
对公司来说是这样,对国家来说也是。
ai会让科斯定律失效
醍醐灌顶!
组织的存在,最重要原因之一是因为组织内协调成本低于市场交易成本
当ai让交易成本降幅远超组织成本降幅的时候,组织存在的意义就大大降低了
对公司来说是这样,对国家来说也是。
- 赞赏
- 1
- 1
- 转发
- 分享
ybaser:
只管向前冲 👊只管向前冲 👊所有知识(脑力)工作者,都会被ai替代
包括科研
因为,research = 信息处理 + 假设生成 + 验证。
ai各个部分都比人强,而且还在快速变得更强。
就算真正的天才级别的“灵光一现”比方说广义相对论的发现,可能是最难被替代的,但这类科研占比极少。
尽管如此,广义相对论是不是也相当于是人脑里LLM的极致的泛化?
包括科研
因为,research = 信息处理 + 假设生成 + 验证。
ai各个部分都比人强,而且还在快速变得更强。
就算真正的天才级别的“灵光一现”比方说广义相对论的发现,可能是最难被替代的,但这类科研占比极少。
尽管如此,广义相对论是不是也相当于是人脑里LLM的极致的泛化?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
新记录!20万人口规模城市级别的15年超长期电力合同将给ai数据中心上下游带来哪些影响?
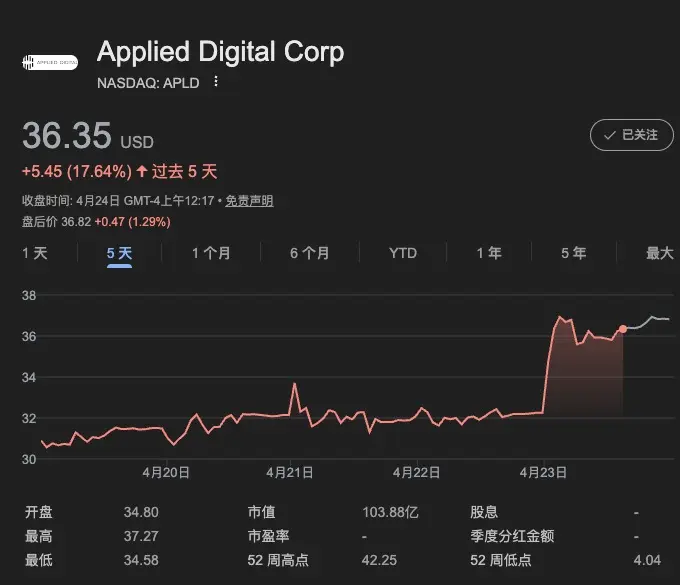
Applied Digital Corporation(apld) 今天宣布与一家美国投资级 hyperscaler 签下了一份 300MW、15年期、总额约75亿美元的长约。
股价应声大涨近20%。
300MW的规模已经接近20万人口城市级负载,15年的期限明显超出传统数据中心合同;而按容量锁定的模式,也不同于按GPU或按小时计费的算力租赁。
这在“超大规模 + 超长周期 + 明确算力用途”的基础设施级AI合同上,创了新的记录。
这背后对应的是行业属性的变化。截止目前的数据中心,本质是还是IT服务,尽管之前有一些长达5年的合同,但扩容仍按需进行,资源可以迁移和替换;
而现在则逐步变成基础设施资产,开始用类似电力PPA或能源的15年的长期合同的方式锁定供给。
算力不再是可以随时采购的资源,而是需要提前规划、提前占位的生产能力。
为什么会发生这种变化,本质原因是资源开始稀缺,和储存,芯片,光模块一样,对hyperscaler来说,如果不提前锁定,未来可能根本拿不到资源。
在接下来的演进中,电力资产会被重新定价,甚至重新定义。
有电,有接入能力,和高达100–300MW甚至GW级别的电力扩展能力,同时具备网络连接条件和开发可行性,都将成为新资产定价的属性。
归根结底,这一切指向同一个变化:AI竞争
Applied Digital Corporation(apld) 今天宣布与一家美国投资级 hyperscaler 签下了一份 300MW、15年期、总额约75亿美元的长约。
股价应声大涨近20%。
300MW的规模已经接近20万人口城市级负载,15年的期限明显超出传统数据中心合同;而按容量锁定的模式,也不同于按GPU或按小时计费的算力租赁。
这在“超大规模 + 超长周期 + 明确算力用途”的基础设施级AI合同上,创了新的记录。
这背后对应的是行业属性的变化。截止目前的数据中心,本质是还是IT服务,尽管之前有一些长达5年的合同,但扩容仍按需进行,资源可以迁移和替换;
而现在则逐步变成基础设施资产,开始用类似电力PPA或能源的15年的长期合同的方式锁定供给。
算力不再是可以随时采购的资源,而是需要提前规划、提前占位的生产能力。
为什么会发生这种变化,本质原因是资源开始稀缺,和储存,芯片,光模块一样,对hyperscaler来说,如果不提前锁定,未来可能根本拿不到资源。
在接下来的演进中,电力资产会被重新定价,甚至重新定义。
有电,有接入能力,和高达100–300MW甚至GW级别的电力扩展能力,同时具备网络连接条件和开发可行性,都将成为新资产定价的属性。
归根结底,这一切指向同一个变化:AI竞争
- 赞赏
- 点赞
- 评论
- 转发
- 分享
半导体封装的“隐形中枢”:inline检测与OSAT的再定价
半导体产业正在经历一次重心转移:性能提升不再只依赖晶体管缩小,而是越来越依赖封装。2.5D、3D、HBM、chiplet,本质上都在把“系统能力”搬到封装环节。这也直接抬高了OSAT(外包封装与测试)的战略地位。
封装重要性的提升,带来了inline检测的快速增长。
OSAT(Outsourced Semiconductor Assembly and Test)负责两件事:
把裸die封装成可用芯片(封装)
验证芯片是否可用(测试)
过去这是一个低技术、低毛利的环节。但在AI时代,情况变了:
多die集成(chiplet)
HBM堆叠
nm级对准要求(hybrid bonding)
封装正在变成:
性能瓶颈 + 良率瓶颈 + 成本瓶颈
inline是一种生产方式:所有工序连续完成,并在生产过程中实时检测与反馈(闭环)
对应另外一个环节是offline:做完再测(开环)
先进封装中的inline检测主要分三类:
1)光学检测(主力)
bump高度
overlay(对准)
表面缺陷
特点:速度快,可全量inline。
2)X-ray检测
焊点空洞
TSV缺陷
内部结构问题
特点:能看内部,但速度慢,多用于抽检。
3)电性测试
功能验证
性能分档
更接近最终测试,不属于核心inline控制体系。
inline检测的目标不是“最
半导体产业正在经历一次重心转移:性能提升不再只依赖晶体管缩小,而是越来越依赖封装。2.5D、3D、HBM、chiplet,本质上都在把“系统能力”搬到封装环节。这也直接抬高了OSAT(外包封装与测试)的战略地位。
封装重要性的提升,带来了inline检测的快速增长。
OSAT(Outsourced Semiconductor Assembly and Test)负责两件事:
把裸die封装成可用芯片(封装)
验证芯片是否可用(测试)
过去这是一个低技术、低毛利的环节。但在AI时代,情况变了:
多die集成(chiplet)
HBM堆叠
nm级对准要求(hybrid bonding)
封装正在变成:
性能瓶颈 + 良率瓶颈 + 成本瓶颈
inline是一种生产方式:所有工序连续完成,并在生产过程中实时检测与反馈(闭环)
对应另外一个环节是offline:做完再测(开环)
先进封装中的inline检测主要分三类:
1)光学检测(主力)
bump高度
overlay(对准)
表面缺陷
特点:速度快,可全量inline。
2)X-ray检测
焊点空洞
TSV缺陷
内部结构问题
特点:能看内部,但速度慢,多用于抽检。
3)电性测试
功能验证
性能分档
更接近最终测试,不属于核心inline控制体系。
inline检测的目标不是“最
- 赞赏
- 1
- 1
- 转发
- 分享
ybaser:
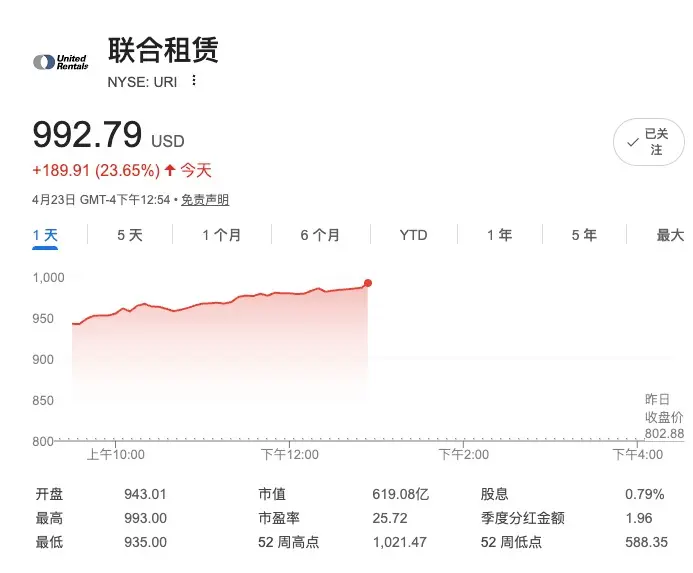
只需充电即可完成 👊United Rentals (URI),昨天财报,今天大涨超20%!
这是个在aidc疯狂竞逐算力的大周期里,市场忽略的支撑这些庞然大物落地的“重型后勤”。
1. 业绩摘要:创纪录,上调指引
URI 在本季度交出了满分答卷:
营收与盈利: 总营收 39.85 亿美元,调整后 EPS 达 $9.71。
核心效率: 租赁利润率在排除特殊因素后持续走高,车队生产力增长 2.3%。
股东回报: 季度内通过回购和派息返还 5 亿美元,现金流极度充沛。最关键的信号是,管理层基于“大型项目势头”上调了全年业绩指引,显示出极强的增长信心。
2. 商业模式:从“租挖掘机”到“系统方案”
URI 的业务由两部分驱动:
通用租赁: 覆盖建筑和工业的基础设备(高空平台、土方机械等)。
专业租赁: 提供电力配套(大型发电机)、精密温控(工业 HVAC)及流体处理。这种“一站式”模式让它成为了大型工程不可替代的合作伙伴。
3. AIDC:URI 增长的“秘密燃料”
为什么 AIDC 建设对 URI 如此重要?
重度依赖电力与温控: AIDC 的建设和测试阶段对移动电力和工业冷水机组有爆发式需求,这正是 URI 高毛利的专业租赁领域。
长周期与高粘性: 数据中心属于“超大型项目(Mega Projects)”,建设周期长、设备占用率高。
行业风向标: URI 约 25% 的收入来自这类大型项目。只要 AIDC
这是个在aidc疯狂竞逐算力的大周期里,市场忽略的支撑这些庞然大物落地的“重型后勤”。
1. 业绩摘要:创纪录,上调指引
URI 在本季度交出了满分答卷:
营收与盈利: 总营收 39.85 亿美元,调整后 EPS 达 $9.71。
核心效率: 租赁利润率在排除特殊因素后持续走高,车队生产力增长 2.3%。
股东回报: 季度内通过回购和派息返还 5 亿美元,现金流极度充沛。最关键的信号是,管理层基于“大型项目势头”上调了全年业绩指引,显示出极强的增长信心。
2. 商业模式:从“租挖掘机”到“系统方案”
URI 的业务由两部分驱动:
通用租赁: 覆盖建筑和工业的基础设备(高空平台、土方机械等)。
专业租赁: 提供电力配套(大型发电机)、精密温控(工业 HVAC)及流体处理。这种“一站式”模式让它成为了大型工程不可替代的合作伙伴。
3. AIDC:URI 增长的“秘密燃料”
为什么 AIDC 建设对 URI 如此重要?
重度依赖电力与温控: AIDC 的建设和测试阶段对移动电力和工业冷水机组有爆发式需求,这正是 URI 高毛利的专业租赁领域。
长周期与高粘性: 数据中心属于“超大型项目(Mega Projects)”,建设周期长、设备占用率高。
行业风向标: URI 约 25% 的收入来自这类大型项目。只要 AIDC
- 赞赏
- 点赞
- 评论
- 转发
- 分享
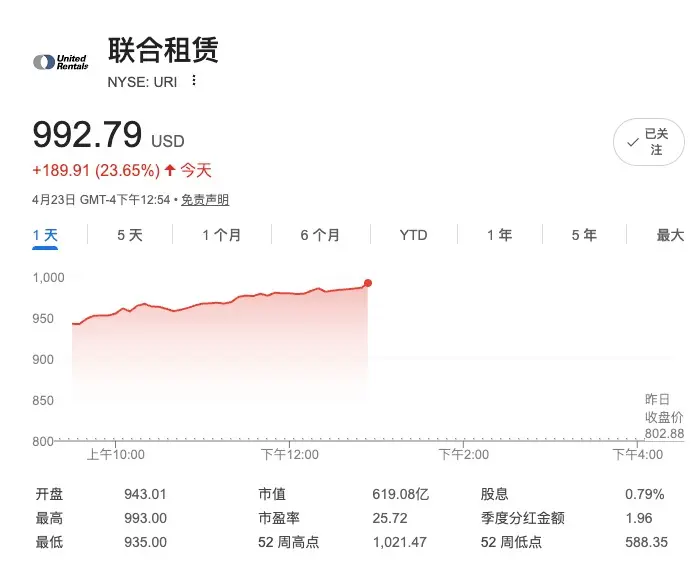
United Rentals (URI),昨天财报,今天大涨超20%!
这是个在aidc疯狂竞逐算力的大周期里,市场忽略的支撑这些庞然大物落地的“重型后勤”。
1. 业绩摘要:创纪录,上调指引
URI 在本季度交出了满分答卷:
营收与盈利: 总营收 39.85 亿美元,调整后 EPS 达 $9.71。
核心效率: 租赁利润率在排除特殊因素后持续走高,车队生产力增长 2.3%。
股东回报: 季度内通过回购和派息返还 5 亿美元,现金流极度充沛。最关键的信号是,管理层基于“大型项目势头”上调了全年业绩指引,显示出极强的增长信心。
2. 商业模式:从“租挖掘机”到“系统方案”
URI 的业务由两部分驱动:
通用租赁: 覆盖建筑和工业的基础设备(高空平台、土方机械等)。
专业租赁: 提供电力配套(大型发电机)、精密温控(工业 HVAC)及流体处理。这种“一站式”模式让它成为了大型工程不可替代的合作伙伴。
3. AIDC:URI 增长的“秘密燃料”
为什么 AIDC 建设对 URI 如此重要?
重度依赖电力与温控: AIDC 的建设和测试阶段对移动电力和工业冷水机组有爆发式需求,这正是 URI 高毛利的专业租赁领域。
长周期与高粘性: 数据中心属于“超大型项目(Mega Projects)”,建设周期长、设备占用率高。
行业风向标: URI 约 25% 的收入来自这类大型项目。只要 AIDC
这是个在aidc疯狂竞逐算力的大周期里,市场忽略的支撑这些庞然大物落地的“重型后勤”。
1. 业绩摘要:创纪录,上调指引
URI 在本季度交出了满分答卷:
营收与盈利: 总营收 39.85 亿美元,调整后 EPS 达 $9.71。
核心效率: 租赁利润率在排除特殊因素后持续走高,车队生产力增长 2.3%。
股东回报: 季度内通过回购和派息返还 5 亿美元,现金流极度充沛。最关键的信号是,管理层基于“大型项目势头”上调了全年业绩指引,显示出极强的增长信心。
2. 商业模式:从“租挖掘机”到“系统方案”
URI 的业务由两部分驱动:
通用租赁: 覆盖建筑和工业的基础设备(高空平台、土方机械等)。
专业租赁: 提供电力配套(大型发电机)、精密温控(工业 HVAC)及流体处理。这种“一站式”模式让它成为了大型工程不可替代的合作伙伴。
3. AIDC:URI 增长的“秘密燃料”
为什么 AIDC 建设对 URI 如此重要?
重度依赖电力与温控: AIDC 的建设和测试阶段对移动电力和工业冷水机组有爆发式需求,这正是 URI 高毛利的专业租赁领域。
长周期与高粘性: 数据中心属于“超大型项目(Mega Projects)”,建设周期长、设备占用率高。
行业风向标: URI 约 25% 的收入来自这类大型项目。只要 AIDC
- 赞赏
- 1
- 1
- 转发
- 分享
HighAmbition:
钻石手 💎德州仪器($TXN)第一季度财报,全面超预期:
每股收益(EPS):1.68美元(预期1.38美元)
营收:48.3亿美元(预期45.3亿美元)
营业利润:18.1亿美元(预期15.4亿美元)
自由现金流:14.0亿美元(预期12.0亿美元)
资本支出(CapEx):6.76亿美元(预期6.899亿美元)
模拟芯片收入:39.2亿美元(预期36.8亿美元)
业绩指引(Q2):
预计每股收益(EPS):1.77–2.05美元
预计营收:50.0亿–54.0亿美元
连最关键的模拟业务也明显好于市场此前的悲观判断。
财报释放了三个更重要的信号。
第一,模拟芯片行业的库存周期已经接近结束,整个板块有被重新估值的基础。
第二,工业需求比市场预期更强,全球制造并没有想象中那么疲弱。
第三,TXN在周期底部依然维持较强盈利能力,说明它不是简单的周期公司,而是具备结构性优势的长期赢家。
在这次AI周期中,需求传导路径是从算力延伸到电源、再到模拟和功率器件。
TXN正处在这条链条的中下游。当AI投资持续扩大时,这部分需求会逐步显现出来,而且往往滞后但更稳定。
免责声明:本人持有文章提及股票,观点充满偏见,非投资建议dyor
每股收益(EPS):1.68美元(预期1.38美元)
营收:48.3亿美元(预期45.3亿美元)
营业利润:18.1亿美元(预期15.4亿美元)
自由现金流:14.0亿美元(预期12.0亿美元)
资本支出(CapEx):6.76亿美元(预期6.899亿美元)
模拟芯片收入:39.2亿美元(预期36.8亿美元)
业绩指引(Q2):
预计每股收益(EPS):1.77–2.05美元
预计营收:50.0亿–54.0亿美元
连最关键的模拟业务也明显好于市场此前的悲观判断。
财报释放了三个更重要的信号。
第一,模拟芯片行业的库存周期已经接近结束,整个板块有被重新估值的基础。
第二,工业需求比市场预期更强,全球制造并没有想象中那么疲弱。
第三,TXN在周期底部依然维持较强盈利能力,说明它不是简单的周期公司,而是具备结构性优势的长期赢家。
在这次AI周期中,需求传导路径是从算力延伸到电源、再到模拟和功率器件。
TXN正处在这条链条的中下游。当AI投资持续扩大时,这部分需求会逐步显现出来,而且往往滞后但更稳定。
免责声明:本人持有文章提及股票,观点充满偏见,非投资建议dyor
- 赞赏
- 1
- 评论
- 转发
- 分享
lam research财报前瞻
LRCX马上要发的财报的重点,其实是关于LRCX在AI周期里到底处在什么位置,以及它的变化会如何传导到整个产业链。
LRCX不是一个简单的设备公司,而是一个典型的工艺复杂度受益者。
AI带来的变化,并不只是算力需求增加,而是芯片制造过程本身的复杂度在快速上升:HBM堆叠层数提升、TSV深孔刻蚀难度提升、3D NAND层数逼近物理极限、2nm/GAA结构三维化。这些变化的共同结果,是单位晶圆需要的刻蚀和沉积步骤显著增加,且难度更高。
这意味着,LRCX的增长逻辑并不完全依赖“产能扩张”,而是更多来自“工艺密度提升”。
因此,财报是否超预期其实不是最关键的,关键是预期差来自哪里。影响财报结果的核心变量可以归纳为五个:预期是否已经被上调、订单是否顺利转化为收入、收入结构是否来自AI/先进封装、服务业务是否稳定、以及管理层指引是否保守。
但股价反应的逻辑未必和财报完全趋同。市场交易的不是结果,而是偏差。真正驱动股价的,是四件事:是否超出buy-side预期、指引是否上修、增长是否来自AI等高质量需求,以及毛利率是否稳定。在当前阶段,毛利率的重要性甚至高于收入,因为市场已经默认需求很强,但对“增长质量”更敏感。
因此,即便财报大概率超预期,股价也未必上涨。
就供给侧来说,LRCX未来并不会像ASML那样出现长期产能受限。刻蚀和沉积设备本身是可扩产的,公司也在
LRCX马上要发的财报的重点,其实是关于LRCX在AI周期里到底处在什么位置,以及它的变化会如何传导到整个产业链。
LRCX不是一个简单的设备公司,而是一个典型的工艺复杂度受益者。
AI带来的变化,并不只是算力需求增加,而是芯片制造过程本身的复杂度在快速上升:HBM堆叠层数提升、TSV深孔刻蚀难度提升、3D NAND层数逼近物理极限、2nm/GAA结构三维化。这些变化的共同结果,是单位晶圆需要的刻蚀和沉积步骤显著增加,且难度更高。
这意味着,LRCX的增长逻辑并不完全依赖“产能扩张”,而是更多来自“工艺密度提升”。
因此,财报是否超预期其实不是最关键的,关键是预期差来自哪里。影响财报结果的核心变量可以归纳为五个:预期是否已经被上调、订单是否顺利转化为收入、收入结构是否来自AI/先进封装、服务业务是否稳定、以及管理层指引是否保守。
但股价反应的逻辑未必和财报完全趋同。市场交易的不是结果,而是偏差。真正驱动股价的,是四件事:是否超出buy-side预期、指引是否上修、增长是否来自AI等高质量需求,以及毛利率是否稳定。在当前阶段,毛利率的重要性甚至高于收入,因为市场已经默认需求很强,但对“增长质量”更敏感。
因此,即便财报大概率超预期,股价也未必上涨。
就供给侧来说,LRCX未来并不会像ASML那样出现长期产能受限。刻蚀和沉积设备本身是可扩产的,公司也在

- 赞赏
- 1
- 1
- 转发
- 分享
HighAmbition:
多头市场正处于巅峰 🐂凯文沃什国会听证讲话很鹰吗?
“货币政策的独立性至关重要。决策必须以国家利益为导向,建立在严谨分析、充分讨论和清晰判断之上。”
我觉得中规中矩啊,不然他还能怎么说?
不表态维持联储独立性,他能获得国会通过吗?
“货币政策的独立性至关重要。决策必须以国家利益为导向,建立在严谨分析、充分讨论和清晰判断之上。”
我觉得中规中矩啊,不然他还能怎么说?
不表态维持联储独立性,他能获得国会通过吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
训练不足推理补
推理不足代理补
代理复杂约束补
约束麻烦大家补
所以,加速计算是智能,通用计算也是
在通往agi的路上,存储,gpu,cpu都会被榨干,都会严重短缺
推理不足代理补
代理复杂约束补
约束麻烦大家补
所以,加速计算是智能,通用计算也是
在通往agi的路上,存储,gpu,cpu都会被榨干,都会严重短缺
- 赞赏
- 点赞
- 评论
- 转发
- 分享
harness,我最喜欢的翻译是
约束
所以harness engjneer
应该叫做
约束工程
约束
所以harness engjneer
应该叫做
约束工程
- 赞赏
- 点赞
- 评论
- 转发
- 分享
BWX Technologies 最近宣布收购 Precision Components Group,这是一次产能扩张,新增的50万平方英尺厂房和400多名熟练工人,在核能需求重新启动的周期里,是能稳定交付的制造能力的保证。
核能正在进入一个新的上行周期。AI带来的电力需求增长,叠加政策推动的小型模块化反应堆(SMR)和能源结构转型,使核能重新成为“稳定基荷电源”。
供需缺口急剧拉大。尤其是在美国,本土核工业制造能力长期萎缩,具备认证、工艺和经验的生产体系极难复制。核级设备涉及严格的认证体系和极长的验证周期,不是资本投入就能快速扩出来的产能。
这使得行业的竞争逻辑发生变化。和之前的be逻辑类似,重要的是制造和按时交付。BWXT通过这次收购,把自身从“接单能力”进一步推向“交付能力”。
如果用类半导体产业链的视角去看,核能产业链也在逐渐出现类似“ASML / KLA”的角色。真正的核心在那些具备高认证、高复杂制造能力、且产能极难复制的供应层。
BWXT本身就是这一类公司,更接近“复杂度收费者”的角色。类似的还有 Curtiss-Wright,在泵、阀门和控制系统等关键部件上形成长期绑定,一旦进入供应链,生命周期可以锁定几十年。Chart Industries 则属于跨能源体系的设备提供商,类似更广义的“卖水人”。
相比之下,像 Westinghouse Electric Compan
核能正在进入一个新的上行周期。AI带来的电力需求增长,叠加政策推动的小型模块化反应堆(SMR)和能源结构转型,使核能重新成为“稳定基荷电源”。
供需缺口急剧拉大。尤其是在美国,本土核工业制造能力长期萎缩,具备认证、工艺和经验的生产体系极难复制。核级设备涉及严格的认证体系和极长的验证周期,不是资本投入就能快速扩出来的产能。
这使得行业的竞争逻辑发生变化。和之前的be逻辑类似,重要的是制造和按时交付。BWXT通过这次收购,把自身从“接单能力”进一步推向“交付能力”。
如果用类半导体产业链的视角去看,核能产业链也在逐渐出现类似“ASML / KLA”的角色。真正的核心在那些具备高认证、高复杂制造能力、且产能极难复制的供应层。
BWXT本身就是这一类公司,更接近“复杂度收费者”的角色。类似的还有 Curtiss-Wright,在泵、阀门和控制系统等关键部件上形成长期绑定,一旦进入供应链,生命周期可以锁定几十年。Chart Industries 则属于跨能源体系的设备提供商,类似更广义的“卖水人”。
相比之下,像 Westinghouse Electric Compan

- 赞赏
- 点赞
- 评论
- 转发
- 分享
我的claude opus 4.7了
大家应该都用上了?
大家应该都用上了?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
模型即应用,算力即模型,刹那即永恒
—- mythos发布观感
经过过去几年,从提示词MCP、工作流skill到harness engineering的不断迭代,市场应该已经基本认识到,
模型即应用。
接下来,随着拥有足够多算力的模型公司迭代速度越来越快,市场会慢慢意识到,
算力即模型,
随着methos的发布,以及拥有算力优势的头部模型将领先优势不断拉大,让一时的领先变成无法超越的加速度,最终,
刹那即永恒
—- mythos发布观感
经过过去几年,从提示词MCP、工作流skill到harness engineering的不断迭代,市场应该已经基本认识到,
模型即应用。
接下来,随着拥有足够多算力的模型公司迭代速度越来越快,市场会慢慢意识到,
算力即模型,
随着methos的发布,以及拥有算力优势的头部模型将领先优势不断拉大,让一时的领先变成无法超越的加速度,最终,
刹那即永恒
- 赞赏
- 2
- 评论
- 转发
- 分享
模型即应用,算力即模型,刹那即永恒
—- mythos发布观感
经过过去几年,从提示词MCP、工作流skill到harness engineering的不断迭代,市场应该已经基本认识到,
模型即应用。
接下来,随着拥有多足算力的模型公司迭代速度越来越快,市场会慢慢意识到,
算力即模型,
随着methos的发布,以及拥有算力优势的头部模型将领先优势不断拉大,让一时的领先变成无法超越的加速度,最终,
刹那即永恒
—- mythos发布观感
经过过去几年,从提示词MCP、工作流skill到harness engineering的不断迭代,市场应该已经基本认识到,
模型即应用。
接下来,随着拥有多足算力的模型公司迭代速度越来越快,市场会慢慢意识到,
算力即模型,
随着methos的发布,以及拥有算力优势的头部模型将领先优势不断拉大,让一时的领先变成无法超越的加速度,最终,
刹那即永恒
- 赞赏
- 1
- 评论
- 转发
- 分享
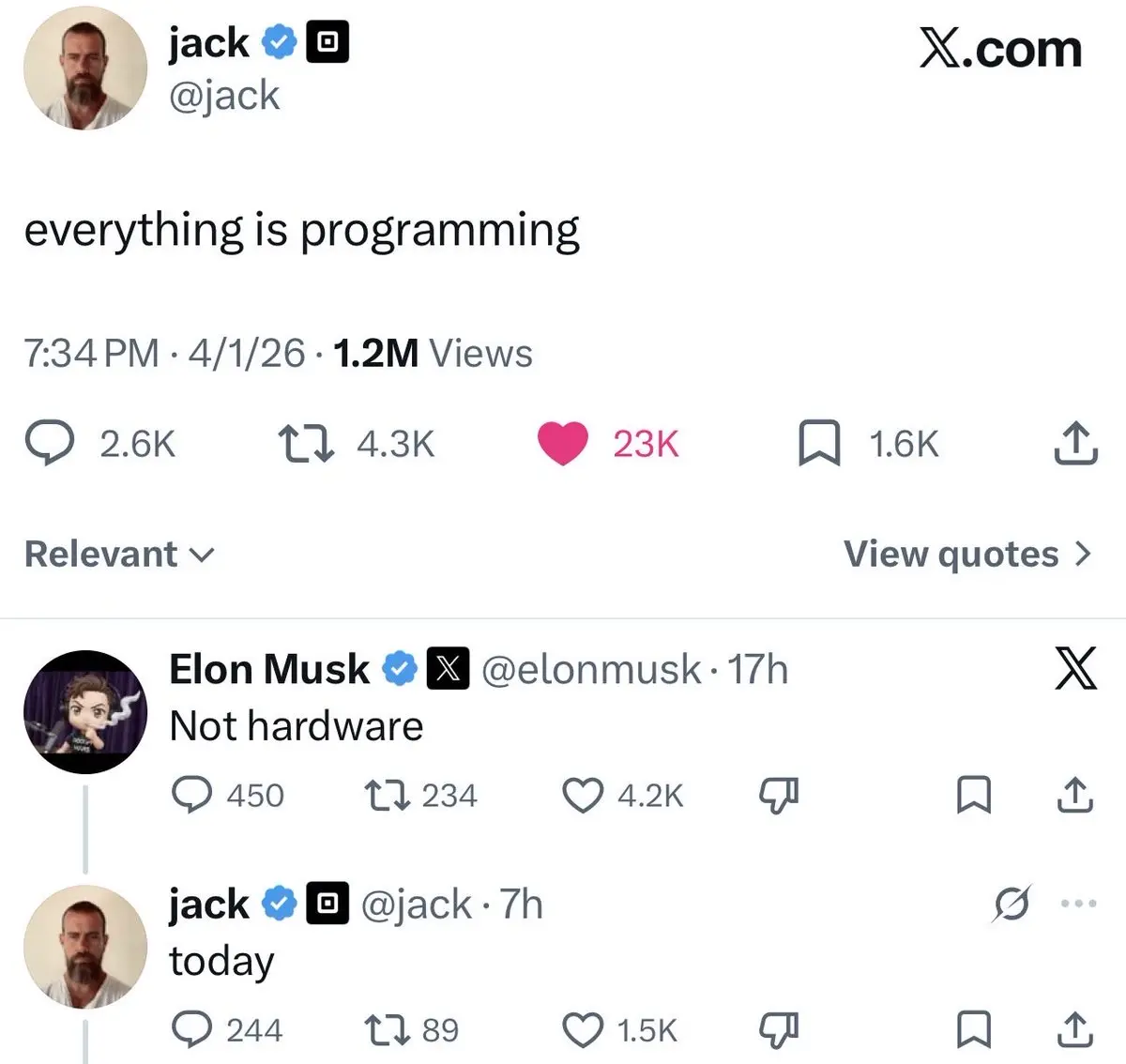
之前俄乌冲突就是民主党负责点燃乌克兰的战火,制造混乱,然后川普负责撤军,做撒手掌柜,让盟友买单。
这次伊朗估计时间太紧,川普把一套戏的两个角色全演了,直接又负责点火制造混乱,又负责撒手不管,让盟友买单。
这次伊朗估计时间太紧,川普把一套戏的两个角色全演了,直接又负责点火制造混乱,又负责撒手不管,让盟友买单。

- 赞赏
- 1
- 评论
- 转发
- 分享
热门话题
查看更多26.2万 热度
32.12万 热度
11.27万 热度
50.27万 热度
5.95万 热度
置顶
🔥 WCTC S8 全球交易赛正式开赛!
8,000,000 USDT 超级奖池解锁开启
🏆 团队赛:上半场正式开启,预报名阶段 5,500+ 战队现已集结
交易量收益额双重比拼,解锁上半场 1,800,000 USDT 奖池
🏆 个人赛:现货、合约、TradFi、ETF、闪兑、跟单齐上阵
全场交易量比拼,瓜分 2,000,000 USDT 奖池
🏆 王者 PK 赛:零门槛参与,实时匹配享受战斗快感
收益率即时 PK,瓜分 1,600,000 USDT 奖池
活动时间:2026 年 4月 23 日 16:00:00 -2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即参与:https://www.gate.com/competition/wctc-s8
#WCTCS8🎁 积分换豪礼!成长值第 1️⃣ 8️⃣ 期社区抽奖狂欢开启!
新老用户 100% 中奖,完成日常任务即可参与抽奖!
👉 https://www.gate.com/activities/pointprize?now_period=18
🌟 如何参与?
1️⃣ 进入【广场】个人主页,点击头像旁积分标识进入【社区中心】
2️⃣ 完成发帖、评论、点赞、发言等广场或热聊任务赚取成长值
🎁 每满 300 积分即可抽奖 1 次,MacBook Air M5、Gate 13 周年礼盒、VIP 体验卡等您来拿!
🔥 本期门槛再降低:仅需完成 20U 现货交易,即可获得发奖资格!
详情 👉 https://www.gate.com/announcements/article/5085410,000 USDT 悬赏,寻找跟单金牌星探!🕵️
挖掘顶级带单员,赢取高额跟单体验金!
立即参与:https://www.gate.com/campaigns/4624
🎁 三大活动,奖金叠满:
1️⃣ 慧眼识英:发帖推荐带单员,分享跟单体验,抽 100 位送 30 USDT!
2️⃣ 强力应援:晒出你的跟单截图,为大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交达人:同步至 X/Twitter,凭流量赢取 100 USDT!
📍 标签: #跟单金牌星探 #GateCopyTrading
⏰ 限时: 4/22 16:00 - 5/10 16:00 (UTC+8)
详情:https://www.gate.com/announcements/article/50848十三载风雨同行,您是 Gate 最珍贵的见证者。分享您的故事,瓜分重磅周年豪礼!
参与方式
1️⃣ 带 #Gate13周年 和相应主题标签,在 13 周年留言板或广场发帖
2️⃣ 分享您与 Gate 的故事、送上祝福,或畅想未来 13 年
13 周年定制礼盒、红牛模型、大额仓位体验券等您来拿!
13周年庆留言板 👉️ https://www.gate.com/activities/13th-anniversary
Gate 广场 👉️ https://www.gate.com/post
13 年成长,感谢有您。您的故事,我们期待聆听!
详情:https://www.gate.com/announcements/article/50694