Adsrekt
現在、コンテンツはありません
Adsrekt
Codexの動作が今日悪いです
GPT 5.4がサーバーをオーバーロードしています
私だけこの問題を抱えているのでしょうか?
原文表示GPT 5.4がサーバーをオーバーロードしています
私だけこの問題を抱えているのでしょうか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
誰かがApple Watchで動作する音声モデルを作った。
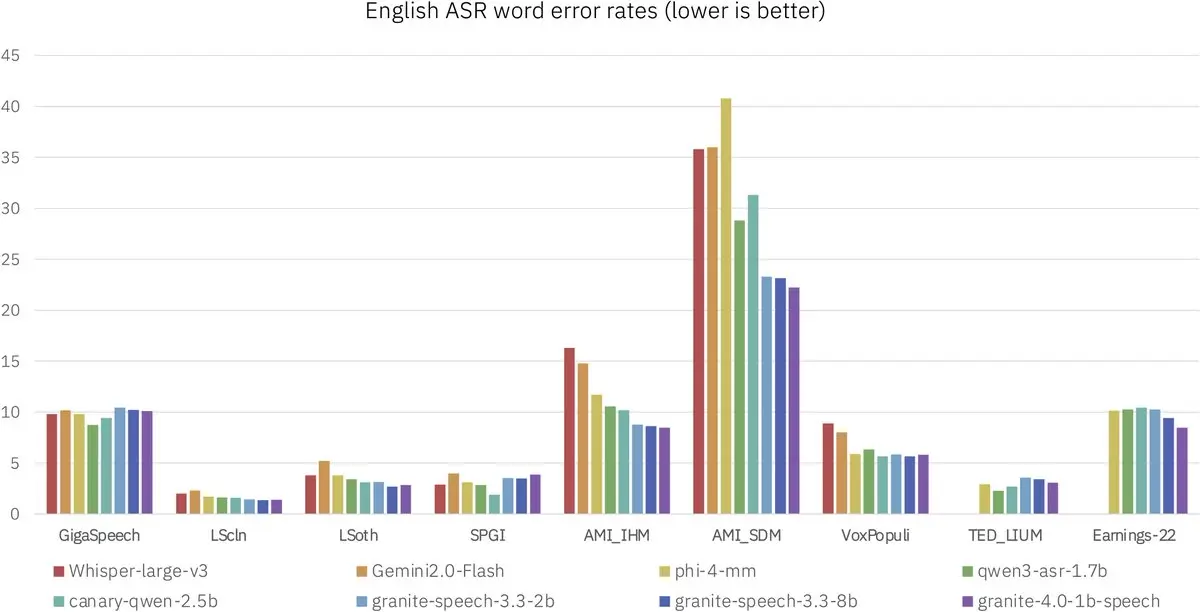
おもちゃのデモではない。granite 4.0 1Bの音声モデルは、OpenASRのリーダーボードで見事に1位にランクインした。
これのすごいところは:
• 1Bパラメータ - granite 3.3 2Bの半分のサイズ
• より大きなモデルよりも高い英語の文字起こし精度
• 小型ハードウェア上での高速推論のための推測デコード
• 6言語 - 英語、フランス語、ドイツ語、スペイン語、ポルトガル語、日本語
• キーワードリストのバイアス調整により、名前や頭字語も正確に認識
誰も話していない部分:
あなたは毎月Whisper API呼び出しにお金を払っている一方で、前モデルの半分のサイズのモデルが、あなたの手首に装着されたデバイス上でそれを上回る性能を発揮している。
それは小さな最適化ではない。エッジ音声アプリのコスト構造全体が崩壊しているのだ。
小型モデル。より高い精度。クラウド依存ゼロ。
原文表示おもちゃのデモではない。granite 4.0 1Bの音声モデルは、OpenASRのリーダーボードで見事に1位にランクインした。
これのすごいところは:
• 1Bパラメータ - granite 3.3 2Bの半分のサイズ
• より大きなモデルよりも高い英語の文字起こし精度
• 小型ハードウェア上での高速推論のための推測デコード
• 6言語 - 英語、フランス語、ドイツ語、スペイン語、ポルトガル語、日本語
• キーワードリストのバイアス調整により、名前や頭字語も正確に認識
誰も話していない部分:
あなたは毎月Whisper API呼び出しにお金を払っている一方で、前モデルの半分のサイズのモデルが、あなたの手首に装着されたデバイス上でそれを上回る性能を発揮している。
それは小さな最適化ではない。エッジ音声アプリのコスト構造全体が崩壊しているのだ。
小型モデル。より高い精度。クラウド依存ゼロ。
- 報酬
- 2
- コメント
- リポスト
- 共有
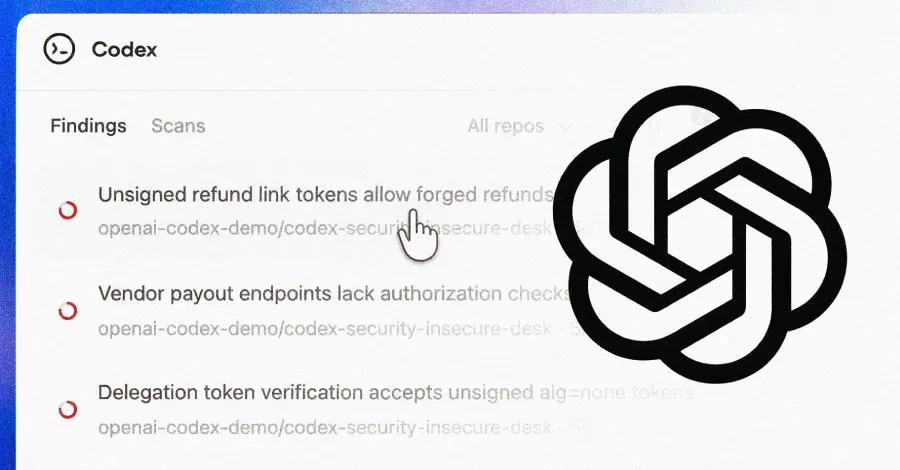
openaiは30日間で120万コミットをスキャン
その中で10,561件の高重大度バグを発見。うち792件はクリティカル。
あなたが今依存しているかもしれないプロジェクトで
openssh。gnutls。chromium。libssh。PHP。
これらは趣味のリポジトリではありません。これらはあなたの全スタックが依存している基盤です。そして、人間はこれらの問題を何年も見逃してきました。
codexセキュリティは、単にリントツールのパニックのようなノイズをフラグ付けするだけではありません。プロジェクト全体のコンテキストを構築し、発見を検証し、実際の修正案を提案します。
これが、「4000件の警告を無視する」ことと、「opensshの特定の関数が攻撃者に何かをさせることを許す」ことの違いです。
次の1ヶ月間、ChatGPT Pro/Enterprise/Businessは無料です。研究プレビュー段階です。
正直な質問ですが、あなたは現在のCIパイプラインが、エージェントが見つけたOPENSSH内の問題を本当に検知できると信じていますか?
原文表示その中で10,561件の高重大度バグを発見。うち792件はクリティカル。
あなたが今依存しているかもしれないプロジェクトで
openssh。gnutls。chromium。libssh。PHP。
これらは趣味のリポジトリではありません。これらはあなたの全スタックが依存している基盤です。そして、人間はこれらの問題を何年も見逃してきました。
codexセキュリティは、単にリントツールのパニックのようなノイズをフラグ付けするだけではありません。プロジェクト全体のコンテキストを構築し、発見を検証し、実際の修正案を提案します。
これが、「4000件の警告を無視する」ことと、「opensshの特定の関数が攻撃者に何かをさせることを許す」ことの違いです。
次の1ヶ月間、ChatGPT Pro/Enterprise/Businessは無料です。研究プレビュー段階です。
正直な質問ですが、あなたは現在のCIパイプラインが、エージェントが見つけたOPENSSH内の問題を本当に検知できると信じていますか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
あなたは5つの磨き上げられたデモを出荷しました。あなたにはZEROのユーザーがいます。製品自体が問題ではありませんでした。
問題はマーケティングです。
私はそれを知っています。なぜなら、私がfcksmmを作ったのは、何ヶ月も空白の作成ボックスを見つめながら、私のプロジェクトがほこりをかぶっている間に作ったからです。
> 「良いものを作れば人々は見つけてくれる」
これはパブリックに構築するコミュニティで最も高価な嘘です。良い製品は毎日静かに死んでいます。
マーケティングはパフォーマンスではありません。それは配信エンジニアリングです。あなたのデータベースや認証層と同じようにスタックの一部です。
エラー処理なしで出荷しないのと同じように、あなたが何を作ったのかを説明する投稿一つもなく出荷するのはなぜですか。
@fcksmm_はあなたの生のノートから書き方を学び、それをあなたの声のように聞こえる投稿に変えます。LinkedInのエネルギーでも、GPTの雑音でもありません。あなたの声です。
テンプレートでも、プロンプトチェーンでもありません。
原文表示問題はマーケティングです。
私はそれを知っています。なぜなら、私がfcksmmを作ったのは、何ヶ月も空白の作成ボックスを見つめながら、私のプロジェクトがほこりをかぶっている間に作ったからです。
> 「良いものを作れば人々は見つけてくれる」
これはパブリックに構築するコミュニティで最も高価な嘘です。良い製品は毎日静かに死んでいます。
マーケティングはパフォーマンスではありません。それは配信エンジニアリングです。あなたのデータベースや認証層と同じようにスタックの一部です。
エラー処理なしで出荷しないのと同じように、あなたが何を作ったのかを説明する投稿一つもなく出荷するのはなぜですか。
@fcksmm_はあなたの生のノートから書き方を学び、それをあなたの声のように聞こえる投稿に変えます。LinkedInのエネルギーでも、GPTの雑音でもありません。あなたの声です。
テンプレートでも、プロンプトチェーンでもありません。

- 報酬
- 1
- コメント
- リポスト
- 共有
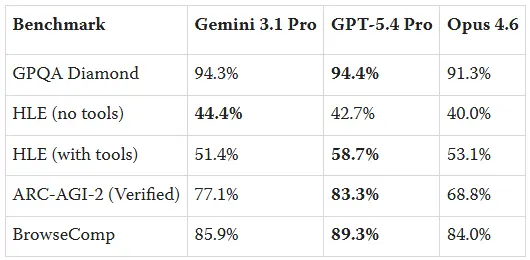
openaiはGPT-5.4 Proを安全性評価なしでリリースしました
システムカードも公開リスク評価もありません。何もありません。
これはおそらく、現在世界で最も優れたモデルであり、生物学的研究R&D、サイバー攻撃作戦の指揮、そして自律型コンピュータ利用において最適なものでありながら、まるでパッチノートのようにリリースされました
これが初めてではありません。GPT-5.2 Proも同じパターンをたどりました。静かなリリース、ドキュメントなし、外部レビューなし。彼らはこれを以前も行い、誰も責任を追及しなかったため、再び行ったのです
openaiは今や、huggingfaceの週末のファインチューンよりも透明性の低いフロンティアモデルを出荷しています
もしあなたが5.4 Proを基盤にしているか、敏感なドメインに触れるパイプラインで展開している場合、このものが実際に何をできるのかを完全に把握せずに運用していることになります。
原文表示システムカードも公開リスク評価もありません。何もありません。
これはおそらく、現在世界で最も優れたモデルであり、生物学的研究R&D、サイバー攻撃作戦の指揮、そして自律型コンピュータ利用において最適なものでありながら、まるでパッチノートのようにリリースされました
これが初めてではありません。GPT-5.2 Proも同じパターンをたどりました。静かなリリース、ドキュメントなし、外部レビューなし。彼らはこれを以前も行い、誰も責任を追及しなかったため、再び行ったのです
openaiは今や、huggingfaceの週末のファインチューンよりも透明性の低いフロンティアモデルを出荷しています
もしあなたが5.4 Proを基盤にしているか、敏感なドメインに触れるパイプラインで展開している場合、このものが実際に何をできるのかを完全に把握せずに運用していることになります。
- 報酬
- 1
- コメント
- リポスト
- 共有
GPT 5.4 TIPS
1百万のコンテキストウィンドウを有効にするのはやめてください。まだ準備ができていません。これはUXの演出であり、あなたのビルドを燃やしてしまいます
私は新しいモデルを自分の3つのプロジェクトで徹底的にテストしました。単なるバイブチェックではなく、実際の運用作業です
誰も教えてくれないことはこちらです:
抽象的なタスク理解能力が著しく向上しました。モデルはあなたが何をしようとしているのかを、すべてのステップを説明する前に理解します
しかし、その1百万のコンテキストウィンドウに皆が熱狂している?触らないでください。それは未完成です。コンテキストをプロジェクトフォルダやプロジェクト設定に入れてください。そこがモデルが実際に読む場所です
すべてのスキルを有効にしてください。すべてのツールを最大限に活用してください。フルアクセスがあるときとデフォルトの制限された状態では、モデルのパフォーマンスはまったく異なります
そしてxHighモード?それはトークンの炉です。標準モードで問題なく処理できる同じタスクを実行しているときに、バランスを破壊しているのを見ました
原文表示1百万のコンテキストウィンドウを有効にするのはやめてください。まだ準備ができていません。これはUXの演出であり、あなたのビルドを燃やしてしまいます
私は新しいモデルを自分の3つのプロジェクトで徹底的にテストしました。単なるバイブチェックではなく、実際の運用作業です
誰も教えてくれないことはこちらです:
抽象的なタスク理解能力が著しく向上しました。モデルはあなたが何をしようとしているのかを、すべてのステップを説明する前に理解します
しかし、その1百万のコンテキストウィンドウに皆が熱狂している?触らないでください。それは未完成です。コンテキストをプロジェクトフォルダやプロジェクト設定に入れてください。そこがモデルが実際に読む場所です
すべてのスキルを有効にしてください。すべてのツールを最大限に活用してください。フルアクセスがあるときとデフォルトの制限された状態では、モデルのパフォーマンスはまったく異なります
そしてxHighモード?それはトークンの炉です。標準モードで問題なく処理できる同じタスクを実行しているときに、バランスを破壊しているのを見ました

- 報酬
- 2
- コメント
- リポスト
- 共有
アイデアを作り込むのはやめて、GTMから始めよう。
今年は3つのツールをリリースした。$5k MRRに到達したものには共通点があった - コードを書き始める前にトラフィックの出所を知っていたことだ。
失敗したものはより良いアーキテクチャを持っていた。
今、あなたは磨き上げたデモを5つ持っているが、ユーザーはゼロ。MRRもゼロ。そして、エージェントループを微調整し続けているが、1つだけ質問をすべきだ - 最初の50人のユーザーはどこから来るのか。
あなたのアイデアでも、技術スタックでも、マルチエージェントフレームワークでもない。
あなたのスタートアップは流通にかかっている。
今すぐリソースの監査をしよう。すでに持っているものを見てみよう。あなたのXフォロワー、Discord、APIクレジット、ニッチなサブレディット、そして放棄した最後のプロジェクトのメールリスト。
それがあなたのGTMだ。それがあなたのスタートラインだ。
すでに到達できるチャネルに合ったものを作ろう。
原文表示今年は3つのツールをリリースした。$5k MRRに到達したものには共通点があった - コードを書き始める前にトラフィックの出所を知っていたことだ。
失敗したものはより良いアーキテクチャを持っていた。
今、あなたは磨き上げたデモを5つ持っているが、ユーザーはゼロ。MRRもゼロ。そして、エージェントループを微調整し続けているが、1つだけ質問をすべきだ - 最初の50人のユーザーはどこから来るのか。
あなたのアイデアでも、技術スタックでも、マルチエージェントフレームワークでもない。
あなたのスタートアップは流通にかかっている。
今すぐリソースの監査をしよう。すでに持っているものを見てみよう。あなたのXフォロワー、Discord、APIクレジット、ニッチなサブレディット、そして放棄した最後のプロジェクトのメールリスト。
それがあなたのGTMだ。それがあなたのスタートラインだ。
すでに到達できるチャネルに合ったものを作ろう。

- 報酬
- いいね
- コメント
- リポスト
- 共有
new gpt 5.4 feels amazing
>gpt 5.3 codexは彼女の行動を詳細に説明したが、最終的にひどいコードを生成した
>gpt 5.2は何も説明しなかったが、より良く動作した
>5.4 - これらの利点を組み合わせた
gpt 5.4 それとも Opus 4.6 ですか?
原文表示>gpt 5.3 codexは彼女の行動を詳細に説明したが、最終的にひどいコードを生成した
>gpt 5.2は何も説明しなかったが、より良く動作した
>5.4 - これらの利点を組み合わせた
gpt 5.4 それとも Opus 4.6 ですか?
- 報酬
- 1
- コメント
- リポスト
- 共有
gpt-5.4が登場し、80%のCOMPUTEはあなたの感情を傷つけないようにすることに使われ、残りの20%はどうやって推論するかを思い出すことに使われます
原文表示- 報酬
- 2
- コメント
- リポスト
- 共有
あなたのAIエージェントは現在完全なルートアクセス権を持っています
幻覚のコマンド一つで十分です
> sudo rm -rf /
それは理論上の話ではありません
エージェントループは、あなたが制御できないコンテキストウィンドウからシェルコマンドを生成します。モデルは悪意を持つ必要はありません。
ただ一度間違えば良いのです。
原文表示幻覚のコマンド一つで十分です
> sudo rm -rf /
それは理論上の話ではありません
エージェントループは、あなたが制御できないコンテキストウィンドウからシェルコマンドを生成します。モデルは悪意を持つ必要はありません。
ただ一度間違えば良いのです。

- 報酬
- 2
- コメント
- リポスト
- 共有
あなたの電話は、あなたの妻よりもあなたのことをよく知っている。
暗号で支払われた使い捨ての電話は、履歴も身元もなく、束縛もない。
本人確認のセルフィーも不要。銀行口座もリンクしない。深夜3時のどの取引所が召喚状を受け取ったかの不安もない。
原文表示暗号で支払われた使い捨ての電話は、履歴も身元もなく、束縛もない。
本人確認のセルフィーも不要。銀行口座もリンクしない。深夜3時のどの取引所が召喚状を受け取ったかの不安もない。

- 報酬
- 1
- コメント
- リポスト
- 共有
Pythonが「メモリを自動的に管理してくれる」という神話が、あなたのエージェントが稼働4時間でOOM(メモリ不足)になる原因です
先月、24のマルチエージェントを並列で実行し、1つのセッションの10倍のトークンを消費しながら、全く使い物にならない出力を出しました
本当の問題はトークンではなく、誰も監視していなかったメモリです
Pythonは参照カウントと循環ガベージコレクターを使用しています。問題は、C拡張を通じてnumpy配列をロードし、参照を適切に減らさない場合に起こります。これらのオブジェクトは一度も収集されません。放置され、増え続け、静かに蓄積します
長時間稼働しているエージェントが処理するたびに、もう一つのテンソル割り当てが発生し、それが解放されない可能性があります。それを24の同時セッションで掛けると、良い日でも1時間あたり400MBのリークになります
> もっとRAMを増やせ
そうすれば、tracemallocが10分で捕捉できたはずの問題に対して、月30,000ドルの計算コストがかかるだけです
原文表示先月、24のマルチエージェントを並列で実行し、1つのセッションの10倍のトークンを消費しながら、全く使い物にならない出力を出しました
本当の問題はトークンではなく、誰も監視していなかったメモリです
Pythonは参照カウントと循環ガベージコレクターを使用しています。問題は、C拡張を通じてnumpy配列をロードし、参照を適切に減らさない場合に起こります。これらのオブジェクトは一度も収集されません。放置され、増え続け、静かに蓄積します
長時間稼働しているエージェントが処理するたびに、もう一つのテンソル割り当てが発生し、それが解放されない可能性があります。それを24の同時セッションで掛けると、良い日でも1時間あたり400MBのリークになります
> もっとRAMを増やせ
そうすれば、tracemallocが10分で捕捉できたはずの問題に対して、月30,000ドルの計算コストがかかるだけです
- 報酬
- いいね
- コメント
- リポスト
- 共有
あなたのAIはブラックボックスであり、そのためにあなたの財布を圧迫します
機械的解釈性は、LLMを開けて内部の実際の回路をマッピングする方法です
雰囲気のテストではありません
「うまくいっているように見える」ではありません
実際のニューロンレベルでのトレーシングによるモデルの論理実装の追跡です
今、あなたのエンドポイントに到達するトラフィックの96%は、HTMLの生データを読むボットです
あなたのモデルは、監査できず、追跡できず、説明できない意思決定を行っています
そして、それに実資本の鍵を持たせているのです
企業のAI安全チームは、自分たちのモデルの仕組みを理解していません
彼らはそれをRLHFで包み込み、それを「整列」していると呼びます
それは安全性ではなく、マーケティングです
本当の課題はスケールです - 数十億のパラメータを持ち、私たちは今のところ小さな回路しか解釈できません
しかし、その小さな回路はすべてを教えてくれます
どのニューロンが価格データに反応するのか
どのニューロンがあなたのRAGコンテキストを完全に上書きするのか
原文表示機械的解釈性は、LLMを開けて内部の実際の回路をマッピングする方法です
雰囲気のテストではありません
「うまくいっているように見える」ではありません
実際のニューロンレベルでのトレーシングによるモデルの論理実装の追跡です
今、あなたのエンドポイントに到達するトラフィックの96%は、HTMLの生データを読むボットです
あなたのモデルは、監査できず、追跡できず、説明できない意思決定を行っています
そして、それに実資本の鍵を持たせているのです
企業のAI安全チームは、自分たちのモデルの仕組みを理解していません
彼らはそれをRLHFで包み込み、それを「整列」していると呼びます
それは安全性ではなく、マーケティングです
本当の課題はスケールです - 数十億のパラメータを持ち、私たちは今のところ小さな回路しか解釈できません
しかし、その小さな回路はすべてを教えてくれます
どのニューロンが価格データに反応するのか
どのニューロンがあなたのRAGコンテキストを完全に上書きするのか

- 報酬
- 1
- コメント
- リポスト
- 共有
Anthropicの収益ランレートはついに$20 BILLIONに達しました
>$9 billionは2025年末までに予測
>$14 billionは数週間前
>$19 billionは今
彼らは数週間で$5 billionを追加しました
それは成長ではなく、巨大なAPI契約が同時に成立していることを除けば、理解できない速度でのエンタープライズ採用です。
原文表示>$9 billionは2025年末までに予測
>$14 billionは数週間前
>$19 billionは今
彼らは数週間で$5 billionを追加しました
それは成長ではなく、巨大なAPI契約が同時に成立していることを除けば、理解できない速度でのエンタープライズ採用です。

- 報酬
- いいね
- コメント
- リポスト
- 共有
私は同時に24セッションのマルチエージェントセッションをcodexで実行しました
openai、何だこれ?
1つのタブの10倍のトークン数
出力は1つの集中したプロンプトに対して全く改善されませんでした
> 「エージェント間の協力からの出現行動」
そう、出てきたのは私の請求書でした
あなたはエージェントがお互いに話すためにお金を払っているだけで、何かを生み出すためではありません
エージェントAがエージェントBのために要約し、エージェントCが再フォーマットし、エージェントDに渡し、最終的にあなたが14秒で得られたのと同じjsonを出力します
それはアーキテクチャではなく、計算の劇場です
原文表示openai、何だこれ?
1つのタブの10倍のトークン数
出力は1つの集中したプロンプトに対して全く改善されませんでした
> 「エージェント間の協力からの出現行動」
そう、出てきたのは私の請求書でした
あなたはエージェントがお互いに話すためにお金を払っているだけで、何かを生み出すためではありません
エージェントAがエージェントBのために要約し、エージェントCが再フォーマットし、エージェントDに渡し、最終的にあなたが14秒で得られたのと同じjsonを出力します
それはアーキテクチャではなく、計算の劇場です

- 報酬
- 1
- コメント
- リポスト
- 共有
私は同時にcodexで24のマルチエージェントをオンにしました
ひどいです
24のエージェントが並行して動作し、1つのセッションの10倍のトークンを消費しながら、1つのタブと明確なプロンプトから得られるものと全く同じ結果を生み出さない
これはエージェントフレームワークではありません。トークン炉とローディングスピナーです
OpenAIは未来のように見える機能をリリースしましたが、ちょっと目を細めて見ればそう見えるだけで、実際に何かを構築しようとすると、すべてのエージェントがただ同じコンテキストを何度も繰り返し自分に言い聞かせているだけで、あなたの予算を食いつぶしていることに気づきます
「iT's JuSt EaRlY」- なるほど、昨日より少ないものをやるベータに10倍の金を払っているわけです
今の大手テックの「エージェント的」セールストークはUXの演劇に過ぎません。きれいなダッシュボード、並行スピナー、出力ゼロ。
原文表示ひどいです
24のエージェントが並行して動作し、1つのセッションの10倍のトークンを消費しながら、1つのタブと明確なプロンプトから得られるものと全く同じ結果を生み出さない
これはエージェントフレームワークではありません。トークン炉とローディングスピナーです
OpenAIは未来のように見える機能をリリースしましたが、ちょっと目を細めて見ればそう見えるだけで、実際に何かを構築しようとすると、すべてのエージェントがただ同じコンテキストを何度も繰り返し自分に言い聞かせているだけで、あなたの予算を食いつぶしていることに気づきます
「iT's JuSt EaRlY」- なるほど、昨日より少ないものをやるベータに10倍の金を払っているわけです
今の大手テックの「エージェント的」セールストークはUXの演劇に過ぎません。きれいなダッシュボード、並行スピナー、出力ゼロ。
- 報酬
- 2
- 1
- リポスト
- 共有
ybaser :
:
月へ 🌕OpenClawは役に立たない?
実際に使ってみるまでは何も書きたくなかったので、使ってみて、構築して、ワークフローをテストして、正直な時間を費やした。
これが誰も求めていなかった正直なレビューだ。
今のAIエージェント周りのシーンは、友達同士のグループチャットの競争のように感じる。誰のエージェントがクールに聞こえるか、誰のデモがスリックに見えるか、誰のスクリーンショットがより多くのいいねを獲得するか。
しかし、実際に座ってopenclawを使って何かをシンプルにしようとすると、- ワークフローのステップを置き換えるか、手動のプロセスを削減するか - それはできない。
ステップを追加し、新しい依存関係を作り出す。結局、自分が作ったものを面倒見ながら時間を節約しようとする羽目になる。
それはツールではなく、松葉杖だ。
「これがXを置き換えて、二度と戻らない」ようなユースケースを見つけたかった。実際に何時間も探したが、まだ見つかっていない。
もしかしたら、見つかるかもしれない。
原文表示実際に使ってみるまでは何も書きたくなかったので、使ってみて、構築して、ワークフローをテストして、正直な時間を費やした。
これが誰も求めていなかった正直なレビューだ。
今のAIエージェント周りのシーンは、友達同士のグループチャットの競争のように感じる。誰のエージェントがクールに聞こえるか、誰のデモがスリックに見えるか、誰のスクリーンショットがより多くのいいねを獲得するか。
しかし、実際に座ってopenclawを使って何かをシンプルにしようとすると、- ワークフローのステップを置き換えるか、手動のプロセスを削減するか - それはできない。
ステップを追加し、新しい依存関係を作り出す。結局、自分が作ったものを面倒見ながら時間を節約しようとする羽目になる。
それはツールではなく、松葉杖だ。
「これがXを置き換えて、二度と戻らない」ようなユースケースを見つけたかった。実際に何時間も探したが、まだ見つかっていない。
もしかしたら、見つかるかもしれない。

- 報酬
- 1
- コメント
- リポスト
- 共有
ほとんどの人がAIエージェントについて話しているが、実際に作ったことがある人はほとんどいない
こちらが現時点の実際のアーキテクチャだ
ツール呼び出しエージェント = LLMブレイン + 機能レジストリ + 実行ループ
ツールは構造化されたスキーマとして定義する。モデルはどのツールを呼び出すかを選び、引数を渡す。あなたのランタイムがそれを実行し、結果をフィードバックする
これが全てのループだ。魔法はない
langchainやOpenAIのファンクションコールのような現代的なフレームワークがルーティングを処理する。VertexやBedrockのようなクラウドMLプラットフォームは推論のスケーリングを管理し、アイドル状態のGPUに無駄なコストをかけない
Qwen 3.5の小型モデル - 0.8Bから9Bパラメータ - はツール呼び出しをローカルの単一ノードで実行可能。同じ基盤を持つ大規模モデルと比べて計算量が少ないだけだ
エッジの本質はAIが存在することを知ることではなく、ツールをループに組み込み、実際に出力を出せるようにすることだ
もし今エージェントを作っているなら、使っているフレームワークをやめてしまえ
原文表示こちらが現時点の実際のアーキテクチャだ
ツール呼び出しエージェント = LLMブレイン + 機能レジストリ + 実行ループ
ツールは構造化されたスキーマとして定義する。モデルはどのツールを呼び出すかを選び、引数を渡す。あなたのランタイムがそれを実行し、結果をフィードバックする
これが全てのループだ。魔法はない
langchainやOpenAIのファンクションコールのような現代的なフレームワークがルーティングを処理する。VertexやBedrockのようなクラウドMLプラットフォームは推論のスケーリングを管理し、アイドル状態のGPUに無駄なコストをかけない
Qwen 3.5の小型モデル - 0.8Bから9Bパラメータ - はツール呼び出しをローカルの単一ノードで実行可能。同じ基盤を持つ大規模モデルと比べて計算量が少ないだけだ
エッジの本質はAIが存在することを知ることではなく、ツールをループに組み込み、実際に出力を出せるようにすることだ
もし今エージェントを作っているなら、使っているフレームワークをやめてしまえ
- 報酬
- いいね
- コメント
- リポスト
- 共有