交易者郭勇
币圈解套王炸!老郭带你撕毁亏损协议,72小时逆袭翻仓!
深度套牢?账户缩水50%+?看着K线暴跌欲哭无泪?别慌!老郭用10年币圈实战战绩告诉你——套牢不是终点,是抄底翻倍的起点!
币圈震荡期90%的散户都在犯两个致命错误:要么恐慌割肉在最低点,要么死扛硬扛错过反弹窗口!而老郭的解套体系,早已帮学员实现“深套→解套→盈利”的三级跳
别让套牢耗尽你的资金和信心!币圈机会永远不缺,缺的是破局的方法和领路的人!现在跟上老郭,下一个解套翻仓的就是你!
深度套牢?账户缩水50%+?看着K线暴跌欲哭无泪?别慌!老郭用10年币圈实战战绩告诉你——套牢不是终点,是抄底翻倍的起点!
币圈震荡期90%的散户都在犯两个致命错误:要么恐慌割肉在最低点,要么死扛硬扛错过反弹窗口!而老郭的解套体系,早已帮学员实现“深套→解套→盈利”的三级跳
别让套牢耗尽你的资金和信心!币圈机会永远不缺,缺的是破局的方法和领路的人!现在跟上老郭,下一个解套翻仓的就是你!

- 赞赏
- 点赞
- 评论
- 转发
- 分享
全世界每一位基督徒都必须支持黎巴嫩 🇱🇧
黎巴嫩是基督教仍然完整保留下来的最后一处地方,并且是黎巴嫩社会不可或缺的一部分
黎巴嫩拥有全世界最多的基督教牧师(按人均)
黎巴嫩孕育了一些教会历史上最伟大的圣人
愿上帝保佑黎巴嫩及其人民。
愿上帝保护黎巴嫩及其人民。
查看原文黎巴嫩是基督教仍然完整保留下来的最后一处地方,并且是黎巴嫩社会不可或缺的一部分
黎巴嫩拥有全世界最多的基督教牧师(按人均)
黎巴嫩孕育了一些教会历史上最伟大的圣人
愿上帝保佑黎巴嫩及其人民。
愿上帝保护黎巴嫩及其人民。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
祝贺我 🥳
今晚我不再喝木薯粉了
谁能猜到是谁为我做的?
查看原文今晚我不再喝木薯粉了
谁能猜到是谁为我做的?

- 赞赏
- 点赞
- 评论
- 转发
- 分享
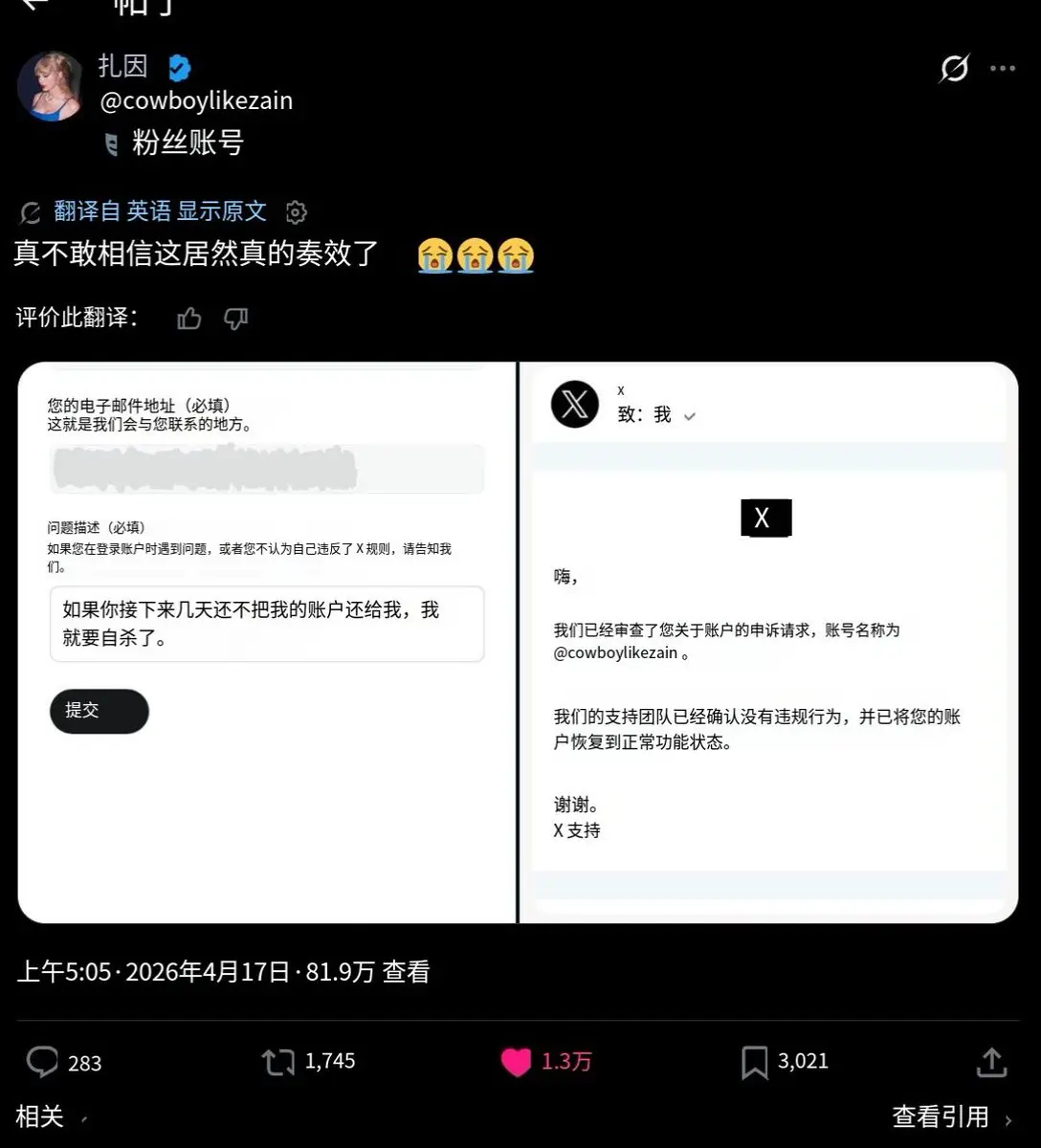
推特最新解封方法?兄弟们,等我几天我来去试试
@TermMaxFi 近日在其 Alpha 产品中进行了更新,在 BNB Chain 上新增了六种代币的无清算杠杆功能。
现在可以通过 TermMax Alpha 对以下资产进行 Long 或 Short 操作,该功能采用固定利率机制,且不涉及传统杠杆交易中的清算风险。
产品链接:
TermMax Alpha 的核心设计包括固定利率,已知抵押品价值以及无清算机制,目的是为用户提供相对可预测的杠杆体验,目前该产品已在 BNB Chain 上运行。
此次更新后,可支持的资产范围有所扩大。
@TermMaxFi #TermMaxFi
@TermMaxFi 近日在其 Alpha 产品中进行了更新,在 BNB Chain 上新增了六种代币的无清算杠杆功能。
现在可以通过 TermMax Alpha 对以下资产进行 Long 或 Short 操作,该功能采用固定利率机制,且不涉及传统杠杆交易中的清算风险。
产品链接:
TermMax Alpha 的核心设计包括固定利率,已知抵押品价值以及无清算机制,目的是为用户提供相对可预测的杠杆体验,目前该产品已在 BNB Chain 上运行。
此次更新后,可支持的资产范围有所扩大。
@TermMaxFi #TermMaxFi
BNB2.02%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
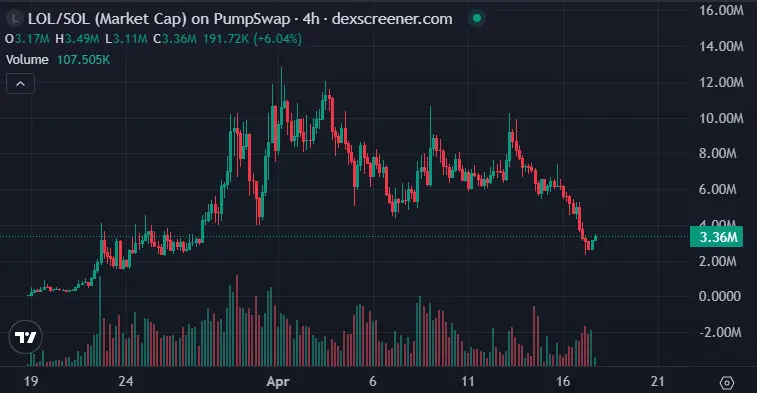
强势早期拉升至四月高点,然后出现明确的分配区间和更低的高点
近期的跌破伴随上涨的卖盘量表明弱手在退出。
在330万附近的小反弹看似缓解,但除非重新以强势突破500万到600万,否则空头将主导行情。
所以,尽快发力!
查看原文近期的跌破伴随上涨的卖盘量表明弱手在退出。
在330万附近的小反弹看似缓解,但除非重新以强势突破500万到600万,否则空头将主导行情。
所以,尽快发力!
- 赞赏
- 点赞
- 评论
- 转发
- 分享
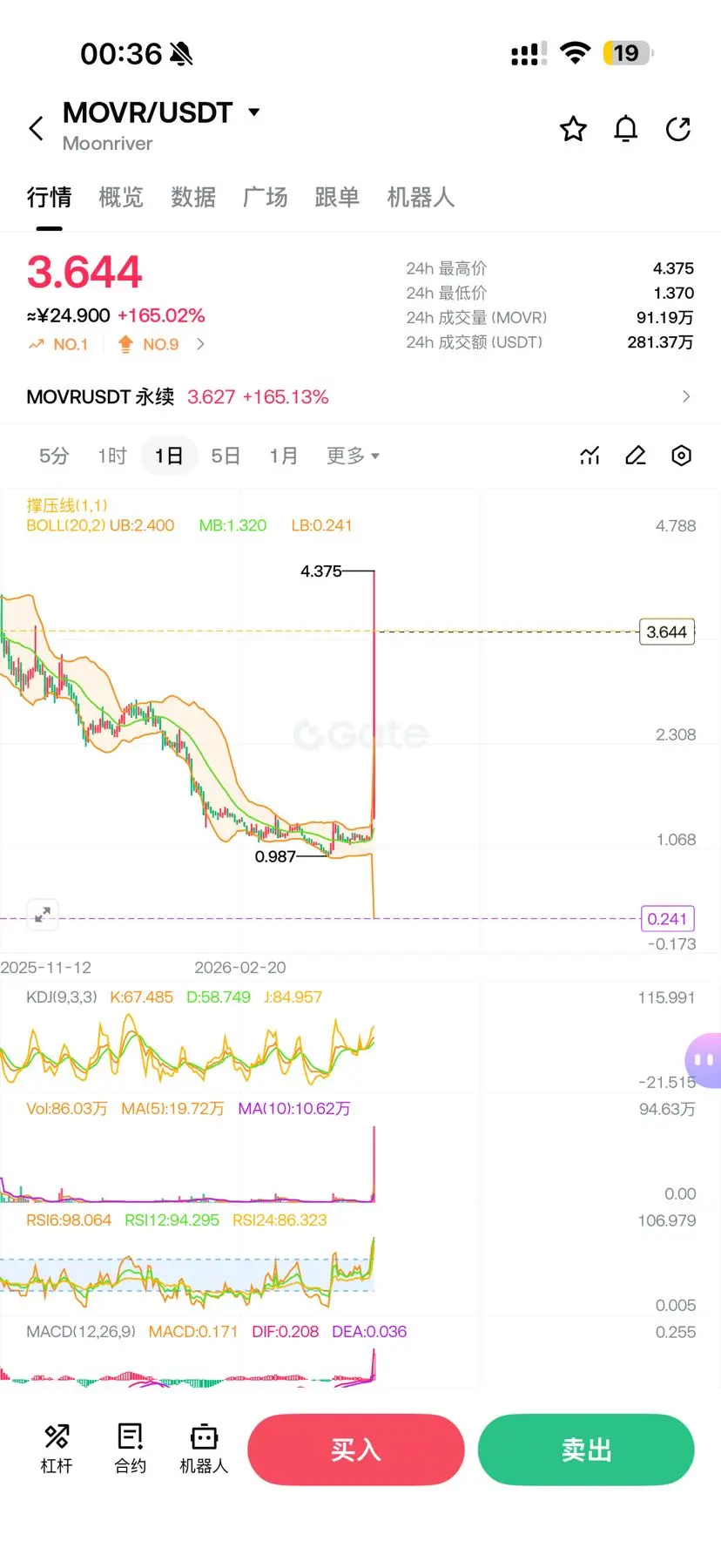
🚀 山寨币反弹强劲!
随着山寨币展现出令人印象深刻的动力,加密市场正变得炙手可热。从突如其来的价格飙升到交易量的增加,投资者再次将注意力转向比特币之外的资产。
这是下一轮大规模山寨币牛市的开始,还是短期的拉升?聪明的交易者正在关注关键水平,保持信息更新,并谨慎管理风险。
保持警惕。保持信息灵通。市场变化迅速。🔥
#AltcoinsRallyStrong #CryptoMarket #Altseason #CryptoTrading #区块链
随着山寨币展现出令人印象深刻的动力,加密市场正变得炙手可热。从突如其来的价格飙升到交易量的增加,投资者再次将注意力转向比特币之外的资产。
这是下一轮大规模山寨币牛市的开始,还是短期的拉升?聪明的交易者正在关注关键水平,保持信息更新,并谨慎管理风险。
保持警惕。保持信息灵通。市场变化迅速。🔥
#AltcoinsRallyStrong #CryptoMarket #Altseason #CryptoTrading #区块链
BTC3.91%

- 赞赏
- 点赞
- 评论
- 转发
- 分享
🚀 Gate $SOON 合约交易大赛现已开启!
每日签到即可获得 370 USDT,立即参与:https://www.gate.com/campaigns/4597
50,000 USDT 奖池等你来瓜分
🎯 每日签到领奖励,充值享空投,并为所有会员提供专属福利,惊喜不断~
公告链接:https://www.gate.com/announcements/article/50769
每日签到即可获得 370 USDT,立即参与:https://www.gate.com/campaigns/4597
50,000 USDT 奖池等你来瓜分
🎯 每日签到领奖励,充值享空投,并为所有会员提供专属福利,惊喜不断~
公告链接:https://www.gate.com/announcements/article/50769
SOON38.22%

- 赞赏
- 1
- 评论
- 转发
- 分享
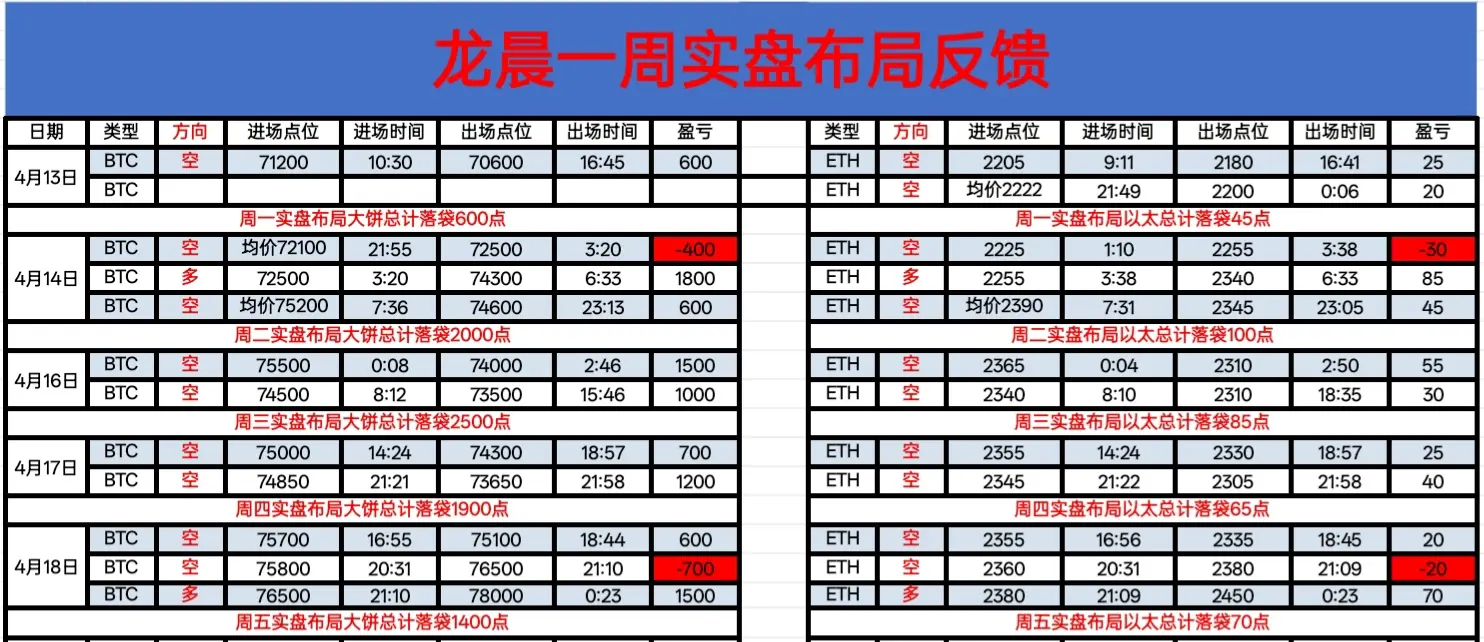
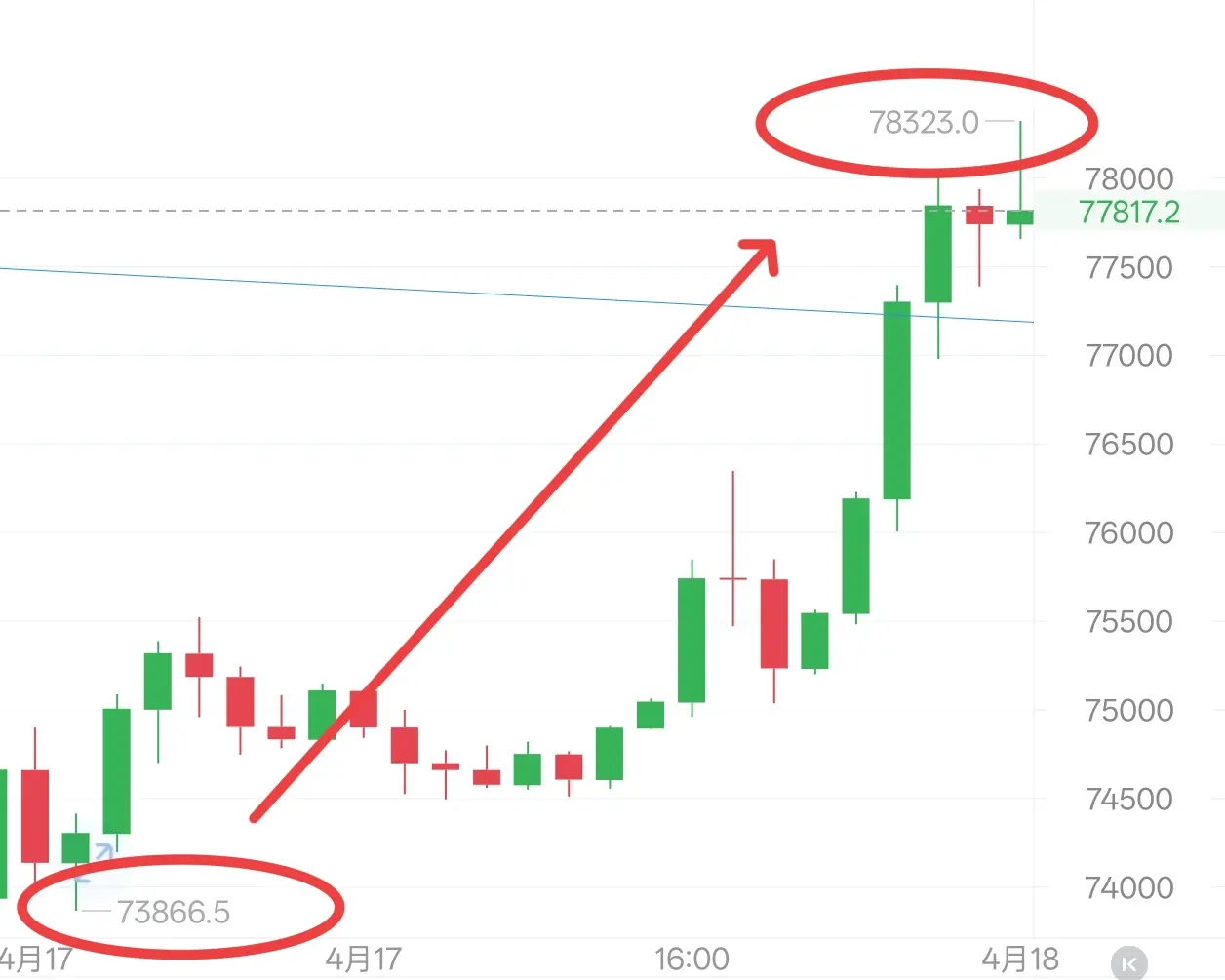
日内大饼走出强势单边上涨行情。凌晨价格自73873低点企稳后开始发力,连续突破75000、76000、77000三道关口,午后加速上行,晚间最高触及78300一线,创出本轮上涨新高。整个上涨过程几乎无像样回撤,低点从73873逐步抬升至78000附近,高点不断创新高,多头动能极为充足。以太同步爆发,日内从2240附近强势拉升至2450上方。日内布局空单随着战争方面数据落地扫损离场反手追多,也成功挽回损失并且拿下一定利润,大饼总计落袋1400点空间,姨太总计落袋70点空间。
从四小时裸K形态看,今日连续收出多根实体饱满的大阳线,形成“上涨加速”结构,K线完全吞没前几日回调阴线,站稳所有短期均线上方。价格已有效突破前期高点76009,并刷新至78300,上升通道斜率明显变陡。今日的突破属于关键阻力位的有效突破,打开了新的上行空间。当前价格在78300附近小幅回落,属于突破后的正常整固。下方77000-77500区域由压力转为支撑,只要回踩不破,上涨结构将延续;上方80000区域是下一目标位,对应前期周线级别的心理关口。日线同步强势拉升站上120日均线结构,关键阻力破位,这样的行情夜间调整后继续做多即可。
大饼可在77000附近多,看79000附近。姨太可在2400-2420多,看2500附近。#山寨币强势反弹 $BTC $ETH
从四小时裸K形态看,今日连续收出多根实体饱满的大阳线,形成“上涨加速”结构,K线完全吞没前几日回调阴线,站稳所有短期均线上方。价格已有效突破前期高点76009,并刷新至78300,上升通道斜率明显变陡。今日的突破属于关键阻力位的有效突破,打开了新的上行空间。当前价格在78300附近小幅回落,属于突破后的正常整固。下方77000-77500区域由压力转为支撑,只要回踩不破,上涨结构将延续;上方80000区域是下一目标位,对应前期周线级别的心理关口。日线同步强势拉升站上120日均线结构,关键阻力破位,这样的行情夜间调整后继续做多即可。
大饼可在77000附近多,看79000附近。姨太可在2400-2420多,看2500附近。#山寨币强势反弹 $BTC $ETH


- 赞赏
- 点赞
- 评论
- 转发
- 分享
看起来$LMAO!准备在图表上勃起一下
查看原文
- 赞赏
- 点赞
- 评论
- 转发
- 分享
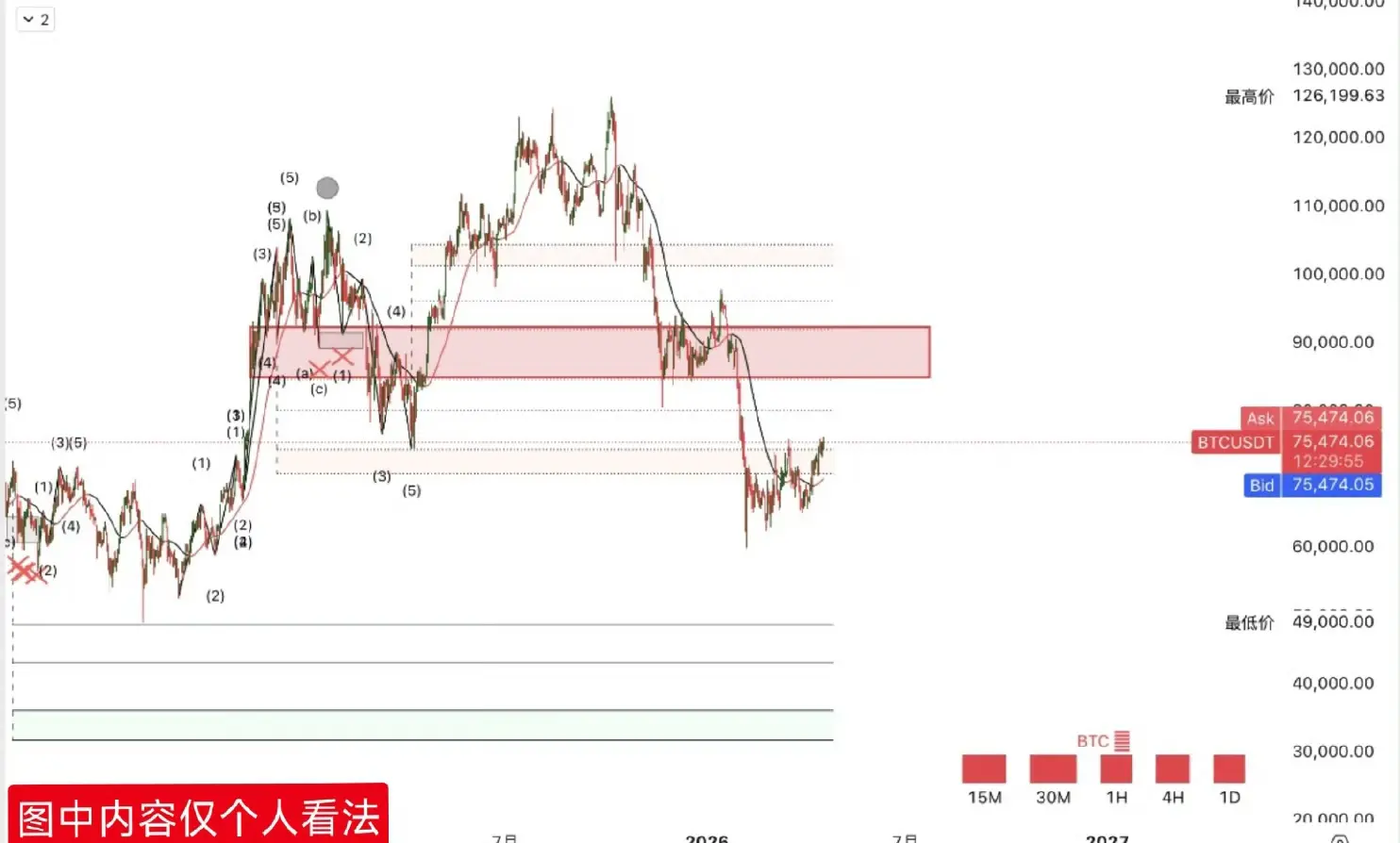
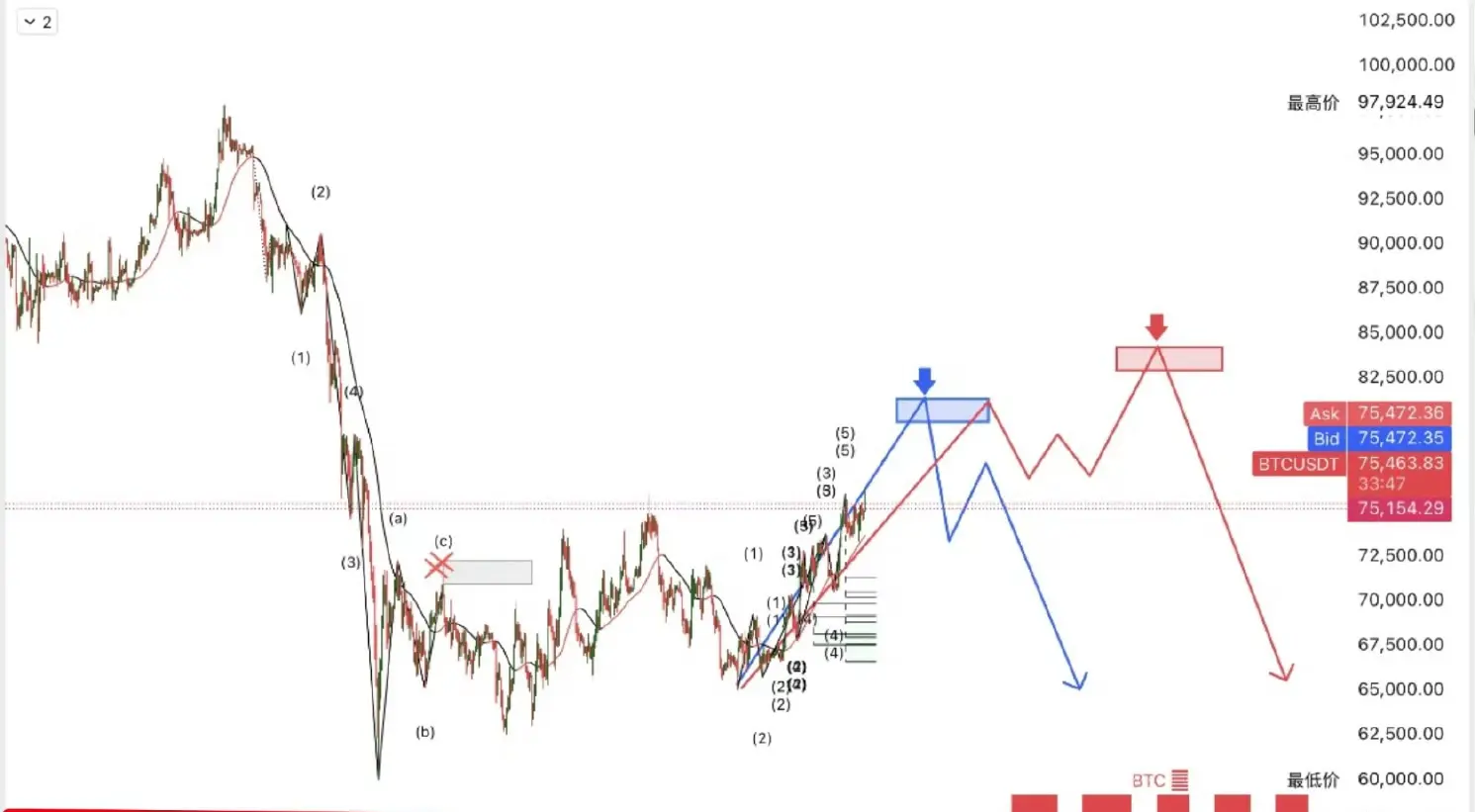
凌晨給个箜單策略吧
V回去仪态在2475附近箜,芷莹2410,跌破2400可继续格局看2380,止笋2530
大饼78500-78800附近箜,芷莹76400破位可继续格局75000,纸笋79500
V回去仪态在2475附近箜,芷莹2410,跌破2400可继续格局看2380,止笋2530
大饼78500-78800附近箜,芷莹76400破位可继续格局75000,纸笋79500
- 赞赏
- 6
- 评论
- 转发
- 分享

- 赞赏
- 1
- 1
- 转发
- 分享
咸鱼翻身但粘锅:
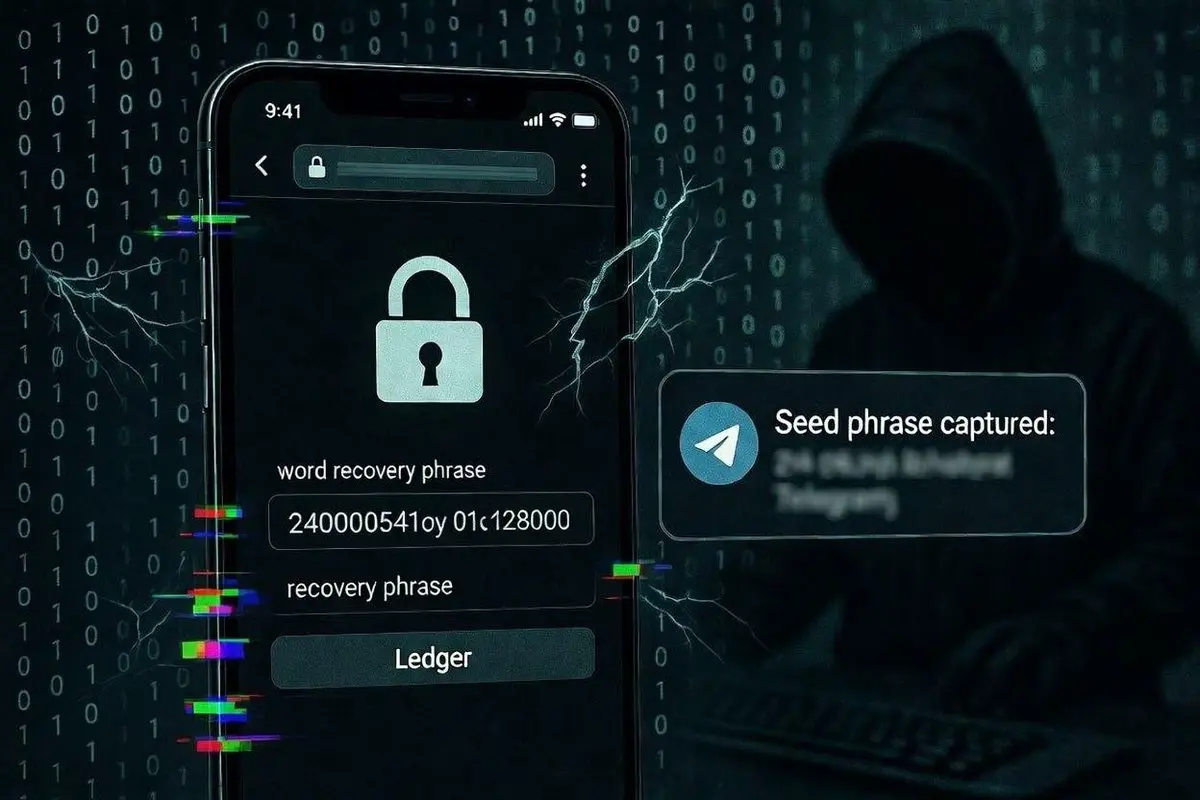
坚定HODL💎突发:巴西研究人员曝光Ledgers假钱包网络。
该专家使用五个同时攻击向量记录了伪造的钱包,这些攻击向量将种子和私钥窃取到恶意服务器。
查看原文该专家使用五个同时攻击向量记录了伪造的钱包,这些攻击向量将种子和私钥窃取到恶意服务器。

- 赞赏
- 点赞
- 评论
- 转发
- 分享


这川子真的要搞死人 一个破消息用了800会

- 赞赏
- 点赞
- 评论
- 转发
- 分享
#AnthropicvsOpenAIHeatsUp
人工智能军备竞赛加剧:基准测试、信任与主导权之争
人工智能领域不再由安静的迭代定义——它由直接竞争所定义。#AnthropicvsOpenAlHeatsUp 所体现的日益紧张,反映出领先的AI开发者之间一场快速加速的竞争,旨在定义下一代智能系统。
一边是 ,其定位围绕安全为重点、推理能力突出的模型,旨在确保可靠性和结构化输出。另一边是 ,它通过快速扩张、产品集成以及广泛的生态系统采用,持续保持着主导地位。
这场竞争之所以独特,并不只是因为它关乎性能——更关乎信任。
在早期的技术周期里,最好的模型往往会通过“更快”或“更强”来取胜。在当前的AI时代,“最佳”的定义变得更加复杂。它涵盖推理能力、与人类意图的一致性、安全约束,以及融入现实世界的工作流程。这将竞争从“原始智能”转向“可用智能”。
基准测试方面的改进,例如新版本模型优于前代,是重要信号——但它们不再是全部。如今,每一次发布都会从多个维度进行评估:推理一致性、幻觉减少、延迟、多模态能力,以及跨任务的适应性。
这便形成了快速迭代的反馈循环。
当一家公司的模型发布更强版本时,另一家公司会迅速作出回应,从而压缩创新周期。结果是,AI格局的演变不再是按年度跃迁,而是以每月甚至每周的增量推进。在现代技术中,这种发展节奏前所未有。
同时,战略也出现了日益分化。
有些模型优先考虑开放性与
查看原文人工智能军备竞赛加剧:基准测试、信任与主导权之争
人工智能领域不再由安静的迭代定义——它由直接竞争所定义。#AnthropicvsOpenAlHeatsUp 所体现的日益紧张,反映出领先的AI开发者之间一场快速加速的竞争,旨在定义下一代智能系统。
一边是 ,其定位围绕安全为重点、推理能力突出的模型,旨在确保可靠性和结构化输出。另一边是 ,它通过快速扩张、产品集成以及广泛的生态系统采用,持续保持着主导地位。
这场竞争之所以独特,并不只是因为它关乎性能——更关乎信任。
在早期的技术周期里,最好的模型往往会通过“更快”或“更强”来取胜。在当前的AI时代,“最佳”的定义变得更加复杂。它涵盖推理能力、与人类意图的一致性、安全约束,以及融入现实世界的工作流程。这将竞争从“原始智能”转向“可用智能”。
基准测试方面的改进,例如新版本模型优于前代,是重要信号——但它们不再是全部。如今,每一次发布都会从多个维度进行评估:推理一致性、幻觉减少、延迟、多模态能力,以及跨任务的适应性。
这便形成了快速迭代的反馈循环。
当一家公司的模型发布更强版本时,另一家公司会迅速作出回应,从而压缩创新周期。结果是,AI格局的演变不再是按年度跃迁,而是以每月甚至每周的增量推进。在现代技术中,这种发展节奏前所未有。
同时,战略也出现了日益分化。
有些模型优先考虑开放性与

- 赞赏
- 点赞
- 评论
- 转发
- 分享
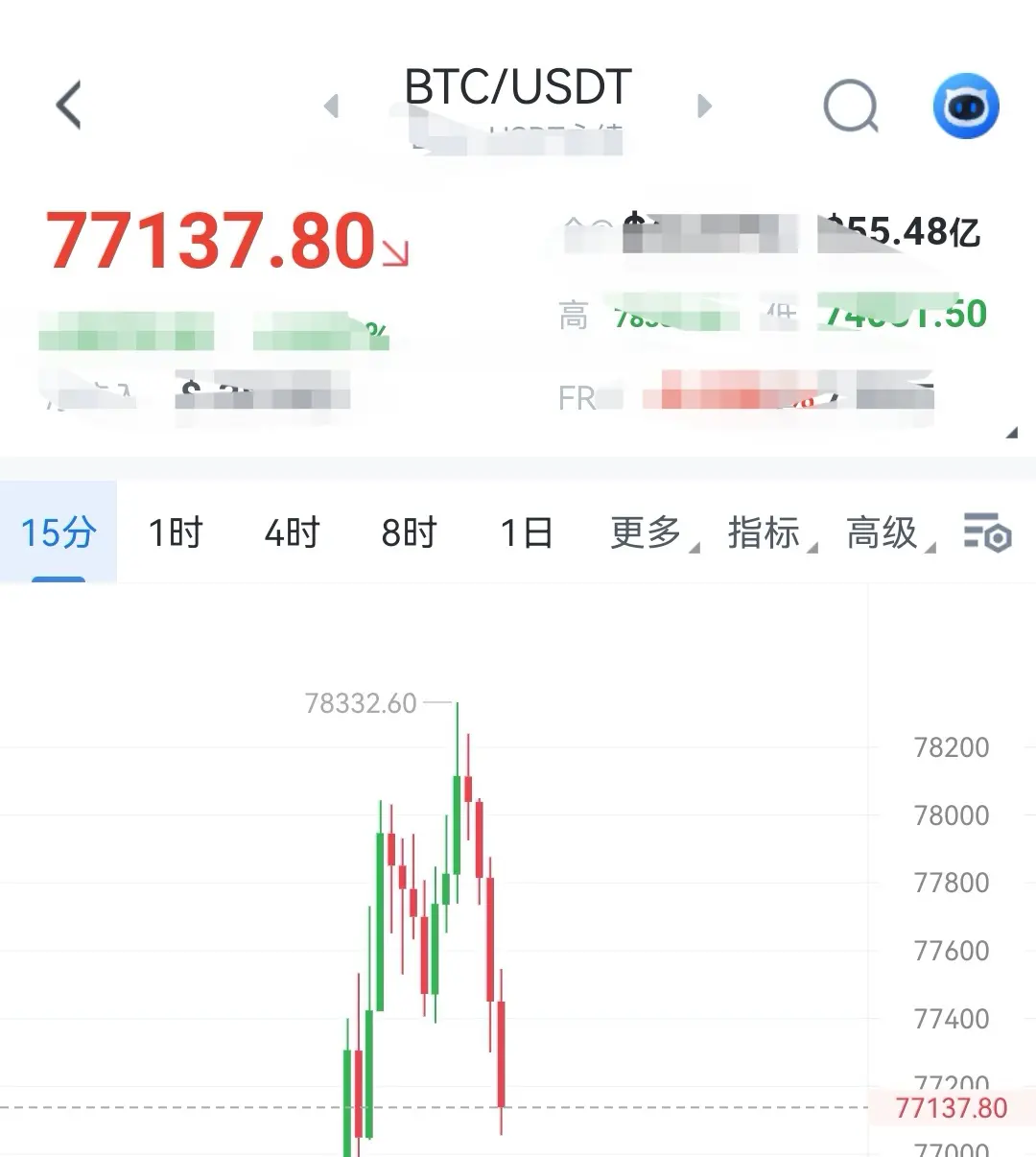
今晚eth大动作不要错过了OK?
3,562
- 赞赏
- 点赞
- 评论
- 转发
- 分享
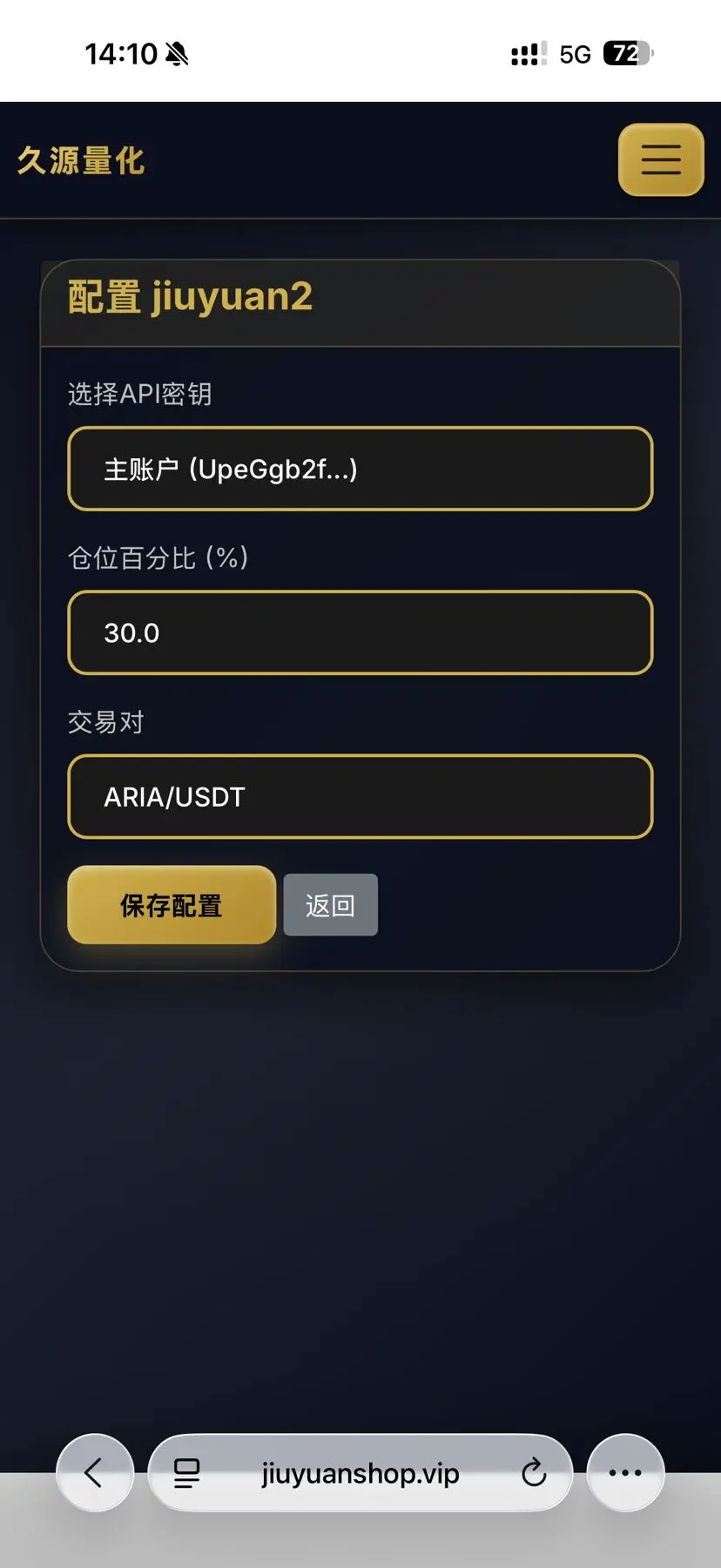
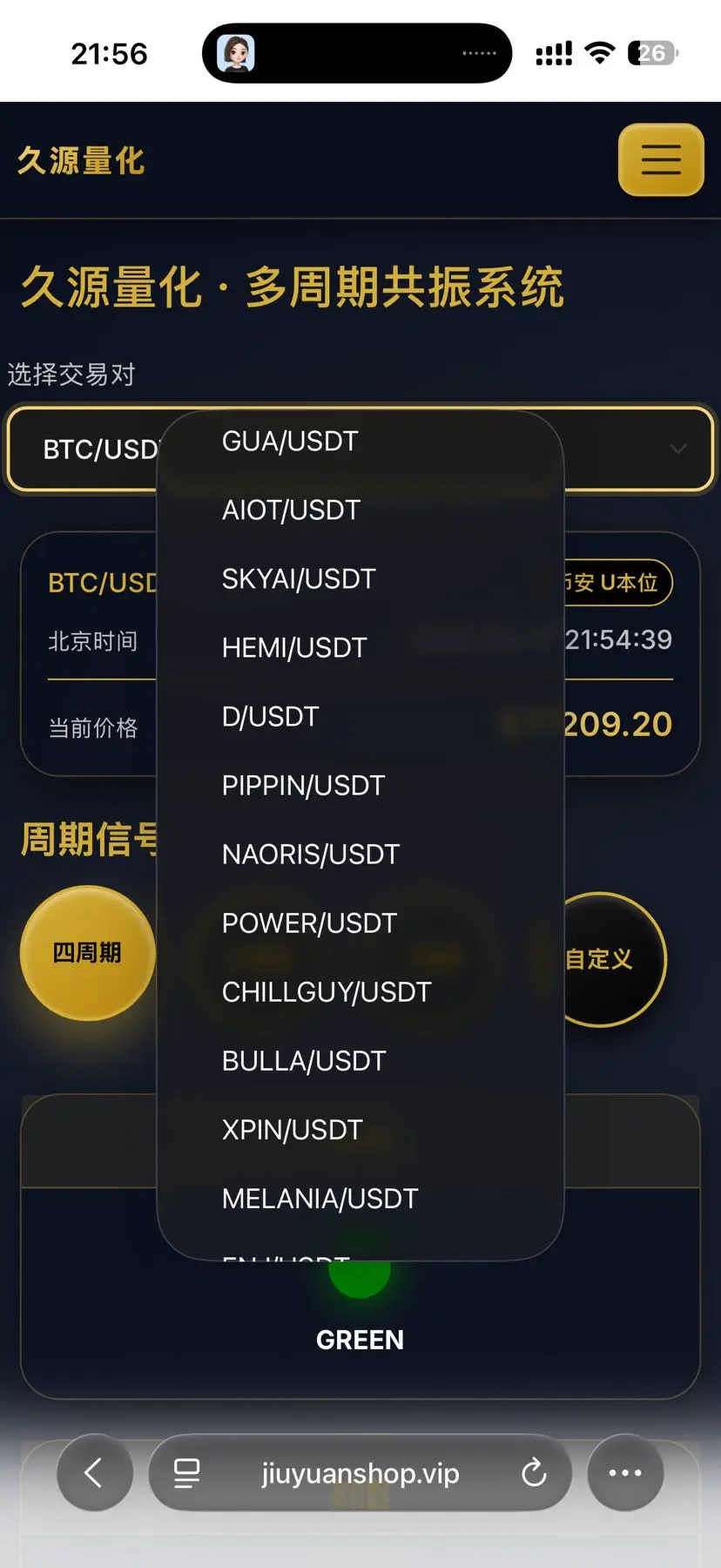
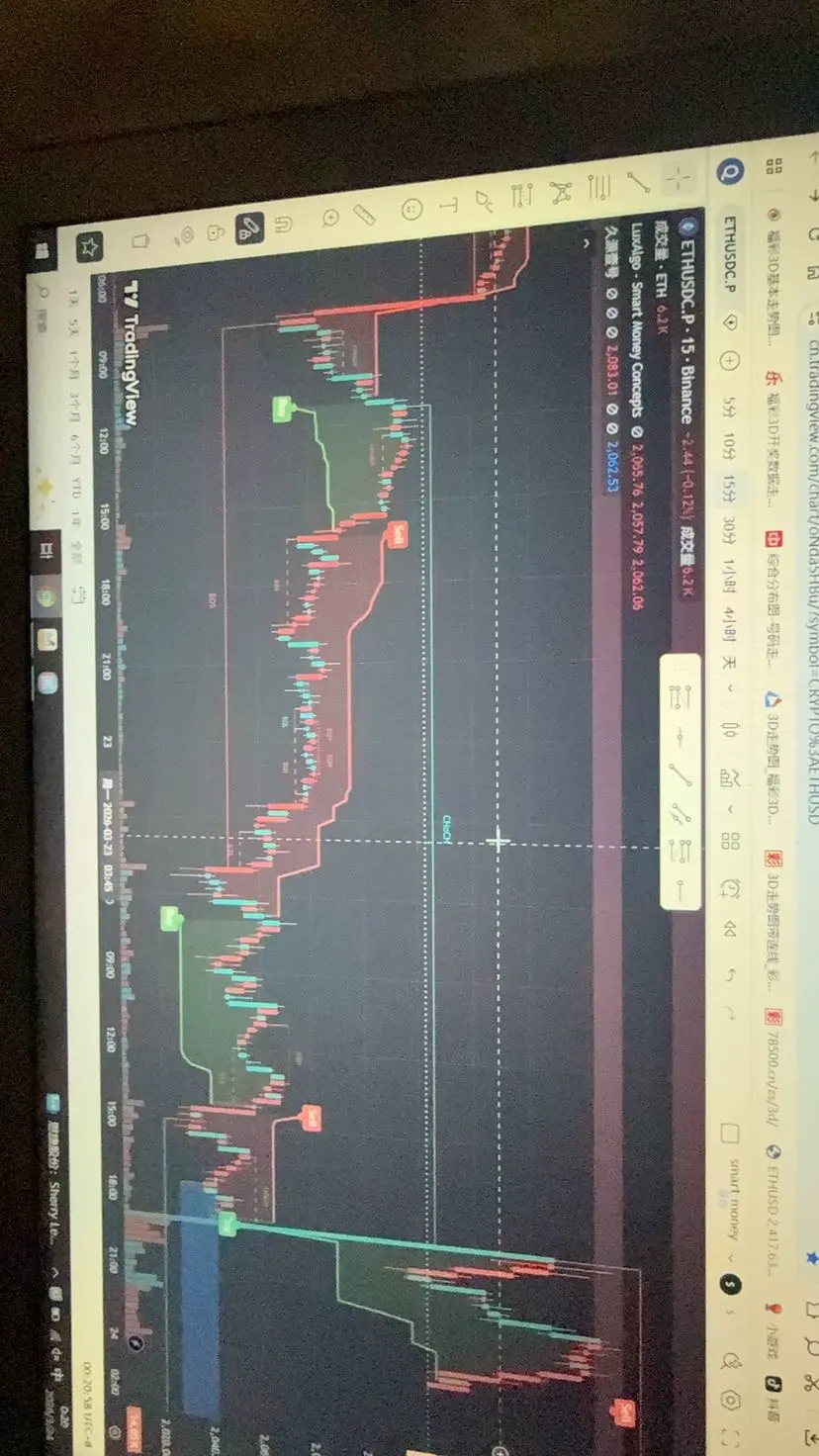
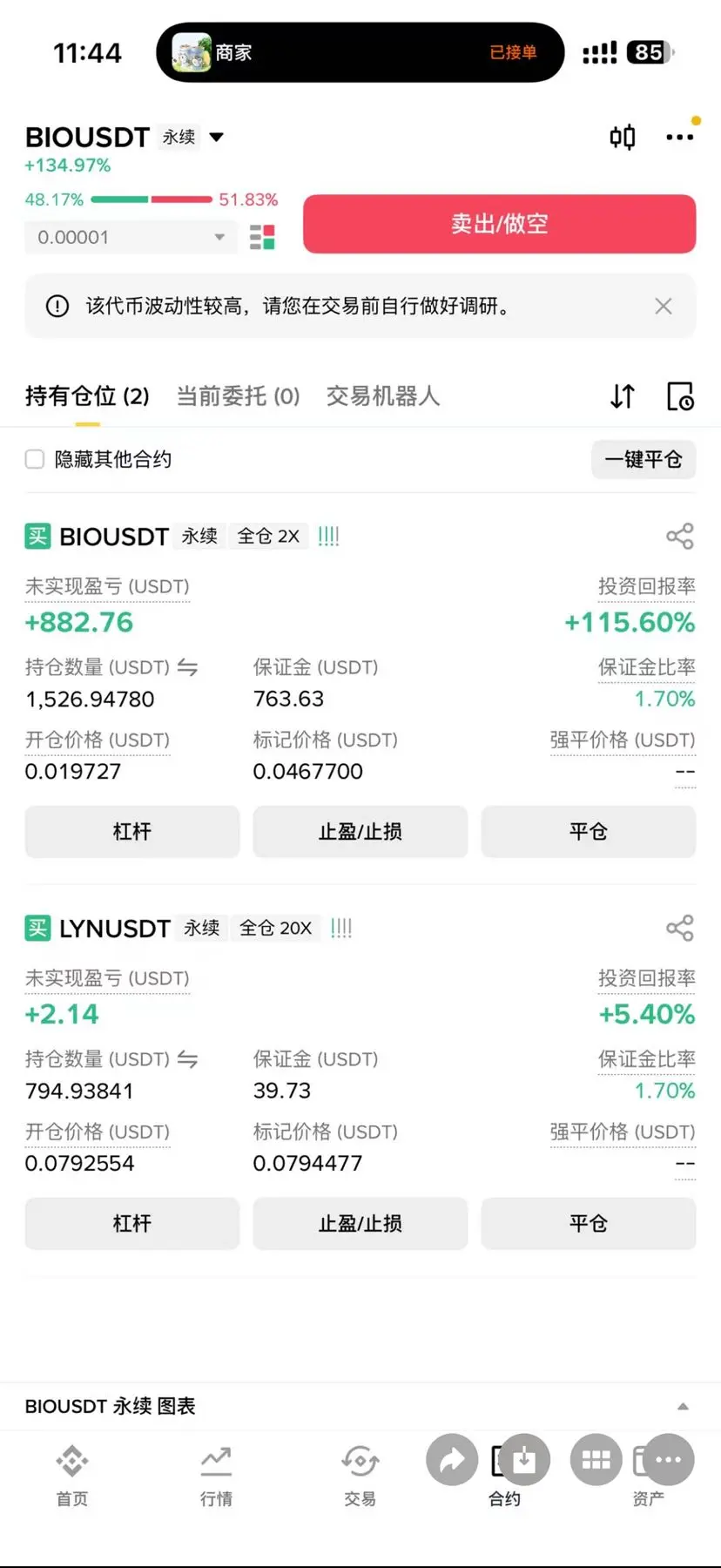
(久源量化 )多周期共振系统 ,链上全面监控资金流向 ,提供多空策略 。全自动趋势策量化 纯现货交易 月化1-5倍稳赢 需要的可以先了解

- 赞赏
- 点赞
- 评论
- 转发
- 分享
加载更多
加入 4000万 人汇聚的头部社区
⚡️ 与 4000万 人一起参与加密货币热潮讨论
💬 与喜爱的头部博主互动
👍 查看感兴趣的内容
热门话题
查看更多18.83万 热度
74.19万 热度
731.69万 热度
106.43万 热度
45.88万 热度
快讯
查看更多置顶
📢 Gate 广场|4/17 热议:#山寨币强势反弹
随着 BTC 企稳回升,压抑已久的山寨币市场迎来报复性反弹!
领涨先锋: $ORDI 24H 飙升 190% 领跑赛道。
普涨行情: $SATS、$NEIRO、$AXL 涨幅均超 40%,高波动资产流动性显著回暖。
这究竟是“深坑反弹”的起点,还是主升浪前的最后诱多?你会果断满仓,还是保持空仓观望?
🎁 行情研判,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 本期讨论:
1️⃣ 这波反弹你上车了吗?亮出你的操作策略或收益截图!
2️⃣ 还有哪些币种值得重点关注?
2️⃣ 后续行情如何?留下你的精准预测。
分享您的观点 👉 https://www.gate.com/post
📅 4/17 12:00 - 4/19 18:00 (UTC+8)如何参与 Gate 首期 Pre-IPOs:SpaceX (SPCX) 认购?
🔹 新手也能快速上手,仅需 4 步,轻松搞定认购流程
🔹 认购总量:33,900 $SPCX,认购价:$590
🔹 VIP5+ 用户及超级代理商,可享额外免费空投
📅 认购开启:4月20日18:00 (UTC+8)
前往 Pre-IPOs:https://www.gate.com/ipos/2
更多详情:https://www.gate.com/announcements/article/50724十三载风雨同行,您是 Gate 最珍贵的见证者。分享您的故事,瓜分重磅周年豪礼!
参与方式
1️⃣ 带 #Gate13周年 和相应主题标签,在 13 周年留言板或广场发帖
2️⃣ 分享您与 Gate 的故事、送上祝福,或畅想未来 13 年
13 周年定制礼盒、红牛模型、大额仓位体验券等您来拿!
13周年庆留言板 👉️ https://www.gate.com/activities/13th-anniversary
Gate 广场 👉️ https://www.gate.com/post
13 年成长,感谢有您。您的故事,我们期待聆听!
详情:https://www.gate.com/announcements/article/50694🎉 Gate 广场创作者狂欢正式开启
发文冲榜、社群接龙、分享有奖 — 瓜分 2,000 USDT 及周年礼包
📅 活动时间:4 月 8 日 - 4 月 22 日
✅ 发文冲榜:内容质量 + 互动数据 + 挖矿收益综合评分瓜分1200 USDT
✅ TG群组打卡:每周抽 3 份周年礼盒 + 7 份 200 U 体验金券
✅ X 同步奖:分享内容至 X 平台,瓜分 500 USDT 额外奖池
📌 活动详情:https://www.gate.com/announcements/article/50593
📌 报名链接:https://www.gate.com/questionnaire/7536
#Gate广场 #创作者狂欢 #内容挖矿