AI’s Biggest Grassroots Moment
AI’s biggest bottleneck isn’t model design or GPUs – it’s data. And right now, that data is getting locked up and mucked up. Big Web2 platforms (Reddit, X, Google, etc.) are gatekeeping their info behind paywalls or tight TOS. Data monopolies have arrived, and they’re starving out the little guys. At the same time, the open web’s quality is nose-diving – info gets deliberately poisoned, and AI-generated fluff is polluting the corpus. It’s a perfect storm: AI needs data, but the well is guarded and contaminated.

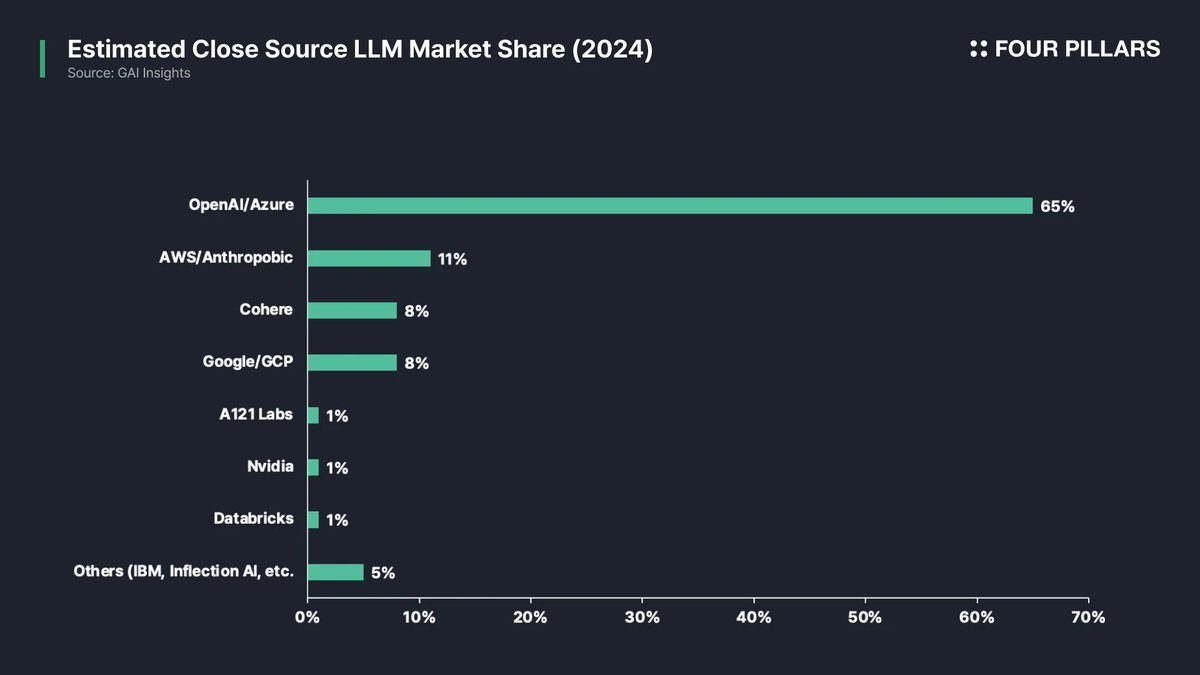
*See full version of “AI’s Biggest Grassroots Moment” on Four Pillars’ Research Portal
1. Grass’ Contrarian Bet: Decentralize the Scraper, Tokenize the Pipeline
Enter @getgrass_io, a decentralized web-scraping protocol that flips this script. Think millions of everyday devices (PCs now, phones soon) acting as mini web crawlers, scraping the internet 24/7 for public data. Grass transforms raw web content into structured AI-ready datasets, and it does it via crypto economics: users earn rewards for contributing bandwidth and compute. It’s like crowdsourced web mining, but for information instead of Bitcoin.
2. The Swarm Is Already Alive
Grass is already live at scale. Over 3 million nodes worldwide are plugged into the network, and they’re collectively scraping over a staggering 1,500 TB of data daily. By using countless residential IPs, Grass can gather data from sites without tripping the usual anti-scraping alarms (no more getting IP banned for crawling too much). It basically replaces giant centralized data farms with a swarm of individual “data bees” – harder to swat, easy to scale.

Why does this matter? Because it cracks open the data monopolies. Instead of a few big players hoarding data or charging absurd fees, any AI startup or researcher can tap into Grass’s data stream. Imagine pulling Reddit or Twitter content for your AI model without begging for API access or shelling out millions – Grass makes that plausible. It’s the permissionless alternative for the AI era: if data is the new oil, Grass is building a decentralized oil rig network where anyone can drill.
3. Verifying Data via ZK Proofs
Quality control is the other half of the equation, and Grass has a clever answer: zero-knowledge proofs and on-chain verification. Every piece of data scraped can be stamped with a cryptographic proof (a ZK-SNARK) attesting to its origin and integrity, logged on Grass’s own blockchain (a sovereign rollup they’re building for this purpose). In plain English: you get a receipt for each web snippet that says “this came from Source X at time Y and hasn’t been tampered with.” This is huge for fighting data poisoning and junk. When the pipeline is verifiable, you can filter out suspicious or corrupted data – or at least trace issues after the fact. In a world where AI might accidentally train on AI-generated garbage, having an authenticity stamp for data is a game-changer.
4. Scaling to Petabyte-Per-Day and Beyond
Let’s talk tech stack: Grass started on Solana (for speed), but even Solana can’t handle the volume here. So the team thinking of rolling out a sovereign rollup (think of it as their own L2 blockchain) to handle the heavy throughput off a main chain, while still anchoring trust on a base layer.
They call the current major upgrade Sion, and it’s already hitting like a freight train. Grass now handles over 1,500 TB of data per day — not as a goal, but as a live metric. Sion (Phases 1 & 2) supercharged the network, unlocking petabyte-scale throughput and enabling real-time multimodal scraping: not just text, but images and video too, streaming in at scale. Basically, Grass leveled up from a text-only diet to an all-you-can-eat buffet of web data. For AI folks thinking beyond text (hello vision models, GPT-4, etc.), that’s a big deal.

5. How $GRASS Fuels the Flywheel
Now, how does Grass incentivize this sprawling network? Enter the tokenomics. Right now, users earn “Grass points” for running nodes – basically a placeholder for the real thing. A proper $GRASS token is on the horizon, and this is where crypto meets AI economics. The token’s utility will tie the whole system together: AI companies or researchers will spend $GRASS to request data (like paying per API call, but decentralized), and node operators will earn $GRASS for fulfilling those requests (scraping and delivering data). Validators in the network will likely stake tokens to ensure honest behavior and high-quality data delivery (bad actors could be slashed, good actors rewarded). In short, $GRASS will grease the wheels, aligning incentives between data consumers and providers.
6. Decentralized Infra with Real PMF
Crucially, Grass’s approach mitigates a few existential issues in AI:
- Data access inequality: Today, only the Googles and OpenAIs can crawl the whole web (and even they are getting sued or blocked). Grass levels the playing field by making web-scale data accessible to anyone who can pay a bit of token – a much lower barrier.
- Data quality & poisoning: With on-chain proofs and (eventually) community-driven validation, it’s much harder for someone to sneak toxic data into a training set unnoticed. Grass can flag or exclude content that doesn’t match its on-chain fingerprint. Over time, the network’s distributed nature could even help identify AI-generated content and keep it from reinforcing the loop (imagine filtering out news articles that are just ChatGPT outputs).
- Censorship resistance: Because Grass operates via thousands of independent nodes, no single kill switch can turn off the flow of information. It’s the Streisand effect meets blockchain – try to block data here, and it just routes around. For AI devs, that means more robust pipelines.
7. Final Alpha: Don’t Build Black Boxes, Build Grassroots AI
To be clear, Grass is still in its early days. It’s in beta, some parts are still centralized (there’s a central coordinator now, to be decentralized later), and data storage/cleaning is client-side for the moment. But the trajectory is set. The network is exploding in size (hitting all-time highs in nodes and data volume this year), and each upgrade (like Sion) pushes it closer to a fully-fledged, self-sustaining protocol.
The vision is bold: Grass wants to be the data layer for decentralized AI. Imagine an open marketplace where anyone can source high-quality training data on demand, with cryptographic trust baked in. No gatekeepers, no giant rents paid to Reddit or Google, and fewer worries about models collapsing from eating their own tail. It’s an AI data firehose that’s owned by the community and secured by crypto.
In a crypto world hungry for real utility, Grass stands out as a project merging two mega-trends (AI & DePIN) with a real product in the wild. It’s meme-savvy by name but serious in execution. If it succeeds, Grass could transform the AI landscape – turning the web itself into a living, breathing data source that’s open to all. For VCs, builders, and Crypto Twitter lurkers, keep an eye on this one. It’s not often you see a new layer of internet infrastructure being built in real time, powered by a token and a dream of free-flowing information.
Disclaimer:
- This article is reprinted from [Ponyo : : FP]. All copyrights belong to the original author [Ponyo : : FP]. If there are objections to this reprint, please contact the Gate Learn team, and they will handle it promptly.
- Liability Disclaimer: The views and opinions expressed in this article are solely those of the author and do not constitute any investment advice.
- The Gate Learn team does translations of the article into other languages. Copying, distributing, or plagiarizing the translated articles is prohibited unless mentioned.
Share
Content
1. Grass’ Contrarian Bet: Decentralize the Scraper, Tokenize the Pipeline
2. The Swarm Is Already Alive
3. Verifying Data via ZK Proofs
4. Scaling to Petabyte-Per-Day and Beyond
5. How $GRASS Fuels the Flywheel
6. Decentralized Infra with Real PMF
7. Final Alpha: Don’t Build Black Boxes, Build Grassroots AI


Related Articles

Arweave: Capturing Market Opportunity with AO Computer

The Upcoming AO Token: Potentially the Ultimate Solution for On-Chain AI Agents

AI Agents in DeFi: Redefining Crypto as We Know It

Dimo: Decentralized Revolution of Vehicle Data

What is AIXBT by Virtuals? All You Need to Know About AIXBT
