
ระบบ AI สำหรับความทรงจำ MemPalace ที่นักแสดงสาวชื่อดัง Milla Jovovich มีส่วนร่วมในการพัฒนา อ้างว่าสอบผ่านเต็มคะแนนแล้วโด่งดังอย่างรวดเร็ว แต่กลับถูกชุมชนถกเถียงว่าการทดสอบมีพฤติกรรมฉ้อโกงและการบิดเบือนข้อมูล จากการทดสอบจริงพบว่าผลลัพธ์ถูกพูดเกินจริงและมีข้อผิดพลาดจำนวนมาก ทีมงานยอมรับข้อบกพร่องแล้วและกำลังดำเนินการแก้ไขอยู่
มิลลา โจวอวิช สร้าง AI memory palace ดึงความสนใจจากภายนอก
เมื่อวาน (4/7) ในวงการ AI มีข่าวใหญ่ ว่านักแสดงหญิงฮอลลีวูด มิลลา·โจวอวิช (Milla Jovovich) ที่โด่งดังจาก “Resident Evil” และ “The Fifth Element” ร่วมกับนักพัฒนา Ben Sigman ใช้ Claude Code เพื่อช่วยในการพัฒนา “MemPalace” ซึ่งเป็นระบบ AI memory แบบโอเพนซอร์ส
ช่วงเวลาหนึ่ง การกล่าวอ้างว่า “ซูเปอร์สตาร์ฮอลลีวูดข้ามสายงานแล้วทำโปรเจกต์ที่ได้เต็มคะแนน” แพร่หลายไปทั่ว และจนถึงตอนนี้ MemPalace บน GitHub ก็มีมากกว่า 20k ดาว แต่ไม่นานก็เกิดข้อสงสัยในชุมชนนักพัฒนา: มันมีของจริงหรือเป็นแค่การทำการตลาด?
ขอพูดถึงแรงจูงใจที่ทำให้ MemPalace เกิดขึ้นก่อน เอกสารอย่างเป็นทางการระบุว่าตั้งใจจะแก้ปัญหาที่โดยปกติแล้วเนื้อหาบทสนทนา กระบวนการตัดสินใจ และการถกเถียงโครงสร้างของระบบ AI จะหายไปหลังจบช่วงทำงาน ทำให้ความทุ่มเทหลายเดือนต้อง “ลดลงถึงศูนย์”
เพื่อแก้ปัญหานี้ MemPalace ใช้สถาปัตยกรรมแบบพื้นที่ในการจัดเก็บความทรงจำ โดยจำแนกข้อมูลอย่างชัดเจนเป็นเขตปีกที่แทนบุคลากรหรือโปรเจกต์ และโครงสร้างในระดับต่าง ๆ เช่น ทางเดิน ห้อง และลิ้นชัก เพื่อเก็บต้นฉบับบทสนทนาไว้สำหรับการค้นหาเชิงความหมายในภายหลัง
ทีมพัฒนาระบุว่า MemPalace ได้คะแนน 100% ในเกณฑ์การประเมินความทรงจำระยะยาว LongMemEval และทำได้ 96.6% โดยไม่เรียกใช้ API ภายนอกใด ๆ อีกทั้งสามารถรันได้ทั้งหมดบนเครื่องท้องถิ่น ไม่จำเป็นต้องสมัครบริการคลาวด์ และมาพร้อมระบบภาษา/ระบบสำเนียง AAAK ที่ถูกอ้างว่าสามารถทำการบีบอัดแบบไม่สูญเสียได้ถึง 30 เท่า
รูปภาพจากแหล่งที่มา: GitHub มิลลา โจวอวิช ดาราภาพยนตร์ชาวอเมริกัน สร้าง AI memory palace ดึงความสนใจจากภายนอก
คู่แข่งและชุมชนต่างตั้งคำถาม การทดสอบและการโฆษณามีข้อบกพร่อง
แต่เมื่อ MemPalace อ้างว่าสอบได้เต็มคะแนนใน LongMemEval ผลลัพธ์ดังกล่าวก็ถูกตั้งคำถามจากคู่แข่งอย่างรวดเร็ว
PenfieldLabs ซึ่งเป็นบริษัทที่ทำระบบความทรงจำ AI เช่นกัน ระบุว่า MemPalace อ้างว่าได้เต็มคะแนนในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์ “เป็นไปไม่ได้” เพราะคำตอบมาตรฐานของชุดข้อมูลนั้นมีข้อผิดพลาดอยู่แล้ว 99 รายการ
จากการวิเคราะห์ PenfieldLabs พบว่า คะแนน 100% ของ MemPalace มาจากการตั้งจำนวนรอบการดึง (retrieval) ไว้ที่ 50 ครั้ง แต่จำนวนขั้นสูงสุดของบทสนทนาในชุดทดสอบมีแค่ 32 ครั้ง ซึ่งหมายความว่า ระบบข้ามขั้นการดึงข้อมูลไปโดยตรง แล้วส่งข้อมูลทั้งหมดให้โมเดล AI อ่าน
เกี่ยวกับคะแนน 100% ของ LongMemEval ทีมพัฒนาถูกพบว่า “เจาะจงแก้ไข” สำหรับปัญหาเฉพาะ 3 รายการที่เกิดข้อผิดพลาดในการพัฒนา โดยเขียนโค้ดสำหรับการซ่อมเฉพาะ และมีข้อสงสัยว่าจะเอื้อให้เกิดการโกงในชุดทดสอบ

รูปภาพจากแหล่งที่มา: Reddit คู่แข่ง PenfieldLabs ชี้ว่า MemPalace อ้างว่าได้เต็มคะแนนในชุดข้อมูล LoCoMo ซึ่งในเชิงคณิตศาสตร์ “เป็นไปไม่ได้”
การทดสอบจริงโดยผู้ใช้ GitHub ฐานการทดสอบมีส่วนที่ทำให้เข้าใจผิด
ผู้ใช้ GitHub hugooconnor แสดงความคิดเห็นหลังการทดสอบจริงว่า MemPalace อ้างว่ามีความแม่นยำในการดึงข้อมูลสูงถึง 96.6% แต่ในความเป็นจริงกลับไม่ได้ใช้โครงสร้าง “memory palace” ตามที่โปรเจกต์โฆษณาไว้เลย hugooconnor ระบุว่าการทดสอบของพวกเขาแค่เรียกฟังก์ชันเริ่มต้นของฐานข้อมูลระดับล่าง ChromaDB เท่านั้น โดยไม่มีส่วนเกี่ยวข้องกับตรรกะการจัดหมวดหมู่ เช่น เขตปีก ห้อง หรือ ลิ้นชัก ที่โปรเจกต์เน้นย้ำ
หลังทดสอบแล้ว hugooconnor พบว่า เมื่อระบบเปิดใช้ตรรกะการจัดหมวดหมู่เฉพาะของ memory palace เหล่านี้อย่างแท้จริง ผลการดึงกลับแย่ลง ยกตัวอย่างในโหมดห้อง ความแม่นยำลดลงถึง 89.4% และเมื่อเปิดใช้งานเทคนิคการบีบอัด AAAK ความแม่นยำยิ่งลดลงไปที่ 84.2% ซึ่งทั้งสองแบบต่ำกว่าประสิทธิภาพของฐานข้อมูลเริ่มต้น
hugooconnor ยังวิจารณ์วิธีการทดสอบว่า สภาพแวดล้อมทดสอบของ MemPalace จงใจย่อขอบเขตการดึงข้อมูลของแต่ละคำถามให้เหลือประมาณ 50 ช่วงบทสนทนา ในคลังตัวอย่างที่เล็กมาก ทำให้การหาคำตอบง่ายเกินไป
หากขยายขอบเขตไปเป็นจำนวนช่วงบทสนทนามากกว่า 19,000 ช่วงในสถานการณ์จริง ความแม่นยำของการค้นหาแบบใช้คีย์เวิร์ดแบบดั้งเดิมจะดิ่งลงสู่ 30% แสดงว่า วิธีการทดสอบปัจจุบันของ MemPalace ปกปิด “ปัญหาความยากของการค้นหาที่แท้จริง”
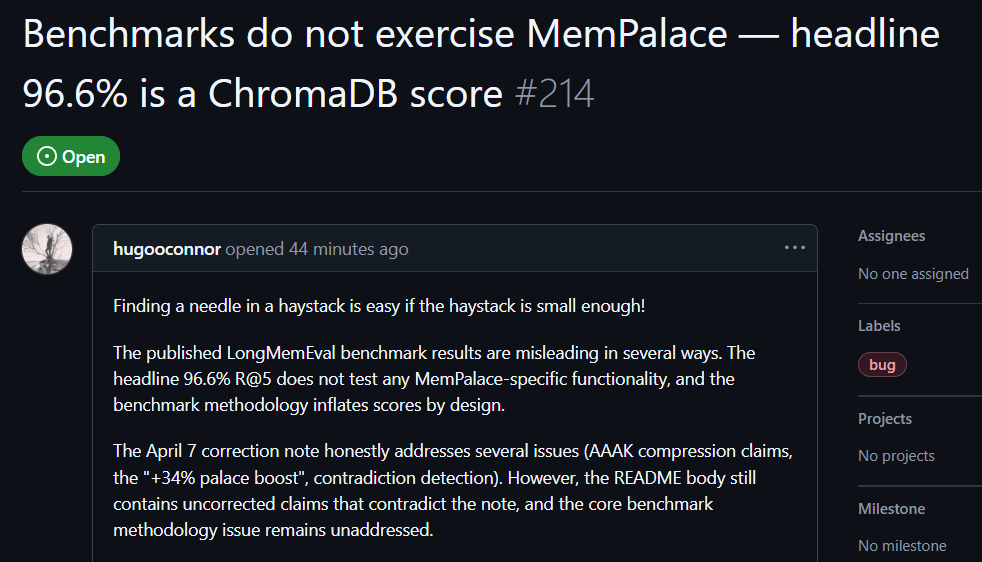
รูปภาพจากแหล่งที่มา: GitHub ผู้ใช้ GitHub ทดสอบจริง พบว่าฐานการทดสอบของ MemPalace มีส่วนที่ทำให้เข้าใจผิด
ขณะเดียวกัน แม้ว่าทีมพัฒนาจะออกแถลงการณ์แก้ไขแล้ว โดยยอมรับว่ามีการพิสูจน์เทคนิค AAAK ว่าเป็นการบีบอัดแบบมีการสูญเสีย และให้คำมั่นว่าจะปรับเอกสารและการออกแบบระบบให้สอดคล้องกับคำวิจารณ์อย่างเข้มงวดจากชุมชน แต่เอกสารคำอธิบายหลักของโปรเจกต์ยังคงคงไว้ซึ่งข้อความที่พูดเกินจริงซึ่งยังไม่ได้รับการแก้ไขหลายรายการ รวมถึงการอ้างว่ามีการบีบอัดแบบไม่สูญเสีย 30 เท่า และการยกระดับการดึงข้อมูล 34% และกราฟเปรียบเทียบกับคู่แข่งรายอื่น ๆ ก็ขาดแหล่งที่มาที่ชัดเจนโดยสิ้นเชิง
ซอร์สโค้ดต้นฉบับของ MemPalace เผชิญกับบั๊กหลายประเด็น
เมื่อมีนักพัฒนาเพิ่มมากขึ้นที่ดาวน์โหลดการทดสอบ ตอนนี้บนแพลตฟอร์ม GitHub ปรากฏรายงานบั๊กจำนวนมากเกี่ยวกับซอร์สโค้ดของ MemPalace
ผู้ใช้ cktang88 ได้ระบุข้อบกพร่องร้ายแรงหลายอย่าง รวมถึงคำสั่งการบีบอัดใช้งานไม่ได้และทำให้ระบบล่ม, ข้อผิดพลาดในตรรกะการคำนวณจำนวนคำของสรุป, และสถิติจำนวนข้อมูลที่ขุดห้อง (mining rooms) ไม่ถูกต้อง รวมถึงปัญหาว่าเซิร์ฟเวอร์จะโหลดข้อมูลตีความทั้งหมดลงในหน่วยความจำทุกครั้งที่มีการเรียก ทำให้เกิดปัญหาการใช้ทรัพยากรอย่างรุนแรง
ปัญหาอื่นที่ถูกชี้ให้เห็น ยังรวมถึงระบบที่ “บังคับเขียน” ชื่อสมาชิกในครอบครัวของนักพัฒนาเข้าไปในไฟล์ตั้งค่าเริ่มต้น และมีขีดจำกัดการแสดงผลแบบบังคับเมื่อดูสถานะ โดยมีข้อมูลอยู่ 10k รายการ
สำหรับปัญหาเหล่านี้ ชุมชนโอเพนซอร์สได้เริ่มลงมือแก้ไขอย่างจริงจังแล้ว ผู้ใช้ adv3nt3 ส่งคำขอซ่อมแซมหลายรายการ** รวมถึงการแก้ไขสถิติการขุด, การลบชื่อสมาชิกในครอบครัวที่ตั้งค่าไว้ล่วงหน้า, และการเลื่อนเวลาการเริ่มต้นการสร้างแผนที่ความรู้ (knowledge graph) **ทีมพัฒนาภายหลังยังยอมรับข้อผิดพลาดเหล่านี้ และกำลังแก้ไขปัญหาในโค้ดอย่างเป็นขั้นเป็นตอนด้วยความร่วมมือจากชุมชน
มิลลา โจวอวิช Vibe Coding เจ๋งมาก วิธีการทำการตลาดไม่เจ๋ง
สำหรับโปรเจกต์ MemPalace ผู้ใช้ Hacker News darkhanakh สรุปไว้ว่า: MemPalace ให้ความรู้สึกเหมือน OpenClaw นั่นคือ การจัดการผลการทดสอบเกณฑ์มาตรฐาน (benchmark) อย่างจงใจเพื่อให้ดูสมบูรณ์แบบไร้ที่ติ แล้วจึงเอาไปห่อเป็น “ความก้าวหน้าครั้งสำคัญ” เพื่อทำการตลาด
เขาคิดว่า เทคโนโลยีเบื้องหลังของ MemPalace อาจจะน่าสนใจจริง แต่ในสภาพที่วิธีการทดสอบมีลักษณะข้อบกพร่องแบบนั้น ยังเล่นการโฆษณาว่าเป็น “คะแนนสูงสุดที่เปิดเผยต่อสาธารณะมากที่สุดตลอดกาล” ก็ไม่น่าค่อยเหมาะสม “แต่ถึงอย่างนั้น การที่มิลลา โจวอวิช เล่น Vibe Coding แบบนี้ ฉันก็ยังคิดว่ามันเท่มากนะ”
อ่านเพิ่มเติม:
เขียนโค้ดพัง! แอป “นักล่าความคุ้มค่า” ในตู้ขายของสะดวก ที่ระเบิดปัญหาความปลอดภัยด้านข้อมูลส่วนบุคคล GPS ในบ้านเผยทุกอย่าง
