Gate Ventures Research Insights: A Terceira Guerra dos Navegadores: A Batalha de Entrada na Era dos Agentes de IA
TL;DR
A terceira guerra dos navegadores está se desenrolando silenciosamente. Olhando para a história, desde Netscape e o Internet Explorer da Microsoft nos anos 1990 até o Firefox de código aberto e o Chrome do Google, a guerra dos navegadores sempre foi uma manifestação concentrada do controle de plataformas e mudanças de paradigmas tecnológicos. O Chrome garantiu sua posição dominante graças à sua velocidade de atualização rápida e ecossistema integrado, enquanto o Google, por meio de seu duopólio de busca e navegador, formou um ciclo fechado de acesso à informação.
Mas hoje, essa paisagem está tremendo. O surgimento de grandes modelos de linguagem (LLMs) está permitindo que mais e mais usuários completem tarefas sem clicar na página de resultados da busca, enquanto os cliques em páginas da web tradicionais estão diminuindo. Enquanto isso, rumores de que a Apple pretende substituir o mecanismo de busca padrão no Safari ameaçam ainda mais a base de lucro da Alphabet (empresa-mãe do Google), e o mercado está começando a expressar desconforto sobre a “ortodoxia da busca.”
O navegador em si também está enfrentando uma reconfiguração de seu papel. Ele não é apenas uma ferramenta para exibir páginas da web, mas também um contêiner para múltiplas capacidades, incluindo entrada de dados, comportamento do usuário e identidade privada. Embora os agentes de IA sejam poderosos, eles ainda dependem da fronteira de confiança do navegador e da sandbox funcional para completar interações complexas em páginas, acessar dados de identidade local e controlar elementos da página da web. Os navegadores estão evoluindo de interfaces humanas para plataformas de chamadas de sistema para agentes.
Neste artigo, exploramos se os navegadores ainda são necessários. Acreditamos que o que poderia realmente perturbar o atual cenário do mercado de navegadores não é outro "Chrome melhor", mas uma nova estrutura de interação: não apenas exibição de informações, mas invocação de tarefas. Os navegadores do futuro devem ser projetados para agentes de IA—capazes não apenas de ler, mas também de escrever e executar. Projetos como Browser Use estão tentando semantizar a estrutura da página, transformando interfaces visuais em texto estruturado que pode ser chamado por LLM, mapeando páginas para comandos e reduzindo significativamente os custos de interação.
Grandes projetos já estão testando as águas: Perplexity está construindo um navegador nativo, Comet, que substitui os resultados de busca tradicionais por IA; Brave está combinando proteção de privacidade com raciocínio local, usando LLM para melhorar as capacidades de busca e bloqueio; e projetos nativos de cripto como Donut estão mirando novos pontos de entrada para a IA interagir com ativos on-chain. Uma característica comum entre esses projetos é a tentativa de remodelar a camada de entrada do navegador, em vez de embelezar sua camada de saída.
Para empreendedores, as oportunidades estão dentro do triângulo de input, estrutura e acesso ao agente. Como a interface para o futuro mundo baseado em agentes, o navegador significa que quem puder fornecer "capacidades" estruturadas, chamáveis e confiáveis se tornará um componente da próxima geração de plataformas. De SEO a AEO (Otimização de Motor de Agente), do tráfego de página à invocação de cadeia de tarefas, a forma do produto e o pensamento de design estão sendo remodelados. A terceira guerra dos navegadores está acontecendo sobre "input" em vez de "display". A vitória não é mais determinada por quem captura a atenção do usuário, mas por quem ganha a confiança do agente e obtém acesso.
Uma Breve História do Desenvolvimento de Navegadores
No início da década de 1990, antes da internet se tornar parte do cotidiano, o Netscape Navigator surgiu, como um veleiro que abriu as portas para o mundo digital para milhões de usuários. Embora não tenha sido o primeiro navegador, foi o primeiro a realmente alcançar as massas e moldar a experiência da internet. Pela primeira vez, as pessoas podiam navegar na web com tanta facilidade através de uma interface gráfica, como se o mundo inteiro de repente tivesse se tornado acessível.
No entanto, a glória muitas vezes é efêmera. A Microsoft rapidamente reconheceu a importância dos navegadores e decidiu forçar a inclusão do Internet Explorer no sistema operacional Windows, tornando-o o navegador padrão. Essa estratégia, um verdadeiro "destruidor de plataformas", minou diretamente a dominância de mercado da Netscape. Muitos usuários não escolheram ativamente o IE; em vez disso, simplesmente o aceitaram como padrão. Aproveitando as capacidades de distribuição do Windows, o IE rapidamente se tornou o líder da indústria, enquanto a Netscape entrou em declínio.

No meio da adversidade, os engenheiros da Netscape escolheram um caminho radical e idealista — abriram o código-fonte do navegador e convocaram a comunidade de código aberto. Essa decisão foi como uma “abdicacão macedônia” no mundo da tecnologia, sinalizando o fim de uma velha era e o surgimento de novas forças. Esse código mais tarde se tornou a base do projeto de navegador Mozilla, inicialmente chamado de Phoenix (simbolizando renascimento), mas após várias disputas de marca registrada, foi finalmente renomeado para Firefox.
O Firefox não foi uma mera cópia do Netscape. Ele fez avanços na experiência do usuário, ecossistemas de plugins e segurança. Seu nascimento marcou a vitória do espírito de código aberto e injetou nova vitalidade em toda a indústria. Alguns descreveram o Firefox como o “sucessor espiritual” do Netscape, semelhante a como o Império Otomano herdou a glória em declínio de Bizâncio. Embora exagerada, a comparação é significativa.
No entanto, antes do Firefox ser oficialmente lançado, a Microsoft já havia lançado seis versões do Internet Explorer. Ao aproveitar seu timing antecipado e estratégia de empacotamento de sistema, o Firefox foi colocado em uma posição de recuperação desde o início, garantindo que essa corrida nunca fosse uma competição igual a partir da mesma linha.
Ao mesmo tempo, outro jogador inicial entrou silenciosamente no palco. Em 1994, o navegador Opera nasceu na Noruega, inicialmente apenas como um projeto experimental. Mas a partir da versão 7.0 em 2003, ele introduziu seu motor Presto desenvolvido internamente, pioneiro no suporte a CSS, layouts adaptativos, controle por voz e codificação Unicode. Embora sua base de usuários fosse limitada, ele consistentemente liderou a indústria tecnologicamente, tornando-se o "favorito dos geeks."
Nesse mesmo ano, a Apple lançou o navegador Safari — um ponto de virada significativo. Na época, a Microsoft havia investido 150 milhões de dólares em uma Apple em dificuldades para manter uma aparência de competição e evitar a análise antitruste. Embora o mecanismo de busca padrão do Safari fosse o Google desde o início, esse entrelaçamento com a Microsoft simbolizava as relações complexas e sutis entre os gigantes da internet: cooperação e competição, sempre entrelaçadas.
Em 2007, o IE7 foi lançado juntamente com o Windows Vista, mas a resposta do mercado foi morna. O Firefox, por outro lado, aumentou constantemente sua participação de mercado para cerca de 20%, graças a ciclos de atualização mais rápidos, um mecanismo de extensão mais amigável e um apelo natural para desenvolvedores. A dominância do IE começou a se afrouxar, e os ventos estavam mudando.
O Google, no entanto, adotou uma abordagem diferente. Embora estivesse planejando seu próprio navegador desde 2001, levou seis anos para convencer o CEO Eric Schmidt a aprovar o projeto. O Chrome fez sua estreia em 2008, construído sobre o projeto de código aberto Chromium e o mecanismo WebKit usado pelo Safari. Foi ridicularizado como um navegador "inchado", mas com a profunda expertise do Google em publicidade e construção de marcas, ele cresceu rapidamente.
A principal arma do Chrome não eram seus recursos, mas seu ciclo de atualização frequente (a cada seis semanas) e a experiência unificada entre plataformas. Em novembro de 2011, o Chrome superou o Firefox pela primeira vez, alcançando uma participação de mercado de 27%; seis meses depois, superou o IE, completando sua transformação de desafiador para líder dominante.
Enquanto isso, a internet móvel da China estava formando seu próprio ecossistema. O UC Browser da Alibaba ganhou popularidade no início da década de 2010, especialmente em mercados emergentes como Índia, Indonésia e China. Com seu design leve e recursos de compressão de dados que economizavam largura de banda, conquistou usuários em dispositivos de menor capacidade. Em 2015, sua participação no mercado global de navegadores móveis ultrapassou 17%, e na Índia chegou a atingir impressionantes 46%. Mas essa vitória não durou muito. À medida que o governo indiano intensificou as revisões de segurança de aplicativos chineses, o UC Browser foi forçado a deixar mercados-chave, perdendo gradualmente sua antiga glória.
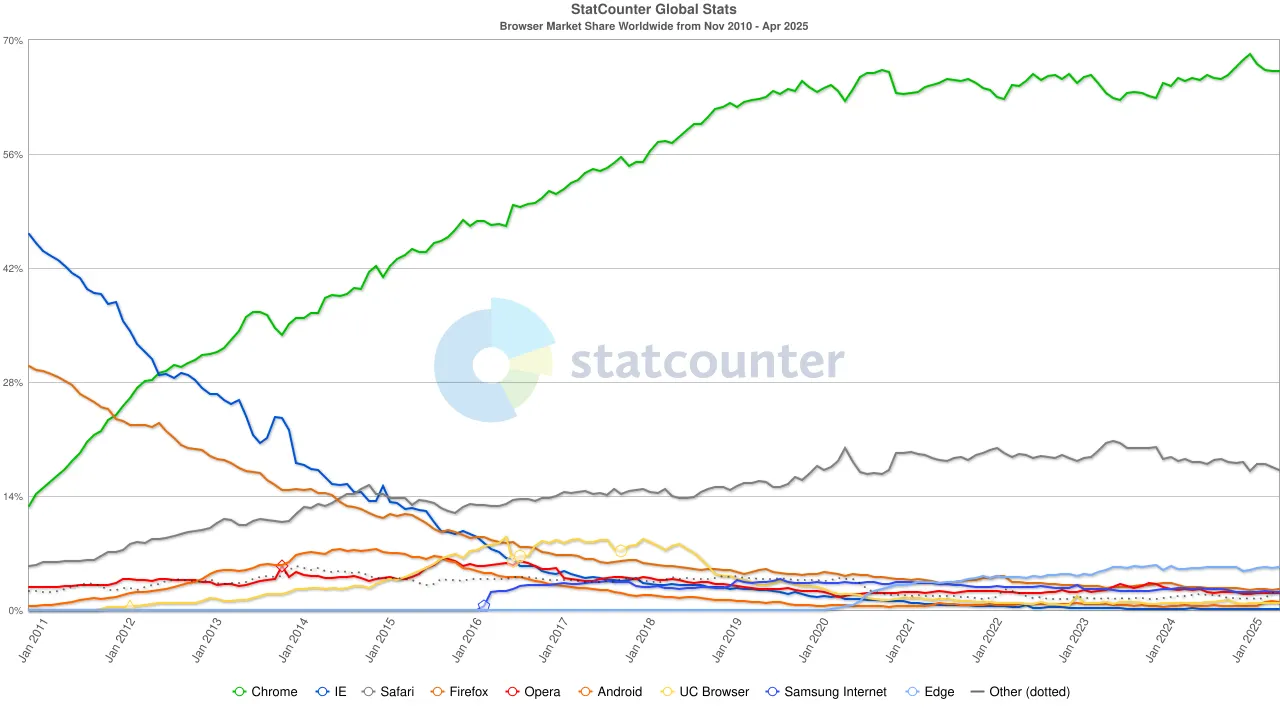
Na década de 2020, o domínio do Chrome estava firmemente estabelecido, com sua participação de mercado global estabilizando-se em cerca de 65%. Notavelmente, embora o mecanismo de busca do Google e o navegador Chrome pertençam à Alphabet, de uma perspectiva de mercado, eles representam duas hegemonias independentes — o primeiro controlando cerca de 90% do tráfego de busca global, e o último servindo como a "primeira janela" através da qual a maioria dos usuários acessa a internet.
Para manter essa estrutura de dupla-monopólio, o Google não poupou despesas. Em 2022, a Alphabet pagou à Apple aproximadamente US$ 20 bilhões apenas para manter o Google como o mecanismo de busca padrão no Safari. Analistas apontaram que esse gasto representou cerca de 36% da receita de publicidade de pesquisa que o Google ganhou com o tráfego do Safari. Em outras palavras, o Google estava efetivamente pagando uma "taxa de proteção" para defender seu fosso.
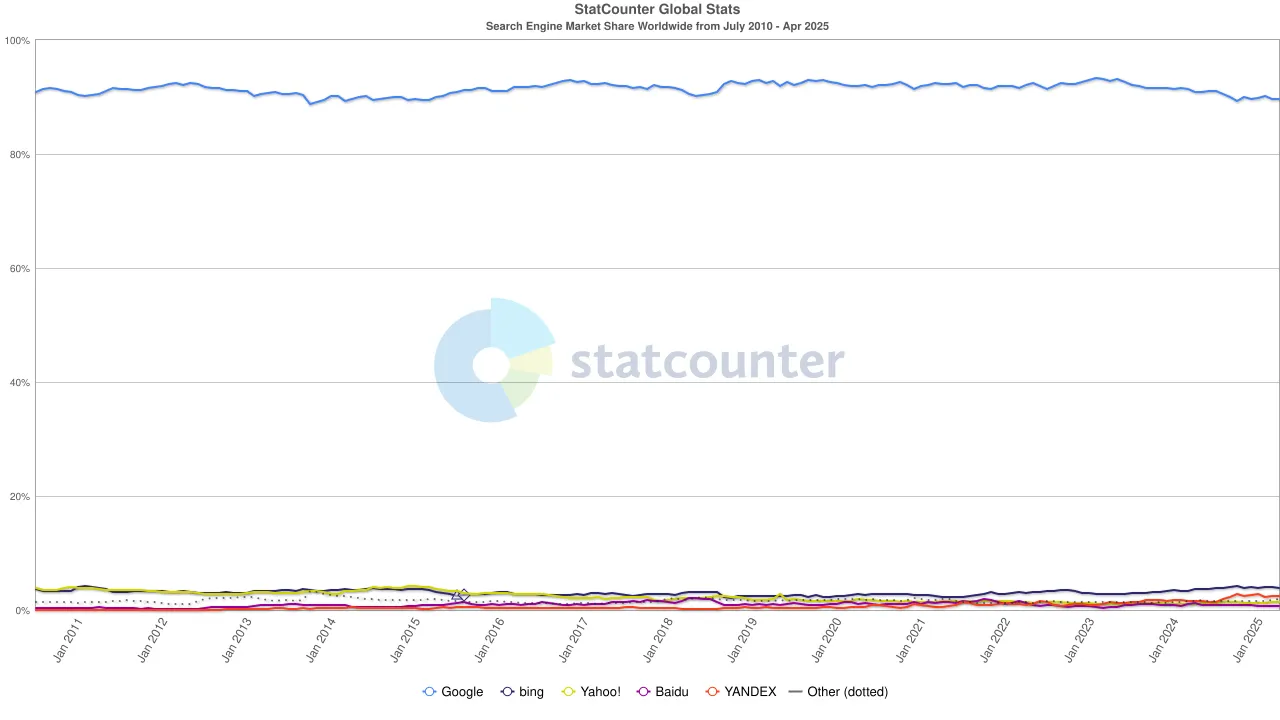
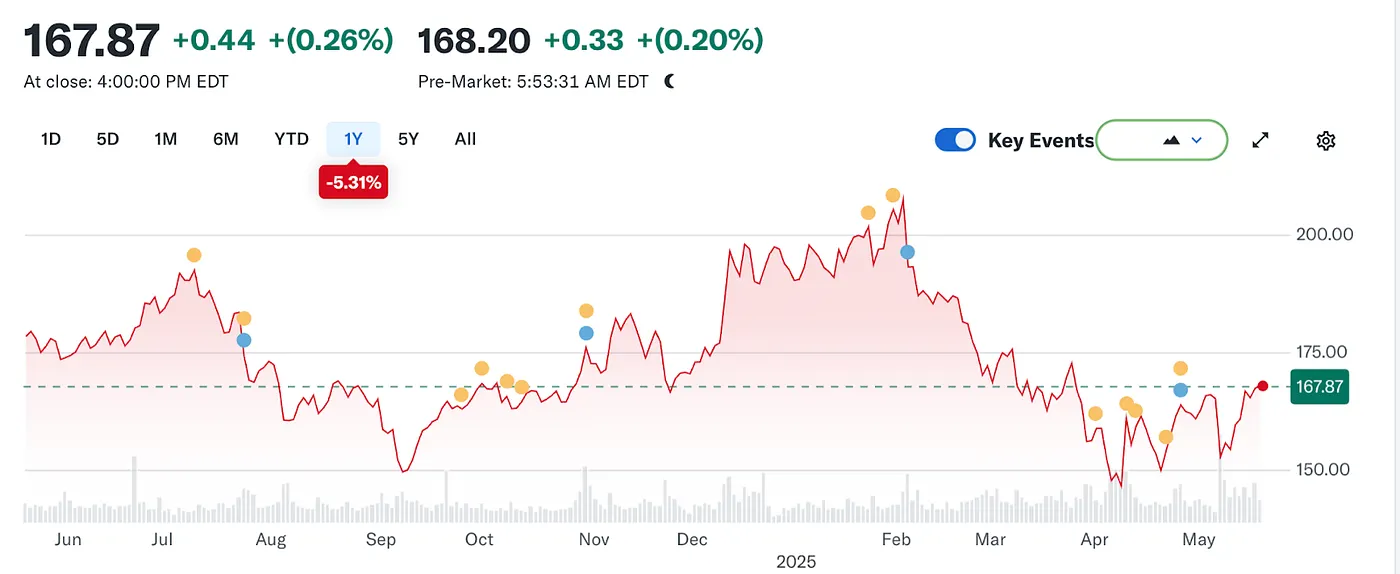
Mas a maré mudou mais uma vez. Com a ascensão dos grandes modelos de linguagem (LLMs), a busca tradicional começou a sentir o impacto. Em 2024, a participação da Google no mercado de busca caiu de 93% para 89%. Embora ainda dominasse, rachaduras começaram a aparecer. Ainda mais disruptivas eram os rumores de que a Apple poderia lançar seu próprio motor de busca alimentado por IA. Se a busca padrão do Safari mudasse para o próprio ecossistema da Apple, isso não apenas reformularia o cenário competitivo, mas também poderia abalar a própria fundação dos lucros da Alphabet. O mercado reagiu rapidamente: o preço das ações da Alphabet caiu de $170 para $140, refletindo não apenas o pânico dos investidores, mas também uma profunda inquietação sobre a direção futura da era da busca.
De Navigator a Chrome, dos ideais de código aberto à comercialização impulsionada por publicidade, dos navegadores leves aos assistentes de busca com IA, a batalha dos navegadores sempre foi uma guerra sobre tecnologia, plataformas, conteúdo e controle. O campo de batalha continua mudando, mas a essência nunca mudou: quem controla o Gate define o futuro.
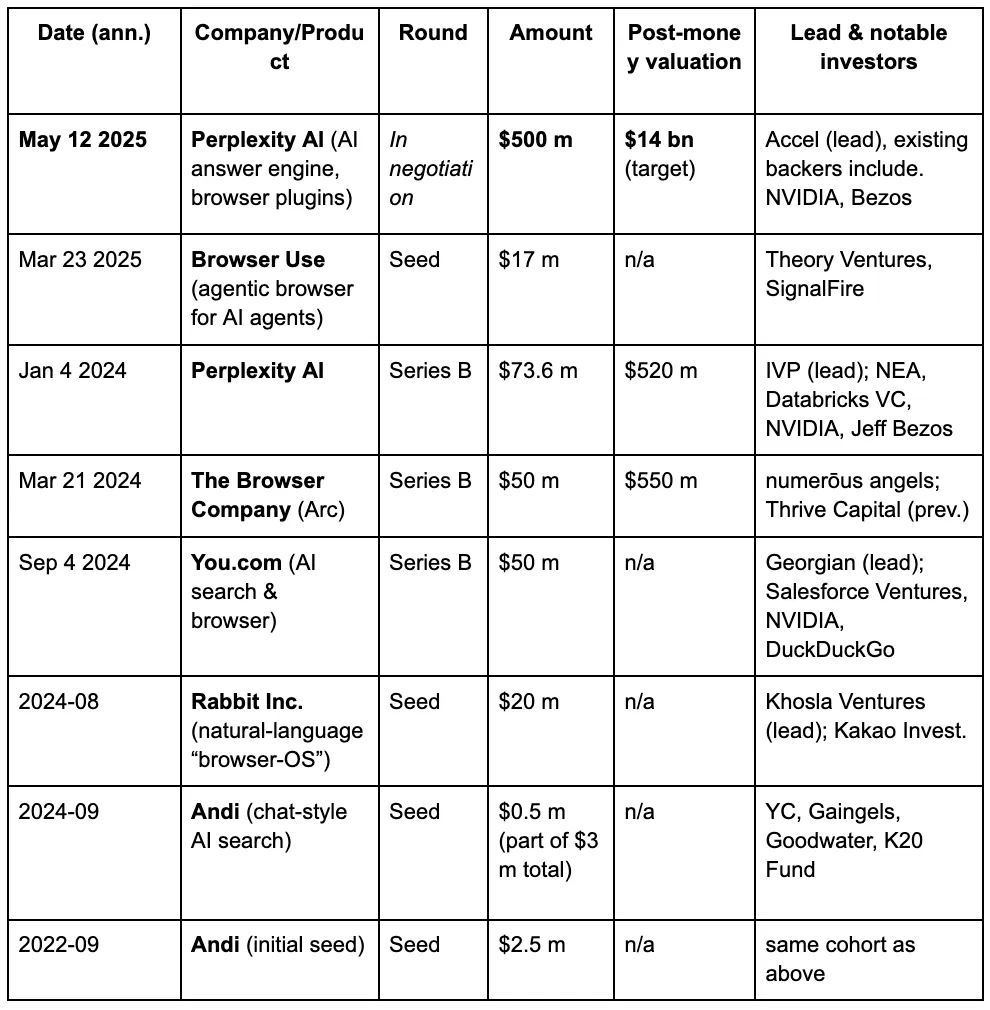
Aos olhos dos capitalistas de risco, uma terceira guerra dos navegadores está se desenrolando gradualmente, impulsionada pelas novas demandas que as pessoas impõem aos motores de busca na era dos LLMs e da IA. Abaixo estão os detalhes de financiamento de alguns projetos conhecidos na trilha de navegadores de IA.
A Arquitetura Desatualizada dos Navegadores Modernos
Quando se trata de arquitetura de navegador, a estrutura tradicional clássica é mostrada no diagrama abaixo:
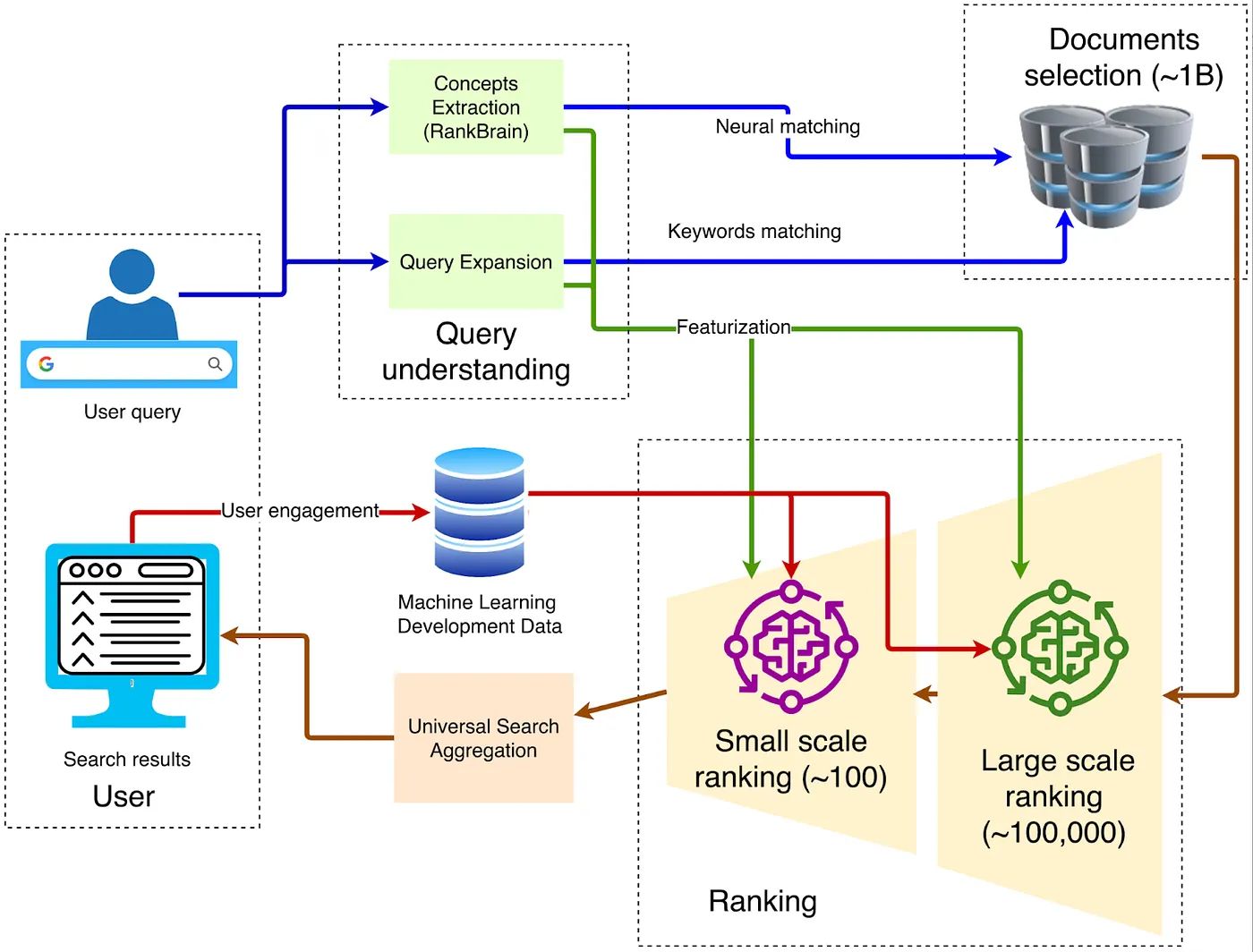
1. Cliente — Entrada Front-End
A consulta é enviada via HTTPS para o Front End do Google mais próximo, onde a descriptografia TLS, amostragem de QoS e roteamento geográfico são realizados. Se tráfego anormal for detectado (como ataques DDoS ou raspagem automatizada), limitação de taxa ou desafios podem ser aplicados nesta camada.
2. Compreensão da Consulta
A interface precisa entender o significado das palavras digitadas pelo usuário. Isso envolve três etapas:
Correção ortográfica neural, como transformar "recpie" em "recipe".
Expansão de sinônimos, por exemplo, expandindo "como consertar bicicleta" para incluir "reparar bicicleta".
A análise de intenção, que determina se a consulta é informativa, de navegação ou transacional, e em seguida atribui a solicitação vertical apropriada.
3. Recuperação de Candidatos
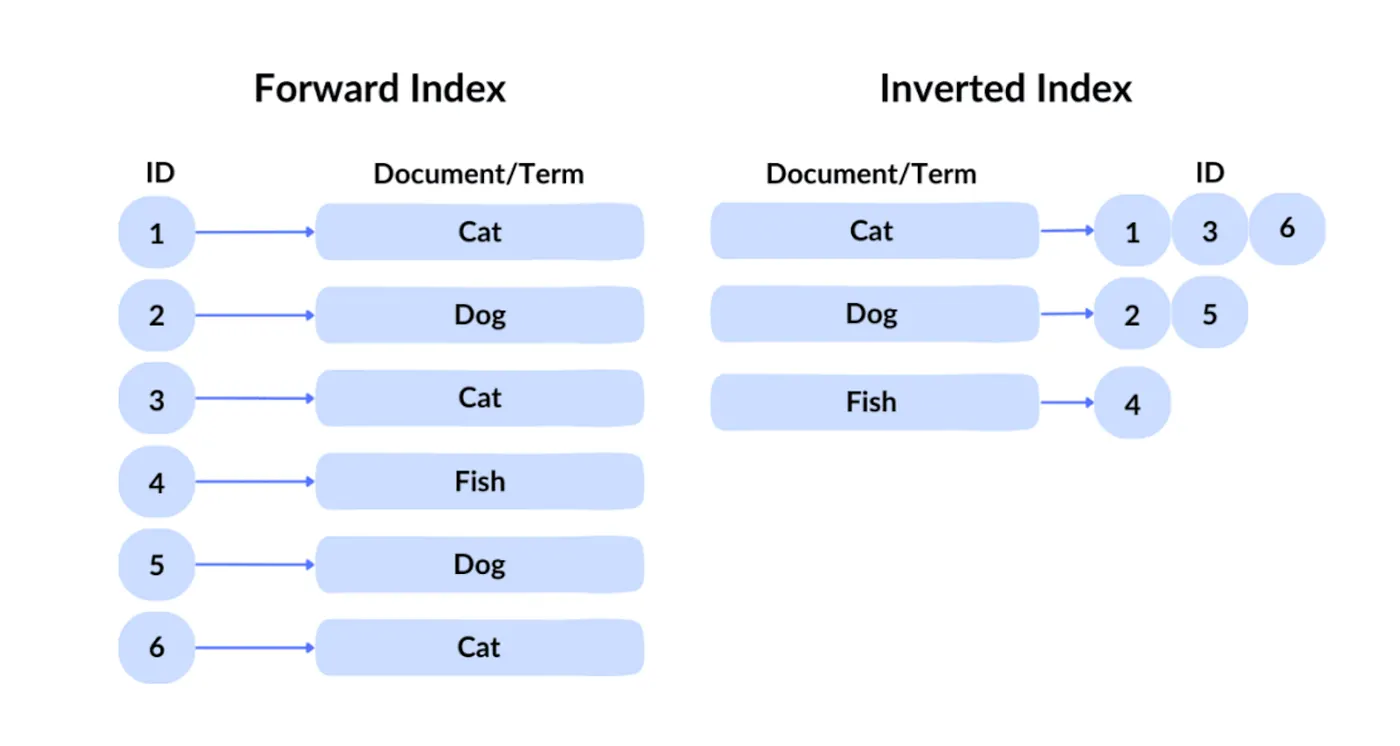
A tecnologia de consulta do Google é conhecida como um índice invertido. Em um índice direto, você recupera um arquivo dado seu ID. Mas como os usuários não podem conhecer os identificadores do conteúdo desejado em centenas de bilhões de arquivos, o Google usa o tradicional índice invertido, que consulta por conteúdo para identificar quais arquivos contêm as palavras-chave correspondentes.
Em seguida, o Google aplica a indexação vetorial para lidar com a busca semântica—ou seja, encontrar conteúdo semelhante em significado à consulta. Ele converte texto, imagens e outros conteúdos em vetores de alta dimensão (embeddings), e então busca com base na semelhança entre esses vetores. Por exemplo, se um usuário pesquisa “como fazer massa de pizza”, o mecanismo de busca pode retornar resultados relacionados a “guia de preparação de massa de pizza”, porque os dois são semanticamente semelhantes.
Por meio de indexação invertida e indexação vetorial, aproximadamente na ordem de centenas de milhares de páginas da web são filtradas na fase de triagem inicial.
4. Classificação em Múltiplas Etapas
O sistema geralmente utiliza milhares de recursos leves, como BM25, TF-IDF e pontuações de qualidade da página, para filtrar as centenas de milhares de páginas candidatas até cerca de 1.000, formando um conjunto inicial de candidatos. Esses sistemas são coletivamente chamados de motores de recomendação. Eles dependem de recursos massivos gerados a partir de várias entidades, incluindo comportamento do usuário, atributos da página, intenção de consulta e sinais contextuais. Por exemplo, o Google combina o histórico do usuário, feedback de outros usuários, semântica da página e significado da consulta, ao mesmo tempo em que considera elementos contextuais, como tempo (hora do dia, dia da semana) e eventos externos, como notícias de última hora.
5. Aprendizado Profundo para Classificação Primária
Na etapa inicial de recuperação, o Google utiliza tecnologias como RankBrain e Neural Matching para entender a semântica das consultas e filtrar os resultados mais relevantes de enormes coleções de documentos.
RankBrain, introduzido pelo Google em 2015, é um sistema de aprendizado de máquina projetado para entender melhor o significado das consultas dos usuários, especialmente consultas nunca vistas antes. Ele transforma consultas e documentos em representações vetoriais e calcula sua similaridade para encontrar os resultados mais relevantes. Por exemplo, para a consulta "como fazer massa de pizza", mesmo que nenhum documento contenha uma correspondência exata de palavras-chave, o RankBrain pode identificar conteúdo relacionado a "noções básicas de pizza" ou "preparação da massa."
O Neural Matching, lançado em 2018, foi projetado para capturar ainda mais a relação semântica entre consultas e documentos. Usando modelos de redes neurais, ele identifica relações difusas entre palavras para combinar melhor consultas com conteúdo da web. Por exemplo, para a consulta “por que o ventilador do meu laptop está tão barulhento”, o Neural Matching pode entender que o usuário pode estar buscando informações de solução de problemas sobre superaquecimento, acúmulo de poeira ou alta utilização da CPU—mesmo que esses termos não apareçam explicitamente na consulta.
6. Reclassificação Profunda: A Aplicação do BERT
Após a filtragem inicial de documentos relevantes, o Google aplica o BERT (Representações de Codificadores Bidirecionais de Transformadores) para refinar a classificação e garantir que os resultados mais relevantes apareçam no topo. O BERT é um modelo de linguagem pré-treinado baseado em Transformadores que pode entender as relações contextuais das palavras dentro das frases.
Na busca, o BERT é utilizado para reclassificar os documentos recuperados em estágios anteriores. Ele codifica conjuntamente consultas e documentos, calcula suas pontuações de relevância e, em seguida, reorganiza os documentos. Por exemplo, para a consulta "estacionar em uma colina sem meio-fio", o BERT pode interpretar corretamente o significado de "sem meio-fio" e retornar resultados aconselhando os motoristas a virarem suas rodas em direção ao acostamento, em vez de interpretar erroneamente como uma situação com meio-fio.
Para engenheiros de SEO, isso significa que eles devem estudar cuidadosamente os algoritmos de classificação e recomendação de aprendizado de máquina do Google para otimizar o conteúdo da web de maneira direcionada, ganhando assim maior visibilidade nos rankings de busca.
Por que a IA irá reformular os navegadores
Primeiro, precisamos esclarecer: por que o navegador como uma forma ainda precisa existir? Existe um terceiro paradigma além de agentes de IA e navegadores?
Acreditamos que a existência implica irreplicabilidade. Por que a inteligência artificial pode usar navegadores, mas não substituí-los completamente? Porque o navegador é uma plataforma universal. Não é apenas um ponto de entrada para ler dados, mas também um ponto de entrada geral para inserir dados. O mundo não pode apenas consumir informações — ele também deve produzir dados e interagir com sites. Portanto, navegadores que integram informações personalizadas dos usuários continuarão a existir amplamente.
Aqui está o ponto-chave: como um Gateway universal, o navegador não é apenas para ler dados; os usuários frequentemente precisam interagir com os dados. O navegador em si é um excelente repositório para armazenar impressões digitais dos usuários. Comportamentos de usuário mais complexos e ações automatizadas devem ser realizadas através do navegador. O navegador pode armazenar todas as impressões digitais comportamentais dos usuários, credenciais e outras informações privadas, permitindo a invocação sem confiança durante a automação. A interação com os dados pode evoluir para este padrão:
Usuário → chama Agente de IA → Navegador.
Em outras palavras, a única parte que poderia ser substituída está na tendência natural do mundo—em direção a maior inteligência, personalização e automação. Com certeza, essa parte pode ser gerenciada por agentes de IA. Mas os próprios agentes de IA não são bem adequados para carregar conteúdo personalizado do usuário, porque enfrentam múltiplos desafios em relação à segurança de dados e usabilidade. Especificamente:
O navegador é o repositório de conteúdo personalizado:
A maioria dos grandes modelos está hospedada na nuvem, com contextos de sessão dependentes do armazenamento do servidor, tornando difícil o acesso direto a senhas locais, carteiras, cookies e outros dados sensíveis.
O envio de todos os dados de navegação e pagamento para modelos de terceiros requer uma nova autorização do usuário; o DMA da UE e as leis de privacidade em nível estadual dos EUA exigem minimização de dados em todas as fronteiras.
O preenchimento automático de códigos de autenticação de dois fatores, a invocação de câmeras ou o uso de GPUs para inferência WebGPU deve ser feito dentro da sandbox do navegador.
O contexto dos dados é altamente dependente do navegador. Abas, cookies, IndexedDB, cache do Service Worker, credenciais de passkey e dados de extensões são todos armazenados dentro do navegador.
Mudanças Profundas nas Formas de Interação
Retornando ao tópico do início, nosso comportamento ao usar navegadores pode ser geralmente dividido em três categorias: leitura de dados, inserção de dados e interação com dados. Modelos de linguagem grandes (LLMs) já mudaram profundamente a eficiência e os métodos pelos quais lemos dados. A antiga prática de usuários pesquisando páginas da web por meio de palavras-chave agora parece desatualizada e ineficiente.
Quando se trata da evolução do comportamento de busca do usuário—seja o objetivo obter respostas resumidas ou clicar em páginas da web—muitos estudos já analisaram essa mudança.
Em termos de padrões de comportamento do usuário, um estudo de 2024 mostrou que nos EUA, de cada 1.000 consultas no Google, apenas 374 resultaram em um clique em uma página da web aberta. Em outras palavras, quase 63% eram comportamentos de "zero cliques". Os usuários se acostumaram a obter informações como clima, taxas de câmbio e cartões de conhecimento diretamente da página de resultados da pesquisa.
O que poderia realmente desencadear uma transformação massiva dos navegadores, no entanto, é a camada de interação de dados. No passado, as pessoas interagiam com os navegadores principalmente digitando palavras-chave—o nível máximo de entendimento que o próprio navegador poderia lidar. Agora, os usuários preferem cada vez mais usar linguagem natural completa para descrever tarefas complexas, como:
“Encontre voos diretos de Nova York para Los Angeles durante um determinado período.”
“Encontre um voo de Nova York para Xangai e depois para Los Angeles.”
Mesmo para os humanos, tais tarefas exigem muito tempo para visitar vários sites, reunir informações e comparar resultados. Mas essas Tarefas Agentes estão gradualmente sendo assumidas por agentes de IA.
Isso também está alinhado com a trajetória da história: automação e inteligência. As pessoas desejam liberar suas mãos, e agentes de IA inevitavelmente estarão profundamente incorporados aos navegadores. Os navegadores futuros devem ser projetados com a automação total em mente, especialmente considerando:
Como equilibrar a experiência de leitura para humanos com a interpretabilidade das máquinas para agentes de IA.
Como garantir que uma única página da web atenda tanto ao usuário final quanto ao modelo de agente.
Somente atendendo a ambos os requisitos de design é que os navegadores podem realmente se tornar portadores estáveis para que os agentes de IA executem tarefas.
Em seguida, iremos nos concentrar em cinco projetos proeminentes—Browser Use, Arc (The Browser Company), Perplexity, Brave e Donut. Esses projetos representam direções futuras para a evolução do navegador de IA, bem como seu potencial para integração nativa dentro de contextos Web3 e cripto.
Do ponto de vista da psicologia do usuário, uma pesquisa de 2023 mostrou que 44% dos entrevistados consideravam os resultados orgânicos regulares mais confiáveis do que os trechos em destaque. Pesquisas acadêmicas também descobriram que, em casos de controvérsia ou falta de uma única verdade autoritativa, os usuários preferem páginas de resultados que contenham links de múltiplas fontes.
Em outras palavras, enquanto uma parte dos usuários não confia totalmente em resumos gerados por IA, uma porcentagem significativa do comportamento já mudou para “zero-clique”. Portanto, os navegadores de IA ainda precisam explorar o paradigma de interação certo—especialmente na área de leitura de dados. Como o problema da alucinação em grandes modelos ainda não foi totalmente resolvido, muitos usuários ainda lutam para confiar completamente em resumos de conteúdo gerados automaticamente. Nesse aspecto, incorporar grandes modelos em navegadores não requer necessariamente uma transformação disruptiva. Em vez disso, requer simplesmente melhorias incrementais em precisão e controlabilidade—um processo que já está em andamento.
Uso do Navegador
Esta é precisamente a lógica central por trás do imenso financiamento recebido pela Perplexity e pelo Browser Use. Em particular, o Browser Use surgiu como a segunda oportunidade de inovação mais promissora para o início de 2025, com certeza e forte potencial de crescimento.

O uso de navegadores construiu uma verdadeira camada semântica, com seu foco principal em criar uma arquitetura de reconhecimento semântico para a próxima geração de navegadores.
O Browser Use reinterpretou o tradicional “DOM = uma árvore de nós para humanos verem” para “DOM Semântico = uma árvore de instruções para LLMs lerem.” Isso permite que os agentes cliquem, preencham e façam upload com precisão, sem depender de “coordenadas de pixel.” Em vez de usar OCR visual ou Selenium baseado em coordenadas, essa abordagem segue a rota de “texto estruturado → chamadas de função,” tornando a execução mais rápida, economizando tokens e reduzindo erros. O TechCrunch descreveu como “a camada de cola que permite que a IA realmente entenda as páginas da web.” Em março, o Browser Use fechou uma rodada de investimento semente de $17 milhões, apostando nessa inovação fundamental.
Aqui está como funciona:
Após o HTML ser renderizado, ele forma uma árvore DOM padrão. O navegador então deriva uma árvore de acessibilidade, que fornece rótulos de “papéis” e “estados” mais ricos para leitores de tela.
Cada elemento interativo (botão, entrada, etc.) é abstraído em um trecho JSON com metadados como função, visibilidade, coordenadas e ações executáveis.
A página inteira é traduzida em uma lista achatada de nós semânticos, que o LLM pode ler em um único prompt do sistema.
O LLM gera instruções de alto nível (por exemplo, clique(node_id="btn-Checkout")), que são então reproduzidas no navegador real.
O blog oficial descreve esse processo como "transformar interfaces de websites em texto estruturado que LLMs podem analisar."
Além disso, se este padrão for adotado pelo W3C, ele pode resolver significativamente o problema de entrada no navegador. Em seguida, veremos a carta aberta e os estudos de caso da The Browser Company para explicar melhor por que sua abordagem é falha.
Arco
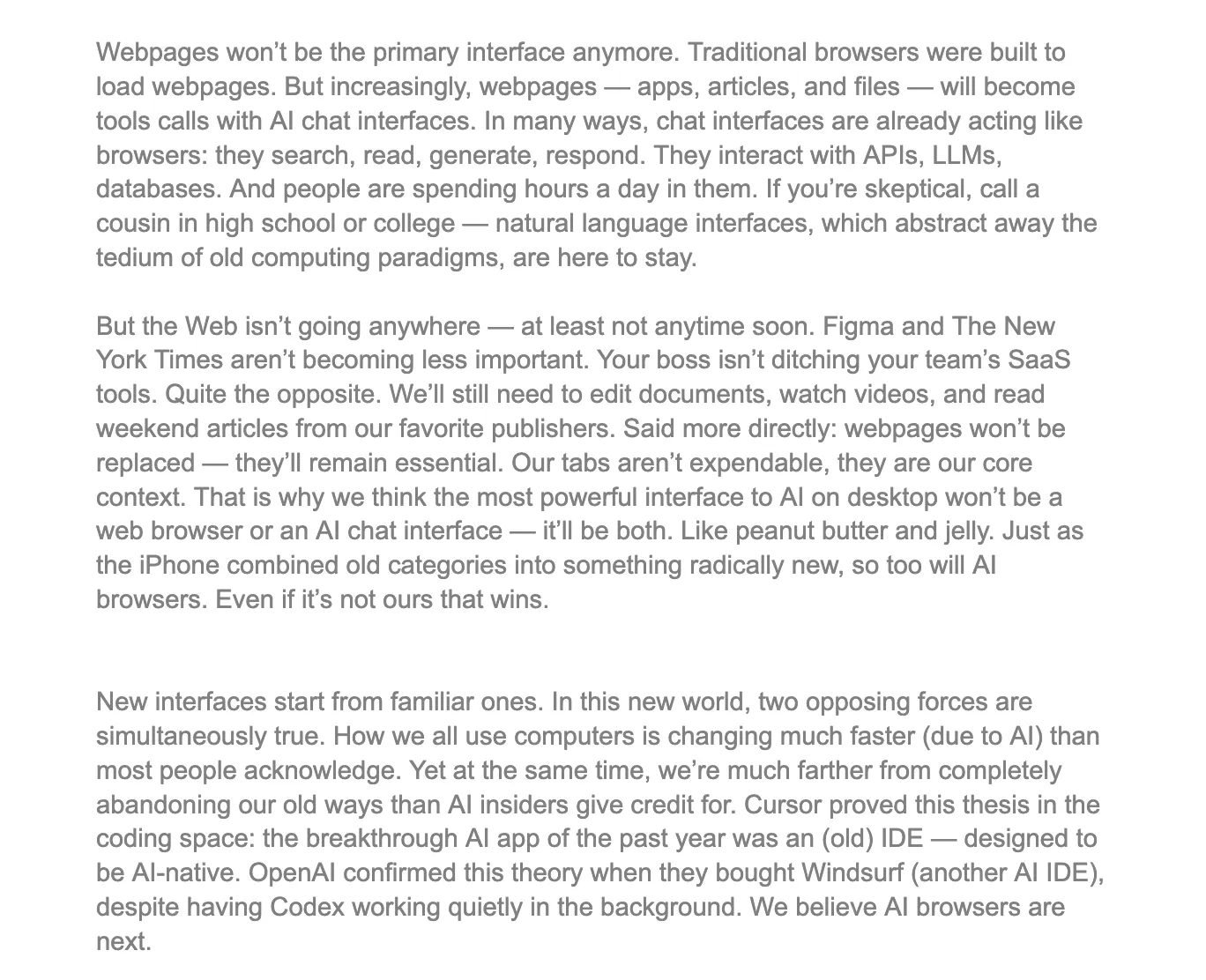
A Browser Company (a empresa-mãe da Arc) declarou em sua carta aberta que o navegador Arc entrará em modo de manutenção regular, enquanto a equipe mudará seu foco para o desenvolvimento do DIA, um navegador totalmente orientado para IA. Na carta, eles também admitiram que o caminho de implementação específico para o DIA ainda não foi determinado. Ao mesmo tempo, a equipe delineou várias previsões sobre o futuro do mercado de navegadores.
Com base nessas previsões, acreditamos ainda que, se o atual cenário de navegadores realmente for ser disruptivo, a chave está em mudar o lado de saída da interação.
Abaixo estão três das previsões sobre o futuro do mercado de navegadores compartilhadas pela equipe Arc.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Primeiro, a equipe do Arc acredita que as páginas da web não serão mais a principal interface para interação. Admitidamente, esta é uma afirmação ousada e desafiadora, e também é a principal razão pela qual permanecemos céticos em relação às reflexões de seu fundador. Na nossa visão, essa perspectiva subestima significativamente o papel do navegador, e destaca a questão chave que a equipe ignorou ao explorar o caminho do navegador de IA.
Modelos grandes se destacam na captura de intenções—por exemplo, entender instruções como “ajude-me a reservar um voo.” No entanto, eles permanecem insuficientes quando se trata de densidade de informação. Quando um usuário precisa de algo como um painel, um caderno estilo Bloomberg Terminal, ou uma tela visual como o Figma, nada pode superar uma página da web finamente ajustada com precisão em nível de pixel. A ergonomia de cada produto—gráficos, funcionalidade de arrastar e soltar, teclas de atalho—não é uma decoração superficial, mas afordâncias essenciais que comprimem a cognição. Essas capacidades não podem ser replicadas por interações conversacionais simples. Tomando Gate.com como exemplo: se um usuário deseja executar uma ação de investimento, confiar exclusivamente na conversa com IA está longe de ser suficiente, uma vez que os usuários dependem fortemente de entrada estruturada, precisão e apresentação clara da informação.
O roadmap da equipe Arc contém uma falha fundamental: ele não consegue distinguir claramente que "interação" é composta por duas dimensões—entrada e saída. Do lado da entrada, sua visão tem alguma validade em certos cenários, já que a IA pode, de fato, melhorar a eficiência das interações em estilo de comando. Mas do lado da saída, sua suposição é claramente desequilibrada, ignorando o papel central do navegador na apresentação de informações e experiências personalizadas. Por exemplo, o Reddit tem seu próprio layout e arquitetura de informações únicos, enquanto o AAVE possui uma interface e estrutura completamente diferentes. Como uma plataforma que armazena simultaneamente dados altamente privados e renderiza interfaces de produtos diversas, o navegador tem uma substitutibilidade limitada do lado da entrada, enquanto sua complexidade e natureza não padronizada do lado da saída tornam ainda mais difícil a interrupção.
Por outro lado, os navegadores de IA atuais concentram-se principalmente na camada de "resumo de saída": resumindo páginas, extraindo informações, gerando conclusões. Isso não é suficiente para representar um desafio fundamental para navegadores ou sistemas de busca convencionais como o Google — apenas reduz a participação de mercado para resumos de busca.
Portanto, a única tecnologia que poderia realmente abalar a participação de mercado de 66% do Chrome está destinada a não ser "o próximo Chrome." Para alcançar uma verdadeira disrupção, o modelo de renderização dos navegadores deve ser fundamentalmente reestruturado para se adaptar às necessidades de interação da era do Agente de IA, especialmente em termos de design da arquitetura do lado de entrada. É por isso que achamos o caminho técnico adotado pelo Browser Use muito mais convincente—ele se concentra em mudanças estruturais no mecanismo subjacente dos navegadores. Uma vez que qualquer sistema atinja um design "atômico" ou "modular", a programabilidade e a composabilidade derivadas disso desbloqueiam um potencial disruptivo. Esta é exatamente a direção que o Browser Use está perseguindo hoje.
Em resumo, a operação de agentes de IA ainda depende fortemente da existência de navegadores. Os navegadores não são apenas os principais repositórios de dados personalizados complexos, mas também as interfaces de renderização universais para diversas aplicações, e assim continuarão a servir como o núcleo do Gate para interação no futuro. À medida que os agentes de IA se tornam profundamente integrados aos navegadores para completar tarefas fixas, eles interagirão com os dados dos usuários e aplicações específicas principalmente pelo lado da entrada. Por essa razão, o modelo de renderização atual dos navegadores deve ser inovado para alcançar a máxima compatibilidade e adaptabilidade com os agentes de IA—permitindo, em última análise, que eles capturem aplicações de forma mais eficaz.
Perplexidade
A Perplexity é um motor de busca de IA renomado por seu sistema de recomendação. Sua última avaliação disparou para $14 bilhões, quase um aumento de cinco vezes em relação a $3 bilhões em junho de 2024. Agora, ela lida com mais de 400 milhões de consultas de busca por mês. Apenas em setembro de 2024, processou cerca de 250 milhões de consultas, marcando um aumento de oito vezes ano a ano no volume de buscas dos usuários, com mais de 30 milhões de usuários ativos mensais.
Seu principal recurso é a capacidade de resumir páginas em tempo real, proporcionando uma grande vantagem no acesso a informações atualizadas. No início deste ano, a Perplexity começou a construir seu próprio navegador nativo, Comet. A empresa descreve o Comet como um navegador que não apenas "exibe" páginas da web, mas também "pensa" sobre elas. Oficialmente, eles afirmam que ele integrará o mecanismo de respostas da Perplexity profundamente dentro do próprio navegador, seguindo uma abordagem de "máquina inteira" que lembra a filosofia de Steve Jobs: integrando profundamente as tarefas de IA no nível fundamental do navegador, em vez de apenas construir plugins na barra lateral.
Com respostas concisas apoiadas por citações, a Comet pretende substituir os tradicionais "dez links azuis" e competir diretamente com o Chrome.
Mas a Perplexity ainda precisa resolver dois problemas centrais: altos custos de busca e baixas margens de lucro de usuários marginais. Embora a Perplexity atualmente lidere no campo de busca por IA, o Google anunciou em sua conferência I/O de 2025 uma reforma inteligente em grande escala de seus produtos principais. Para navegadores, o Google lançou uma nova experiência de aba do navegador chamada AI Model, que integra Overview, Deep Research e futuras capacidades Agentic. Toda a iniciativa é chamada de "Projeto Mariner."
O Google está avançando ativamente em sua transformação de IA, o que significa que a imitação superficial de recursos—como Visão Geral, Pesquisa Profunda ou Agências—dificilmente representará uma ameaça real. O que poderia realmente estabelecer uma nova ordem em meio ao caos é reconstruir a arquitetura do navegador do zero, incorporando profundamente modelos de linguagem de grande porte (LLMs) no núcleo do navegador e transformando fundamentalmente os métodos de interação.
Brave
O Brave é um dos navegadores mais antigos e bem-sucedidos dentro da indústria cripto. Construído na arquitetura Chromium, é compatível com extensões da Google Store. O Brave atrai usuários com um modelo baseado em privacidade e na obtenção de tokens através da navegação. Seu caminho de desenvolvimento demonstra um certo potencial de crescimento. No entanto, do ponto de vista do produto, embora a privacidade seja de fato importante, a demanda continua concentrada em grupos específicos de usuários. Para o público mais amplo, a conscientização sobre privacidade ainda não se tornou um fator de decisão mainstream. Portanto, tentar confiar apenas nesse recurso para desestabilizar gigantes existentes é improvável que tenha sucesso.
Atualmente, o Brave alcançou 82,7 milhões de usuários ativos mensais (MAU) e 35,6 milhões de usuários ativos diários (DAU), detendo uma participação de mercado de cerca de 1% a 1,5%. Sua base de usuários apresentou crescimento constante: de 6 milhões em julho de 2019, para 25 milhões em janeiro de 2021, para 57 milhões em janeiro de 2023, e até fevereiro de 2025, superou 82 milhões. Sua taxa de crescimento anual composta permanece em dois dígitos.
O Brave lida com aproximadamente 1,34 bilhão de consultas de pesquisa por mês, o que representa cerca de 0,3% do volume do Google.
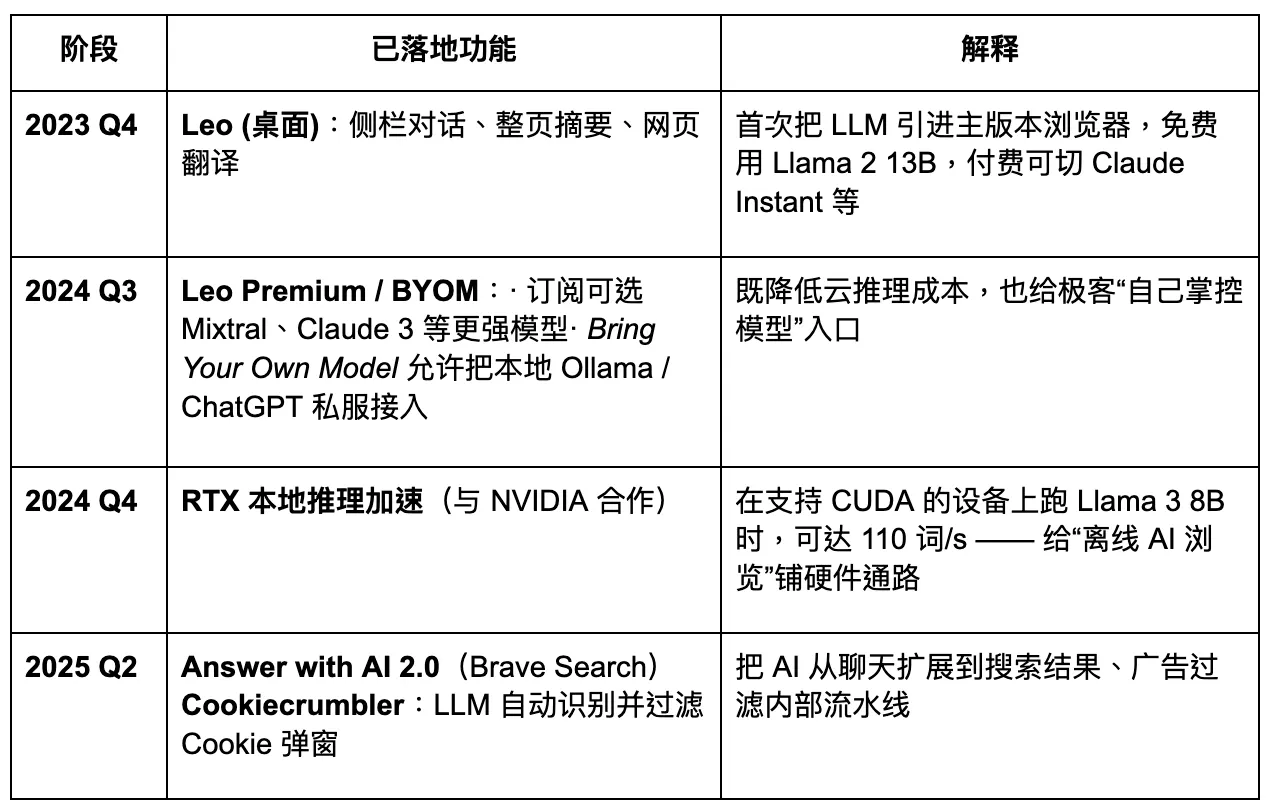
O Brave está planejando se atualizar para um navegador de IA com foco em privacidade. No entanto, seu acesso limitado aos dados dos usuários reduz o nível de personalização possível para grandes modelos, o que, por sua vez, dificulta a iteração rápida e precisa de produtos. Na próxima era do Navegador Agentic, o Brave pode manter uma participação estável entre grupos específicos de usuários focados em privacidade, mas será difícil para ele se tornar um jogador dominante. Seu assistente de IA, Leo, funciona mais como uma melhoria de plugin—oferecendo algumas capacidades de resumo de conteúdo, mas sem uma estratégia clara para uma mudança total em direção aos agentes de IA. A inovação na interação permanece insuficiente.
Donut
Recentemente, a indústria de criptomoedas também fez progressos no campo dos Navegadores Agentes. O projeto em estágio inicial Donut arrecadou US$ 7 milhões em uma rodada de pré-seed, liderada pela Hongshan (Sequoia China), HackVC e Bitkraft Ventures. O projeto ainda está em sua fase conceitual inicial, com a visão de alcançar "Descoberta - Tomada de Decisão - e Execução nativa em cripto" como uma capacidade integrada.
A direção central é combinar caminhos de execução automatizados nativos de cripto. Como a a16z previu, os agentes podem substituir os motores de busca como o principal Gate de tráfego no futuro. Os empreendedores não competirão mais em torno dos algoritmos de classificação do Google, mas sim lutarão pelo tráfego e conversões que vêm da execução dos agentes. A indústria já nomeou essa tendência de “AEO” (Otimização de Motor de Resposta / Agente), ou até mesmo mais, “ATF” (Cumprimento de Tarefas Agentes)—onde o objetivo não é mais otimizar classificações de busca, mas servir diretamente modelos inteligentes que podem completar tarefas para os usuários, como fazer pedidos, reservar passagens ou escrever cartas.
Para Empreendedores
Primeiro, deve-se reconhecer: o próprio navegador continua sendo o maior "Gateway" não reconstruído no mundo da internet. Com cerca de 2,1 bilhões de usuários de desktop e mais de 4,3 bilhões de usuários móveis globalmente, ele atua como o transportador comum para entrada de dados, comportamento interativo e armazenamento de impressões digitais personalizadas. A razão para sua persistência não é inércia, mas a dualidade inerente ao navegador: ele é tanto o ponto de entrada para leitura de dados quanto o ponto de saída para ações de escrita.
Portanto, para os empreendedores, o verdadeiro potencial disruptivo não reside na otimização da camada de “saída de página”. Mesmo que alguém pudesse replicar funções de visão geral de IA semelhantes ao Google em uma nova aba, isso ainda seria apenas uma iteração na camada de plugin, não uma mudança de paradigma fundamental. O verdadeiro avanço está do lado da “entrada” — como fazer com que os agentes de IA chamem ativamente seu produto para completar tarefas específicas. Isso determinará se um produto pode se integrar ao ecossistema de agentes, capturar tráfego e compartilhar na distribuição de valor.
Na era da busca, a competição era sobre cliques; na era dos agentes, é sobre chamadas.
Se você é um empreendedor, deve reimaginar seu produto como um componente de API—algo que um agente inteligente não apenas pode entender, mas também invocar. Isso requer que você considere três dimensões desde o início do design do produto:
1. Padronização da Estrutura da Interface: Seu produto é chamável?
A capacidade de um agente de invocar um produto depende de se sua estrutura de informações pode ser padronizada e abstraída em um esquema claro. Por exemplo, ações chave como registro de usuário, realização de pedidos ou envio de comentários podem ser descritas através de uma estrutura DOM semântica ou mapeamento JSON? O sistema fornece uma máquina de estados para que o agente possa replicar de forma confiável os fluxos de trabalho do usuário? As interações do usuário na página podem ser scriptadas? O produto oferece webhooks ou endpoints de API estáveis?
É exatamente por isso que o Browser Use conseguiu arrecadar fundos—transformou o navegador de um renderizador HTML plano em uma árvore semântica chamada por LLMs. Para os empreendedores, adotar uma filosofia de design semelhante em produtos web significa se preparar para uma adaptação estruturada na era dos agentes de IA.
2. Identidade e Acesso: Você pode ajudar os agentes a "ultrapassar a barreira de confiança"?
Para que os agentes completem transações ou chamem funções de pagamento e ativos, eles precisam de um intermediário confiável—você poderia se tornar esse intermediário? Os navegadores naturalmente têm a capacidade de ler o armazenamento local, acessar carteiras, lidar com CAPTCHAs e integrar autenticação de dois fatores. Isso os torna mais adequados do que modelos hospedados na nuvem para executar tarefas. Isso é especialmente verdadeiro na Web3, onde as interfaces de interação com ativos não são padronizadas. Sem "identidade" ou "habilidade de assinatura", um agente não pode avançar.
Para os empreendedores de criptomoedas, isso abre um espaço em branco altamente imaginativo: a "MCP (Plataforma de Múltiplas Capacidades) do mundo blockchain." Isso pode assumir a forma de uma camada de comando universal (permitindo que agentes chamem Dapps), um conjunto de interface de contrato padronizada, ou até mesmo uma carteira local leve + hub de identidade.
3. Repensando os Mecanismos de Tráfego: O futuro não é SEO, mas AEO / ATF.
No passado, você tinha que vencer o algoritmo do Google; agora você precisa estar incorporado nas cadeias de tarefas dos agentes de IA. Isso significa que seu produto deve ter uma granularidade de tarefas clara: não uma "página", mas uma série de unidades de capacidade chamáveis. Isso também significa começar a otimizar para a Otimização do Motor de Agente (AEO) ou se adaptar ao Cumprimento de Tarefas Agenciais (ATF). Por exemplo, o processo de registro pode ser simplificado em etapas estruturadas? O preço pode ser obtido através de uma API? O inventário está acessível em tempo real?
Você pode até precisar se adaptar a diferentes sintaxes de chamada em diferentes frameworks LLM—já que OpenAI e Claude, por exemplo, têm preferências diferentes para chamadas de função e uso de ferramentas. O Chrome é o terminal do velho mundo, não o Gate para o novo. Os projetos do futuro não reconstruirão navegadores, mas farão com que os navegadores sirvam agentes—construindo pontes para a nova geração de "fluxos de instrução."
O que você precisa construir é a "linguagem de interface" através da qual os agentes chamam seu mundo.
O que você precisa para ganhar é um lugar na cadeia de confiança dos sistemas inteligentes.
O que você precisa construir é um "castelo de API" no próximo paradigma de busca.
Se o Web2 capturou a atenção do usuário por meio da interface do usuário, então a era do Web3 + Agente de IA capturará a intenção de execução do agente por meio de cadeias de chamadas.
Aviso Legal
Este conteúdo não constitui uma oferta, solicitação ou recomendação. Você deve sempre buscar aconselhamento profissional independente antes de tomar qualquer decisão de investimento. Observe que a Gate e/ou Gate Ventures podem restringir ou proibir alguns ou todos os serviços em regiões restritas. Por favor, leia o contrato de usuário aplicável para mais detalhes.
Sobre Gate Ventures
Gate Ventures é a divisão de capital de risco da Gate, focando em investimentos em infraestrutura descentralizada, ecossistemas e aplicações—tecnologias que irão remodelar o mundo na era Web 3.0. A Gate Ventures trabalha com líderes da indústria global para capacitar equipes e startups com pensamento inovador e capacidades para redefinir a forma como a sociedade e as finanças interagem.
Website: https://www.gate.com/ventures
Compartilhar
Conteúdo
TL;DR
Uma Breve História do Desenvolvimento de Navegadores
A Arquitetura Desatualizada dos Navegadores Modernos
Por que a IA vai reformular os navegadores
Mudanças Profundas nas Formas de Interação
Uso do Navegador
Arco
Perplexidade
Brave
Donut
Para Empreendedores
Isenção de responsabilidade
Sobre Gate Ventures

