Open Source Race: "Linux Moment" AI Big Model Tiba
Lihatlah masa depan model besar AI dari sejarah pengembangan open source benchmark Linux.
Ditulis oleh: Song Jiaji, Sun Shuang
Tak lama setelah ChatGPT dirilis, Meta open source model bahasa besar seperti GPT LLaMA. Sejak itu, beberapa model besar seperti Alpaca, Vicuna, dan Koala telah lahir. Mereka telah mencapai kinerja yang mengesankan pada skala model dan harganya jauh lebih rendah daripada ChatGPT. Ini telah menyebabkan orang dalam industri khawatir bahwa “Baik Google maupun OpenAI tidak memiliki parit, dan ambang model besar dilanggar oleh sumber terbuka, dan mereka akan diganti jika tidak bekerja sama.” Pasar modal juga memperhatikan pola persaingan model besar di masa depan. Apakah model kecil tidak lagi membutuhkan banyak daya komputasi? Peran apa yang dimainkan data di dalamnya? …Laporan ini mencoba menganalisis titik temu gelombang model bahasa besar open source ini, meninjau riwayat pengembangan benchmark open source Linux, dan menjawab pertanyaan-pertanyaan ini.
** Poin umum 1: Mulai dengan sumber terbuka. **Open source ≠ gratis Model bisnis open source paling tidak mencakup: 1. Monetisasi melalui layanan. Salah satu contohnya adalah Red Hat, sebuah perusahaan layanan Linux yang pernah terdaftar dan kemudian diakuisisi oleh IBM. Perusahaan bersedia membayar untuk dukungan teknis yang lebih stabil dan tepat waktu. 2. Direalisasikan dengan biaya lisensi. Android adalah open source, tetapi Google membebankan biaya lisensi kepada produsen di UE untuk menggunakan Android Google suite. 3. Pengembangan lisensi, standar, dan sistem evaluasi kemampuan merupakan katalisator untuk memperdalam komersialisasi model besar open source. Perjanjian lisensi yang diadopsi oleh gelombang model besar open source ini terutama adalah Apache 2.0 dan MIT, yang tidak melarang penggunaan komersial, dan tidak melarang pengguna untuk memodifikasi model dan kemudian menutup sumbernya, yang membantu perusahaan menerapkan model besar tersebut.
** Poin umum 2: lebih sedikit parameter dan miniaturisasi. **Dibandingkan dengan model ultra-besar GPT3+ dengan 100 miliar parameter, parameter gelombang model besar open source ini umumnya berada pada level satu miliar hingga sepuluh miliar. Saat ini, tidak ada sistem evaluasi kinerja model berskala besar yang sistematis, dan hanya beberapa tugas yang memiliki standar penilaian dengan kredibilitas yang kuat. Di antara model open source besar, Vicuna juga lebih mumpuni, dan dapat mencapai kinerja GPT4 92% dalam beberapa tugas. Secara umum, sistem OpenAI GPT masih yang terbaik, tetapi biaya pelatihannya tinggi dan sulit untuk direproduksi. Model besar open source mencapai biaya pelatihan rendah dan kinerja tinggi dengan bantuan kumpulan data pelatihan pengenal yang lebih besar, DeepSpeed, RLHF, dll., dan hambatan untuk model besar di bawah model super besar menghilang.
** Poin umum 3: Kumpulan data sangat mementingkan instruksi manusia dan tersedia secara komersial. **Faktor penting untuk peningkatan substansial ChatGPT dibandingkan dengan GPT3 adalah penggunaan RLHF (reinforcement learning based on human feedback), yaitu, selama pelatihan, gunakan jawaban buatan manusia dan urutkan konten buatan AI untuk memungkinkan AI “menyelaraskan” preferensi manusia. LLaMA tidak menggunakan fine-tuning instruksi, tetapi sejumlah besar model besar setelah penggunaan LLaMA dan set data instruksi open source, dan secara bertahap menjelajahi set data instruksi yang dibuat sendiri alih-alih menggunakan OpenAI dengan batasan komersial, yang selanjutnya mengurangi ambang batas untuk mereproduksi GPT dan memperluas ketersediaan komersial.
**Bagaimana cara melihat model besar open source selanjutnya? **Berdiri dalam gelombang model besar sumber terbuka, kami telah memperhatikan dua tren: 1) Integrasi dengan multimodalitas, VisualGLM-6B Universitas Tsinghua adalah versi peningkatan multimodal dari model bahasa sumber terbuka ChatGLM yang terkenal, kami percaya bahwa itu dapat Fitur penyebaran lokal berdasarkan kartu grafis kelas konsumen adalah tren umum. 2) Model open source + edge computing mempromosikan komersialisasi AI Model konsultasi medis Cina Universitas Harbin “Huatuo” dan penggunaannya dalam e-commerce lintas batas adalah contohnya.
Saran Investasi: Kami yakin bahwa tampilan pada model besar harus dilihat secara tepat waktu dan berlapis-lapis. 1. Dalam jangka pendek, model super besar GPT OpenAI masih mengungguli model skala besar sumber terbuka lainnya.Oleh karena itu, kita harus fokus pada Microsoft, yang memiliki kerja sama mendalam dengannya dalam ekuitas dan produk, Apple, yang dapat diperoleh Bagi hasil ChatGPTiosApp, dan penyedia layanan daya komputasi model super besar Nvidia, dll.; 2. Dalam jangka menengah dan panjang, jika kemampuan beberapa model besar open source diverifikasi lebih lanjut, aplikasi akan diluncurkan dengan cepat, dan model besar akan membentuk siklus positif untuk daya komputasi 3. Lainnya: daya komputasi tepi, perusahaan data besar, dan open source Model bisnis layanan skala besar juga patut diperhatikan. Perhatian yang disarankan: 1) Penyedia layanan modul optik: Zhongji InnoLight, Xinyisheng, Komunikasi Tianfu, Teknologi Yuanjie; 2) Penyedia layanan modul pintar: MeiG Smart, Fibocom; 3) Penyedia layanan Edge IDC: Saham Longyu, Teknologi Wangsu; 4) Komunikasi AIoT produsen chip dan peralatan: ZTE, Tsinghua Unigroup, Ruijie Networks, Feiling Kesi, Fii, Aojie Technology, Chuling Information; 5) Label terminal aplikasi: Jaringan Yingying, Shenzhou Taiyue, Jiaxun Feihong, Zhongke Jincai, dll.
**Pengingat risiko: risiko etika, risiko persaingan pasar, risiko kebijakan dan pengawasan hukum. **
I. Pendahuluan
Sebuah laporan memicu minat publik yang kuat pada model bahasa besar open source.
1.1 “Baik Google maupun OpenAI tidak memiliki parit, dan ambang batas model besar dipatahkan oleh sumber terbuka”
** “Kecuali Google dan OpenAI mengubah sikap mereka dan memilih untuk bekerja sama dengan komunitas open source, mereka akan digantikan oleh yang terakhir”, **Menurut laporan Bloomberg dan SemiAnalysis, pada awal April, insinyur Google Luke Sernau menyatakan bahwa dalam kecerdasan buatan model bahasa besar ( Model Bahasa Besar, LLM, selanjutnya disebut sebagai “model besar”) trek, Google dan OpenAI, peluncur ChatGPT, tidak memiliki parit, dan komunitas open source memenangkan perlombaan.
Argumen ini membawa perhatian publik ke klimaks dari fenomena “sejumlah besar model besar muncul setelah Meta open source model besar LLaMA di awal tahun” Di antara tiga elemen kunci “model”, “daya komputasi” dan “data”, apa pola persaingan model besar di masa depan? Akankah sejumlah besar daya komputasi tidak lagi diperlukan jika modelnya kecil? Peran apa yang dimainkan data di dalamnya? …Laporan ini mencoba menganalisis titik temu dari gelombang model besar sumber terbuka ini, meninjau riwayat pengembangan tolok ukur sumber terbuka Linux, menjawab pertanyaan di atas, dan menantikan masa depan model besar.

1.2 Model skala besar open source muncul secara intensif, yang bisa disebut tren
Pada tanggal 24 Februari, Meta merilis model besar sumber terbuka LLaMA Sejak itu, sejumlah model besar telah muncul di pasar, yang secara kasar dapat dibagi menjadi tiga kategori.
1.2.1 “Seri LLaMA”: performa bagus, tetapi tingkat komersialisasinya rendah
LLaMA mencakup empat versi parameter yang berbeda (7 miliar/13 miliar/33 miliar/65 miliar), tidak tersedia secara komersial, kumpulan data perintah didasarkan pada OpenAI, dan kinerja model dapat sama atau lebih baik daripada GPT-3**. ** Di antara mereka, versi parameter 7 miliar dan 13 miliar memiliki kumpulan data pra-pelatihan yang berisi 1 triliun token; versi parameter 33 miliar dan 65 miliar memiliki kumpulan data pra-pelatihan yang berisi 1,4 triliun token. Dibandingkan dengan GPT-3, versi parameter LLaMA-7 miliar bekerja pada level yang sama dengan GPT-3 pada tugas penalaran akal sehat, tugas zero-shot, pertanyaan alami, dan pemahaman bacaan, sedangkan model versi dengan 13 miliar parameter dan lebih tinggi Kinerja di bidang di atas lebih baik daripada GPT-3.
Model LLaMA sendiri tidak menggunakan kumpulan data instruksi, tetapi mengingat bahwa ChatGPT, yang lebih baik daripada GPT-3, menggunakan kumpulan data instruksi manusia, kumpulan model besar sumber terbuka menggunakan kumpulan data instruksi OpenAI untuk mengoptimalkan kinerja model berdasarkan model LLaMA. Termasuk Alpaca, GPT4All, Vicuna, Koala, Open Assistant, dan Hugging Chat. Karena set data instruksi OpenAI tidak tersedia secara komersial, model besar open source berbasis LLaMA ini juga tidak tersedia secara komersial.

1.2.2 Dolly2.0, RedPajama, StableLM, dll.: komersialisasi tingkat tinggi
Model besar ini tidak menggunakan kumpulan data instruksi OpenAI, sehingga tersedia secara komersial, tetapi sebagian besar masih dalam pengembangan berkelanjutan.
1.2.3 Gemini Cina: ChatGLM-6B dan MOSS
ChatGLM-6B dan MOSS diluncurkan masing-masing oleh kelompok penelitian yang relevan dari Universitas Tsinghua dan Universitas Fudan, dan terkenal di komunitas Cina.
Model-model tersebut juga memiliki beberapa kesamaan, yang dijelaskan dalam laporan di bawah ini.

Kedua, poin umum 1: mulai dari open source
** Dalam gelombang ini, apakah itu model itu sendiri atau kumpulan data yang digunakan oleh model, kesamaan pertama yang mereka miliki adalah “sumber terbuka”. **
**2.1 Mengapa open source? **
Pertanyaan penting bagi pasar untuk open source model besar adalah mengapa harus open source, dan apakah ini akan merusak model bisnis industri model besar. Kami mengurutkan laporan mandiri dari beberapa model besar tentang alasan open source, dan meringkasnya sebagai berikut.
2.1.1 Perspektif Model: Mencegah monopoli perusahaan besar dan melanggar larangan larangan komersial
Untuk mendemokratisasi penelitian kecerdasan buatan, menjembatani kesenjangan kualitas antara model terbuka dan tertutup, dan menghapus batasan larangan komersial, pengembangan model besar open source yang gencar diharapkan dapat mempromosikan tujuan di atas.
2.1.2 Perspektif Data: Melindungi rahasia perusahaan dan memungkinkan pelatihan data yang disesuaikan
**Menjamin privasi data dan mengizinkan perusahaan menyesuaikan pengembangan. **Bagi banyak industri, data adalah sumber kehidupan perusahaan. Sumber terbuka model besar memungkinkan perusahaan untuk melatih set data mereka sendiri pada model besar, sekaligus mencapai kontrol data dan melindungi privasi data perusahaan. Pada saat yang sama, model besar open source memungkinkan pengembang perusahaan untuk melakukan pengembangan yang disesuaikan berdasarkan model, menargetkan data pelatihan, dan memfilter topik tertentu, mengurangi ukuran model dan biaya pelatihan data.
2.1.3 Perspektif daya komputasi: kurangi biaya daya komputasi dan manfaatkan model besar “inklusif”
** Model besar sumber terbuka menghemat konsumsi daya komputasi dalam fase pelatihan, mengurangi biaya daya komputasi untuk perusahaan, dan mempromosikan penggunaan model besar yang “inklusif”. **Total kebutuhan daya komputasi = jumlah skenario* kebutuhan daya komputasi untuk satu skenario. Dalam pelatihan dan penggunaan model besar, konsumsi daya komputasi dibagi menjadi dua skenario, yaitu konsumsi biaya pelatihan dan konsumsi biaya inferensi.
- Dalam hal biaya pelatihan, biaya pelatihan model besar tinggi, dan sumber daya komputasi perusahaan biasa tidak tertahankan, sedangkan model besar sumber terbuka terutama menghemat daya komputasi pada tahap pra-pelatihan perusahaan. Namun, karena skenario pelatihan yang lebih kaya dari berbagai kategori vertikal, permintaan pelatihan secara keseluruhan meningkat.
- Dalam hal biaya inferensi, biaya inferensi model besar juga tinggi ketika parameternya besar, dan sulit bagi perusahaan biasa untuk mempertahankan pengeluaran hariannya, oleh karena itu, mengurangi ukuran parameter model dapat semakin mengurangi alasan perusahaan menggunakan model biaya.
**2.2 Sumber terbuka, jenis tanah apa yang Anda butuhkan? **
** Berkembangnya megamodel open source bukannya tanpa preseden, dan Linux, proyek perangkat lunak open source terbesar di dunia, memiliki cerita serupa. **Meneliti sejarah pengembangan Linux memiliki signifikansi referensi untuk menantikan masa depan model besar open source.
2.2.1 Mari kita mulai dari benchmark open source Linux
**Linux adalah sistem operasi sumber terbuka dan gratis yang dirilis di bawah Lisensi Publik Umum GNU (GPL). **Siapa pun dapat menjalankan, mempelajari, berbagi, dan memodifikasi perangkat lunak ini. Kode yang dimodifikasi juga dapat didistribusikan ulang dan bahkan dijual, tetapi hanya di bawah lisensi yang sama. Sistem operasi tradisional, seperti Unix dan Windows, adalah sistem berpemilik yang dikunci oleh vendor, dikirimkan apa adanya, dan tidak dapat dimodifikasi.
Banyak industri dan bisnis terbesar di dunia bergantung pada Linux. Saat ini, Linux ada di mana-mana, mulai dari situs berbagi pengetahuan seperti Wikipedia, hingga Bursa Efek New York, hingga perangkat seluler yang menjalankan Android, sebuah distribusi khusus dari kernel Linux yang menyertakan perangkat lunak gratis. Saat ini, Linux bukan hanya sistem operasi yang paling umum digunakan di server Internet publik, tetapi juga satu-satunya sistem operasi yang digunakan di 500 superkomputer tercepat teratas.
**Di pasar server, pangsa pasar Linux telah jauh melampaui “kakek” dari sistem operasi, Unix, dan “momen Linux” pun terjadi. **Mengambil pasar Cina sebagai contoh, menurut data CCID Consulting dan statistik kapasitas terpasang, dalam hal arsitektur server, Linux adalah arus utama di pasar, menempati posisi terdepan mutlak, dengan pangsa pasar 79,1 %. Pangsa pasar Windows turun menjadi 20,1%, dan pangsa pasar Unix hanya 0,8%.

2.2.2 Linux bukanlah karya sendiri, memanfaatkan sejarah open source di belakang komunitas
Unix telah menjadi open source, menyediakan api untuk Linux
**Unix, pencetus sistem operasi modern. **Sistem operasi mengacu pada perangkat lunak yang secara langsung mengelola perangkat keras dan sumber daya sistem (seperti CPU, memori, dan ruang penyimpanan). Ia terletak di antara aplikasi dan perangkat keras dan bertanggung jawab untuk membuat koneksi antara semua perangkat lunak dan sumber daya fisik terkait. Unix dianggap oleh banyak orang sebagai nenek moyang sistem operasi modern.
** Unix pernah menjadi sumber terbuka. **Komputer tujuan umum pertama di dunia lahir pada tahun 1946, dan Unix dikembangkan pada tahun 1969. Selama sepuluh tahun, AT&T, pemilik UNIX, telah melisensikan kode sumber Unix kepada institusi akademik untuk penelitian atau pengajaran dengan biaya rendah atau bahkan lisensi gratis. Banyak institusi telah memperluas dan menyempurnakan kode sumber ini, membentuk apa yang disebut “Unix varian”. Belakangan, AT&T menyadari nilai komersial Unix, tidak lagi melisensikan kode sumber Unix ke institusi akademik, dan menyatakan hak cipta atas Unix sebelumnya dan variannya
Unix terlalu mahal setelah kembali ke sumber tertutup, yang menyebabkan pengembangan Linux
Linux dirancang dan diluncurkan oleh Linux Torvalds pada tahun 1991. Saat itu, dia masih kuliah dan berpikir bahwa sistem operasi komersial populer Unix pada saat itu terlalu mahal, sehingga dia mengembangkan Linux berdasarkan sistem operasi Minix mirip Unix dan membukanya untuk orang-orang seperti dirinya yang tidak mampu membelinya dari tim.
Minix hanya untuk pengajaran, menginspirasi pengembangan Linux
Setelah AT&T memprivatisasi kode sumbernya, Tanenbaum, seorang profesor di Vrije University Amsterdam di Belanda, memutuskan untuk mengembangkan pekerjaan rumah yang kompatibel dengan UNIX tanpa menggunakan kode sumber AT&T apa pun untuk mengajari siswa rincian praktis pengoperasian sistem operasi di kelas. menghindari sengketa hak cipta. Ia menyebutnya MINIX dengan arti mini-UNIX (mini-UNIX). MINIX versi pertama dirilis pada tahun 1987, dan Anda hanya perlu membeli disk untuk menggunakannya. Sebelum sistem Linux tidak memiliki sistem file aslinya sendiri, sistem file Minix digunakan.
Komunitas sumber terbuka, lisensi, dan dukungan standar
** Sumber terbuka dari awal. **Pada bulan Agustus 1991, pendiri Linux Linus Torvalds memposting Linux ke newsgroup Minix Usenet. Kemudian dia merilis Linux ke situs FTP karena dia ingin lebih banyak orang mengembangkan kernel bersama.

** Lisensi membantu ekologi untuk berkembang dan berkembang. **Linux didasarkan pada model lisensi GNU GPL (GNU’s Not Unix General Public License, Genu Project General Public License). Lisensi GPL memberikan empat kebebasan yang diberikan oleh “perangkat lunak bebas” kepada pengguna, atau “Copyleft (hak cipta publik)”:
- Freedom Zero: Kebebasan untuk “menggunakan” perangkat lunak untuk tujuan apa pun.
- Salah satu kebebasan: kebebasan untuk “mempelajari cara kerja perangkat lunak” dan “memodifikasi” perangkat lunak untuk memenuhi kebutuhan pengguna sendiri. Akses ke kode sumber merupakan prasyarat untuk kebebasan ini.
- Kebebasan 2: Ada kebebasan untuk “mendistribusikan salinan perangkat lunak”, sehingga setiap orang dapat membangun keramahtamahan yang baik dengan mendistribusikan perangkat lunak bebas.
- Kebebasan 3: Kebebasan untuk “menerbitkan versi yang telah direvisi” sehingga seluruh masyarakat dapat memperoleh manfaat. Akses ke kode sumber merupakan prasyarat untuk kebebasan ini.
Lisensi GPL mengharuskan karya turunan dari program GPL juga mengikuti model lisensi GPL. Sebaliknya, lisensi seperti gaya BSD tidak melarang karya turunan dibuat menjadi perangkat lunak berpemilik. GPL adalah lisensi paling populer untuk perangkat lunak bebas dan sumber terbuka. Mematuhi lisensi GPL memungkinkan ekosistem Linux untuk terus berkembang, agar tidak memasuki “kebuntuan” di mana ia tidak dapat terus berkembang.
**Standar secara internal membuat ekologi “bentuknya tersebar tetapi semangat tidak tersebar”, dan secara internal merangkul “paus raksasa”. **
- **Standar terpadu internal. **Linux telah merumuskan LSB standar (Linux Standard Base, Linux Standard Base) untuk menstandarkan pengembangan, sehingga menghindari hasil pengembangan dari berbagai tim yang terlalu berbeda. Oleh karena itu, berbagai alat pengembangan turunan Linux hanya berbeda dalam hal-hal seperti alat dan mode manajemen suite. Hal ini kami yakini membuat pengembangan komunitas open source Linux “tercerai-berai tapi tidak terpencar”, sehingga pengembangan ekosistem Linux tidak akan berantakan.
- **Secara eksternal kompatibel dengan Unix. **Agar Linux kompatibel dengan perangkat lunak Unix, Linus Torvalds memodifikasi Linux dengan mengacu pada standar POSIX (Portable Operating Interface), yang sangat meningkatkan penggunaan Linux. Standar ini dikembangkan oleh IEEE (Institue of Electrical and Electronics Engineers, Institute of Electrical and Electronics Engineers) pada tahun 1990. Ini adalah tahap awal Linux. Portabilitas menyediakan lingkungan yang menguntungkan untuk promosi Linux.
**2.3 Sumber terbuka, bagaimana cara menghasilkan uang? **
Pertanyaan inti di pasar tentang “sumber terbuka” adalah model bisnisnya. “Open source” itu sendiri gratis, tetapi “open source” adalah dasarnya, dan “komunitas open source” telah melahirkan berbagai model bisnis, yang dapat dipelajari dari ekosistem Linux.
2.3.1 Red Hat: Layanan Mengutamakan
Red Hat adalah pemimpin dalam ekosistem Linux. Lebih dari 90% perusahaan Fortune 500 mempercayai Red Hat. Red Hat memiliki nilai komersial yang sangat besar sebagai sebuah perusahaan. Red Hat didirikan pada tahun 1993. Pada tahun 1999, Red Hat terdaftar di Nasdaq. Menurut prospektus Red Hat, mengutip data IDC, pada tahun 1998, 56% dari semua instalasi baru resmi sistem operasi Linux berasal dari Red Hat. Pada tahun 2012, Red Hat menjadi perusahaan teknologi sumber terbuka pertama dengan pendapatan lebih dari $1 miliar; pada tahun 2019, IBM mengakuisisi Red Hat dengan harga sekitar $34 miliar.
Mengenai model bisnis Linux dan Red Hat, ini seperti analogi Curiosity Daily. Dalam arti, kernel Linux open source seperti resep gratis dan terbuka, dan Red Hat seperti restoran. Orang-orang masih rela pergi ke restoran untuk mencicipi hidangan olahan dan menikmati layanan penuh perhatian. Red Hat menyediakan sistem operasi Linux dan layanan berlangganan untuk perusahaan. Layanan utama meliputi: 1. dukungan teknis 24*7; 2. Bekerja sama dengan komunitas hulu dan produsen perangkat keras untuk mendukung berbagai arsitektur perangkat keras, seperti x86, ARM, IBM Power dll.; 3. Peringatan kerentanan berkelanjutan, panduan arah, dan layanan perbaikan otomatis; 4. Penerapan di beberapa cloud; 5. Fungsi perlindungan keamanan seperti penambalan kernel waktu nyata dan sertifikasi standar keamanan; 6. Mendeteksi anomali kinerja dan membangun pandangan menyeluruh tentang kinerja sistem , dan menerapkan profil penyetelan prasetel, dll.

2.3.2 Sistem Android (Android): didukung oleh Google, dimonetisasi oleh iklan
Menurut data Statcounter, per April 2023, Android (Android) adalah sistem operasi seluler nomor satu di dunia, dengan pangsa pasar 69%, jauh melampaui posisi kedua (iOS, 31%). Android dikembangkan berdasarkan kernel Linux dan diakuisisi oleh Google pada tahun 2005. Selanjutnya, Google merilis kode sumber Android di bawah otorisasi lisensi sumber terbuka gratis Apache, yang memungkinkan produsen meluncurkan ponsel pintar yang dilengkapi Android dengan cepat, yang mempercepat popularitas Android.
Untuk model bisnisnya, banyak layanan pra-instal di ponsel Android yang disediakan oleh produk milik Google, seperti peta, toko aplikasi Google Play, pencarian, dan Google Mail (Gmail).Oleh karena itu, meskipun Android gratis dan open source, Google masih dapat menggunakan Pasar seluler “mengepung kota dan wilayah” dan memonetisasi lalu lintas pengguna.
Google juga membebankan biaya lisensi langsung dari produsen ponsel Android. Mulai 29 Oktober 2018, produsen UE yang menggunakan ponsel dan tablet berbasis Android harus membayar Google biaya lisensi untuk setiap perangkat. Harga peralatan bisa mencapai $40.
2.4 Lisensi utama model besar open source mendukung penggunaan komersial
Komunitas open source sudah memiliki lisensi terkenal seperti GPL, BSD, dan Apache. Dalam hal model besar, kami telah memperhatikan bahwa LLaMA, yang dirilis pada Februari 2023 dan memimpin gelombang model besar sumber terbuka, dilarang untuk penggunaan komersial dan hanya dapat digunakan untuk penelitian. MetaAI akan diberikan kepada pegawai negeri, anggota kelompok sosial, tenaga akademik dan percobaan penelitian industri sesuai dengan keadaan tertentu.ruangan, akses ke model. Diantaranya, kode penalaran LLaMA didasarkan pada lisensi GPL3.0, yang berarti: 1) Setelah orang lain mengubah kode penalaran LLaMA, sumbernya tidak dapat ditutup; 2) Kode baru juga harus mengadopsi lisensi GPL. Namun, kami melihat bahwa beberapa developer telah mengembangkan model varian berdasarkan LLaMA dengan berbagai jenis lisensi. Misalnya, penerapan Lit-LLaMA berdasarkan LLaMA nanoGPT menambahkan beberapa bobot model, dan lisensi yang digunakan oleh bagian model ini adalah Apache2.0.
**Protokol yang diadopsi oleh model besar sumber terbuka sebagian besar adalah lisensi Apache 2.0 dan MIT. **Alpaca, Vicuna, Dolly, OpenAssistant, dan MOSS semuanya di bawah lisensi Apache 2.0, Koala dan GPT4 semuanya di bawah lisensi MIT. Kedua lisensi mengizinkan penggunaan komersial. Sayangnya, Alpaca, Vicuna, Koala, dan GPT4all tidak tersedia secara komersial karena pembatasan OpenAI atau LLaMA. Pada saat yang sama, perlu dicatat bahwa lisensi Apache2.0 dan MIT memungkinkan kode sumber diubah dan kemudian ditutup.Perusahaan dapat mengembangkan modelnya sendiri berdasarkan model sumber terbuka, atau akan lebih menarik untuk perusahaan.

3. Titik umum 2: model besar open source dengan sedikit parameter dan miniaturisasi
“Ukuran parameter model” berhubungan positif dengan “permintaan model untuk daya komputasi”.
**3.1 Seberapa besar model super besar dan model besar? **
**Pra-pelatihan memberi model kemampuan dasar. **Dalam pemrosesan bahasa alami (NLP), pra-pelatihan merujuk pada pelatihan model bahasa pada korpus teks besar sebelum menyempurnakan tugas tertentu, memberikan kemampuan pemahaman bahasa dasar model. Selama pra-pelatihan, model dilatih untuk memprediksi kata berikutnya dalam sebuah kalimat berdasarkan konteks sebelumnya. Ini dapat dilakukan dengan menutupi beberapa kata dalam input dan meminta model untuk memprediksinya, atau dengan metode autoregresif (seperti GPT) di mana kata berikutnya diprediksi berdasarkan kata sebelumnya dalam kalimat.
Model pra-pelatihan biasanya mencakup sejumlah besar parameter dan data pra-pelatihan yang sesuai (biasanya diukur dengan jumlah pengidentifikasi, yaitu Token). Pada tahun 2017, kemunculan model Google Brain Team Transformer (transformator) benar-benar mengubah wajah NLP, memungkinkan model untuk lebih memahami dan memproses bahasa, serta meningkatkan efek dan akurasi tugas NLP.

**Seberapa besar model ekstra besar dan model besar? **Ukuran model bahasa diukur menurut kuantitas parameternya, yang terutama menggambarkan nilai yang dapat disesuaikan dari kekuatan koneksi antar neuron. Saat ini, parameter model bahasa besar umumnya berkisar dari puluhan hingga puluhan miliar, yang memiliki lebih dari 100 miliar parameter disebut “model super besar”, seperti GPT-3 (175 miliar parameter).
3.2 Model super besar GPT memiliki kemampuan terkuat, tetapi sulit untuk direproduksi
** Kriteria evaluasi kinerja untuk model besar tidak disatukan. **Alasan penting adalah bahwa ada banyak jenis tugas untuk model besar untuk menghasilkan konten, dan skenario dan tugas aplikasi yang berbeda mungkin memerlukan indikator dan metode yang berbeda untuk mengevaluasi kinerja model. Beberapa dari tugas ini mungkin memiliki standar penilaian yang sangat kredibel, seperti BLEU dalam terjemahan mesin, tetapi sebagian besar tugas tidak memiliki standar serupa.
** Konsensus fuzzy adalah model yang sangat besar bekerja dengan baik. **Tren perkembangan model bahasa besar saat ini semakin besar dan besar (lihat gambar di bawah untuk detailnya), karena model besar memiliki keserbagunaan dan stabilitas yang lebih baik setelah pra-pelatihan. Misalnya, model PaLM super besar tim Google (540 miliar parameter) memiliki hasil yang baik dalam pengujian sampel nol dan sampel kecil (lihat gambar di bawah untuk detailnya), dan kinerjanya masih dapat meningkat karena jumlah pengidentifikasi pelatihan meningkat. Ini tidak sulit untuk dipahami, Sederhananya, semakin banyak model yang Anda lihat, semakin banyak yang Anda ketahui secara alami.

** “Peer Review”, model besar berbasis GPT “Peerless Beauty”. **Saat ini, model super besar dari sistem OpenAI GPT memiliki kemampuan yang kuat dan beragam aplikasi. Ia memiliki akurasi tinggi dan ekspresif yang kuat saat menangani tugas bahasa alami. Ini digunakan di banyak bidang seperti pembuatan teks, pertanyaan sistem penjawab, dan terjemahan mesin Semuanya telah mencapai hasil yang sangat baik dan telah menjadi salah satu tolok ukur saat ini di bidang pemrosesan bahasa alami, dan digunakan sebagai tolok ukur perbandingan oleh berbagai model besar. Ambang batas untuk mereproduksi ChatGPT belum diturunkan. Sebagian besar model open source besar hanya bekerja lebih baik di beberapa aspek, dan kualitas keseluruhannya masih tidak sebanding dengan ChatGPT. Masih harus dilihat.

Baru-baru ini, kami juga memperhatikan sistem evaluasi berikut. Metode evaluasi terutama mencakup evaluasi otomatis mesin (seperti menggunakan GPT4), evaluasi buta manusia, dll. Kami akan fokus pada beberapa di antaranya dan hasil evaluasinya, tetapi apa pun sistem evaluasinya , sistem GPT Model-model besar semuanya kedudukan tertinggi.
- luar negeri
- Chatbot Arena dari University of Berkeley mengacu pada mekanisme kualifikasi permainan untuk memungkinkan manusia mengevaluasi model berpasangan secara membabi buta;
- Toolkit open source Zeno Build, melalui Hugging Face atau API online, menggunakan Critique untuk mengevaluasi beberapa model besar.
- Luar negeri
- SuperCLUE adalah tolok ukur evaluasi komprehensif untuk model besar tujuan umum China, mencoba mengevaluasi model besar secara otomatis;
- C- 14.000 pertanyaan pilihan ganda yang mencakup 52 mata pelajaran digunakan untuk mengevaluasi kemampuan model Cina Standar serupa masih membutuhkan waktu dan pengujian pasar.
3.2.1 Vicuna: Evaluasi dengan GPT-4
**Saat ini, performa sebagian besar model besar open source belum dievaluasi secara sistematis, dan sebagian besar masih dalam tahap awal eksperimen. **Di antara model open source besar untuk mengevaluasi kinerja, evaluasi menggunakan GPT-4 dalam laporan Vicuna relatif sistematis dan hasilnya paling mengesankan.

3.2.2 Evaluasi Zeno Build: Lebih baru dan lebih komprehensif
Zeno Build mengevaluasi tujuh model GPT-2, LLaMA, Alpaca, Vicuna, MPT-Chat, Cohere Command, dan ChatGPT (gpt-3.5-turbo), dan hasilnya mirip dengan GPT-4. ChatGPT memiliki keunggulan yang jelas, dan Vicuna bekerja paling baik di antara model sumber terbuka.

3.2.3 C-: Kit Evaluasi Model Dasar Bahasa Mandarin Komprehensif
C- Hasil evaluasi menunjukkan bahwa meskipun dalam hal kemampuan Cina, GPT-4 adalah yang terbaik, tetapi GPT-4 hanya dapat mencapai tingkat yang benar sebesar 67%.Saat ini, kemampuan pemrosesan Cina model besar masih banyak. ruang untuk perbaikan.

3.2.4 Biaya pelatihan model super besar GPT tinggi, dan sulit untuk direproduksi dalam jangka pendek
**ChatGPT membutuhkan daya komputasi dan biaya pelatihan yang besar. **Jangan mempertimbangkan daya komputasi yang diperlukan untuk proses penalaran yang sangat terkait dengan aktivitas sehari-hari, hanya pertimbangkan proses pelatihan, menurut perhitungan makalah “Language Models are Few-Shot Learners”, GPT-3 generasi sebelumnya dari ChatGPT (175 miliar versi parameter) Daya komputasi yang diperlukan setinggi 3640PF-hari (yaitu, jika satu kuadriliun operasi floating-point dilakukan per detik, perlu dihitung selama 3640 hari), dan diketahui bahwa komputasi daya satu kartu grafis Nvidia A100 adalah sekitar 0,6PFLOPS, lalu latih GPT-3 sekali (versi parameter 175 miliar), diperlukan sekitar 6.000 kartu grafis Nvidia A100. Jika dianggap kehilangan interkoneksi, diperlukan sekitar puluhan ribu A100 . Harga satu chip A100 adalah sekitar 100.000 yuan, dan pelatihan skala besar perlu berinvestasi sekitar 1 miliar yuan. . OpenAI menghabiskan lebih dari $4 juta untuk pelatihan GPT-3 (175 miliar parameter), dan untuk mempertahankan operasi ChatGPT dan GPT4 (jumlah parameter tidak diumumkan, diharapkan lebih tinggi), yang secara teoritis lebih tinggi masing-masing bulan.
3.3 Model besar sumber terbuka hemat biaya, dan hambatan untuk model besar di bawah model super besar menghilang
**Tren miniaturisasi model open source besar sudah jelas, dan parameternya sekitar puluhan miliar.Pengurangan biaya adalah arti dari pertanyaannya. **Model besar open source biasanya memiliki lebih sedikit parameter, dan membutuhkan sumber daya dan biaya yang relatif rendah dalam hal desain, pelatihan, dan penerapan. Parameter gelombang model besar open source ini umumnya kecil, pada level satu miliar hingga sepuluh miliar.

“Perahunya kecil dan mudah diputar”, penyetelan halus berdasarkan model pra-pelatihan sumber terbuka yang ada juga merupakan salah satu keunggulan model besar sumber terbuka. Menyempurnakan dan mengoptimalkan berdasarkan model yang telah dilatih sebelumnya untuk beradaptasi dengan berbagai tugas dan skenario aplikasi, metode ini tidak hanya dapat sangat mengurangi waktu pelatihan dan biaya model, tetapi juga meningkatkan kinerja dan efisiensi model.
**Dengan lebih banyak data pelatihan pengidentifikasi dan teknologi baru, hambatan untuk model besar di bawah model super besar cenderung menghilang. **LLaMA adalah “sumber terbuka”, sehingga setiap orang memiliki model besar yang dapat digunakan, dan dengan pengembangan teknologi seperti DeepSpeed dan RLHF, puluhan miliar model dapat diterapkan pada GPU tingkat konsumen.
- Lebih banyak data pelatihan pengidentifikasi mungkin lebih penting daripada lebih banyak parameter: Studi DeepMind “Pelatihan Model Bahasa Besar Komputasi-Optimal” yang diterbitkan pada 29 Maret 2022 mengungkapkan kepada kami bahwa ukuran model Hubungan antara dan ukuran data pelatihan:
- Model besar sering kali tidak terlatih, menghasilkan pemborosan daya komputasi yang besar.
- Pelatihan lebih lengkap dengan model yang lebih kecil dapat mencapai kinerja yang lebih baik daripada model yang lebih besar. Misalnya, model Chinchilla DeepMind hanya memiliki 70 miliar parameter. Setelah pelatihan dengan kumpulan data pelatihan 1,4 triliun pengenal, ini lebih baik daripada Gopher DeepMind (280 miliar parameter, 300 miliar kumpulan data pelatihan pengenal) dan GPT OpenAI dalam pengujian. - 3 (175 miliar parameter, 300 miliar set data pelatihan pengidentifikasi).
- Untuk mencapai performa model yang lebih baik, setiap kali jumlah parameter model berlipat ganda, ukuran kumpulan data pelatihan pengidentifikasi juga harus berlipat ganda.
- Model yang lebih kecil juga berarti biaya penyesuaian dan inferensi downstream yang lebih kecil.
- Teknologi DeepSpeed : dapat secara signifikan mengurangi waktu dan biaya pelatihan model besar;
- RLHF (Reinforcement Learning Based on Human Feedback): Dapat meningkatkan kinerja dan akurasi model dengan sedikit pelatihan pengidentifikasi.

Keempat, poin umum ketiga: set data model besar open source mementingkan instruksi manusia, dan berdiri sendiri
“Ukuran kumpulan data” juga berhubungan positif dengan “daya komputasi yang dibutuhkan oleh model”.
4.1 Pelajari metodologi ChatGPT dan perkenalkan set data instruksi manusia
**Tweaking adalah jalan pintas untuk meningkatkan kinerja tertentu. **Fine-tuning mengacu pada pelatihan skala kecil lebih lanjut pada model pra-pelatihan menggunakan kumpulan data khusus tugas dengan data berlabel. Penyempurnaan dapat membuat model lebih mudah beradaptasi dengan data dan skenario khusus tugas dengan sedikit biaya daya komputasi, sehingga meningkatkan kinerja dan akurasi model. Saat ini, fine-tuning sebagian besar adalah fine-tuning instruksi, dan set data instruksi secara bertahap menjadi konfigurasi standar model besar open source.
RLHF (Reinforcement Learning from Human Feedback, pembelajaran penguatan berdasarkan umpan balik manusia) adalah metode penyesuaian yang muncul yang menggunakan teknik pembelajaran penguatan untuk melatih model bahasa dan menyesuaikan keluaran model berdasarkan umpan balik manusia. RLHF (pembelajaran penguatan berdasarkan umpan balik manusia) adalah fitur yang tidak dimiliki oleh GPT3 versi awal ChatGPT, yang membuat InstructGPT dengan hanya 1,3 miliar parameter menunjukkan keaslian, ketidakberbahayaan, dan instruksi manusia yang lebih baik daripada GPT-3 dengan 175 miliar parameter Tingkat kepatuhan adalah lebih diakui oleh annotator tanpa mengurangi efek GPT-3 pada dimensi evaluasi akademik.
RLHF (Reinforcement Learning Based on Human Feedback) dibagi menjadi tiga langkah: 1) Supervised fine-tuning (SFT): Biarkan annotator menjawab pertanyaan manusia, dan gunakan data anotasi ini untuk melatih GPT; 2) Pelatihan model reward (RM): Biarkan annotator Menyortir jawaban dari mesin, dibandingkan dengan pelabelan generatif di mana annotator langsung menulis jawaban pada langkah pertama, biaya penyortiran sebagai label diskriminatif lebih rendah. Gunakan label ini untuk melatih model dan membiarkannya mensimulasikan penyortiran manusia; 3) Tidak ada manusia Beranotasi, model yang disesuaikan dengan algoritma optimisasi kebijakan proksimal (PPO).
Ukuran kumpulan data yang sesuai dengan ketiga langkah ini masing-masing adalah 13.000, 33.000, dan 31.000.

Untuk perusahaan dengan sejumlah besar data dan jumlah daya komputasi tertentu, menggunakan data mereka sendiri untuk penyempurnaan dapat menunjukkan kemampuan spesialisasi model, dan menggunakan daya komputasi yang lebih sedikit untuk mencapai efek yang mendekati model besar. Misalnya, model bahasa Vicuna yang dikembangkan bersama oleh beberapa sekolah, berdasarkan model versi parameter LLaMA-13 miliar Meta, menyempurnakan instruksi dialog ChatGPT yang dibagikan oleh 70.000 pengguna, dan mencapai 92% efek GPT4 pada beberapa tugas . Ini tidak dapat melebihi model super besar dalam hal keserbagunaan dan stabilitas, tetapi dapat memperkuat kemampuannya dalam beberapa aspek melalui penyempurnaan.Kinerja biaya lebih tinggi dan lebih cocok untuk perusahaan kecil dan menengah.
4.2 Dataset menuju penggunaan komersial
Kumpulan data adalah dasar dan dukungan penting untuk pengembangan model bahasa, dan biasanya dikumpulkan, diatur, atau dibeli langsung oleh perusahaan atau organisasi. Sebaliknya, kumpulan data sumber terbuka sebagian besar dikelola bersama oleh komunitas atau akademisi, dan volume serta jenis datanya lebih banyak, tetapi mungkin ada masalah kualitas data tertentu dan perbedaan penerapan.
4.2.1 Sejumlah kecil kumpulan data pra-pelatihan tersedia secara komersial
**Sumber terbuka kumpulan data pra-pelatihan sangat penting untuk penggunaan model secara komersial. ** Di era pasca-LLaMA, model sumber terbuka besar bermunculan seperti jamur setelah hujan, tetapi segera semua orang menemukan bahwa karena keterbatasan LLaMA dan OpenAI, model yang didasarkan padanya tidak tersedia secara komersial (Alpaca, Koala, GPT4All, Vicuna), untuk mengatasi situasi ini, Dolly2.0 memimpin, "Untuk mengatasi masalah ini, kami mulai menemukan cara untuk membuat kumpulan data baru yang tidak terkontaminasi untuk penggunaan komersial. ’ diikuti oleh Piyama Merah dan MOSS.
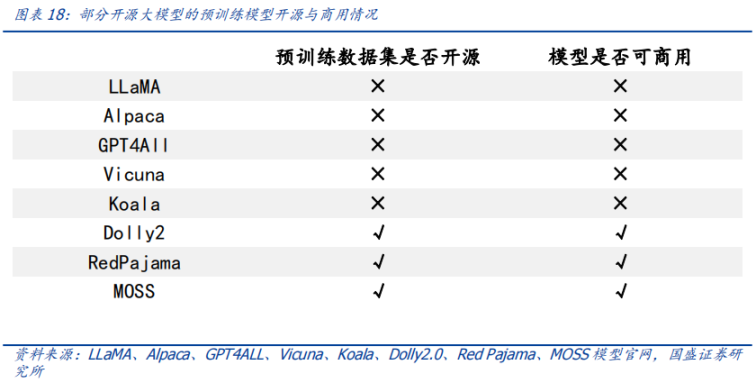
4.2.2 Bagian dari kumpulan data instruksi tersedia secara komersial
**Buat ekologi sumber terbuka, masing-masing mengambil apa yang dibutuhkannya. **Dalam proyek open source awal, karena data instruksi dan sebagian besar dari generasi ChatGPT atau konten dialog, itu tidak tersedia secara komersial karena pembatasan OpenAI. Selain penyempurnaan untuk tujuan penelitian, semakin banyak model memilih untuk membuat kumpulan data instruksi mereka sendiri untuk menghindari batasan ini.
**Set data instruksi beragam, dan set data instruksi dari beberapa model tersedia secara komersial. **Menurut klasifikasi model besar di atas dalam batch ini, kecuali untuk LLaMA, model dikembangkan berdasarkan LLaMA, dan StableLM menggunakan kumpulan data instruksi OpenAI, kumpulan data instruksi dari model besar lainnya tidak didasarkan pada OpenAI, jadi ini Komersial ketersediaan set data instruksi untuk model besar akan mempercepat evolusi dan pengembangan model besar tersebut menggunakan paradigma pelatihan RLHF (Reinforcement Learning with Human Feedback).

5. Pandangan
Kami telah memperhatikan bahwa megamodel open source sedang menuju persimpangan yang sama.
5.1 Multimodality: Mendorong Pengembangan General Artificial Intelligence (AGI)
**Model besar sumber terbuka multi-modal telah mulai muncul, mendorong model besar ke klimaks baru dan membantu manusia bergerak menuju kecerdasan buatan umum. Multi-modalitas mengacu pada integrasi berbagai mode seperti gambar, suara, dan teks. Model multimodal didasarkan pada teknik pembelajaran mesin yang dapat memproses dan menganalisis berbagai jenis input, membuat model besar lebih fleksibel. Berdasarkan pengetahuan multi-domain, bangun model terpadu, lintas skenario, dan multi-tugas, dan promosikan manusia ke era Kecerdasan Umum Buatan (AGI). **
5.1.1 ImageBind memulai debutnya, menggunakan gambar untuk membuka 6 mode
** Model besar sumber terbuka ImageBind dapat melampaui satu pengalaman sensorik, memungkinkan mesin memiliki kemampuan untuk “berasosiasi”. ** Pada tanggal 9 Mei, Meta Corporation mengumumkan ImageBind model besar multimodal open source. Model mengambil gambar sebagai intinya dan dapat terhubung ke 6 mode, termasuk gambar (gambar/video), suhu (gambar inframerah), teks, audio, informasi kedalaman (3D), sensor penangkapan gerak (IMU). Kode sumber yang relevan telah dihosting di GitHub. Tim mengatakan bahwa di masa depan, modalitas seperti sentuhan, penciuman, dan sinyal resonansi magnetik otak juga akan ditambahkan.
Secara teknis, ImageBind memanfaatkan data jaringan (misalnya gambar, teks) dan menggabungkannya dengan data berpasangan yang terjadi secara alami (misalnya audio, informasi mendalam, dll.) untuk mempelajari satu ruang penyematan bersama sehingga ImageBind secara implisit menggabungkan teks Penyematan diselaraskan dengan modalitas lain, memungkinkan pengenalan zero-shot pada modalitas ini tanpa pemasangan semantik atau tekstual yang eksplisit.
Kasus penggunaan umum untuk ImageBind saat ini meliputi: memasukkan suara gonggongan anjing ke model, dan model mengeluarkan gambar anjing, dan sebaliknya; memasukkan gambar burung dan suara ombak laut ke model, dan model mengeluarkan gambar burung di pantai, dan sebaliknya.

5.1.2 Eksplorasi multimodal model besar open source berfokus pada gambar, tetapi kemajuannya pesat
Saat ini, eksplorasi multimodalitas dalam model besar open source masih dalam tahap awal, kecuali ImageBind yang telah membuka enam modalitas, kebanyakan masih mengeksplorasi perpaduan teks dan gambar, namun kecepatannya cukup cepat. telah memilah beberapa di antaranya.
VisualGLM-6B: Dapat diterapkan secara lokal pada kartu grafis konsumen
- Tim: VisualGLM-6B adalah versi peningkatan multimodal dari model bahasa besar sumber terbuka ChatGLM-6B, yang mendukung gambar, bahasa Mandarin dan Inggris, dan dirilis oleh Kelompok Teknik Pengetahuan dan Penambangan Data Universitas Tsinghua. *Teknologi: VisualGLM-6B adalah kombinasi model bahasa ChatGLM-6B dan model gambar BLP2-Qformer. Parameter setelah kombinasi keduanya adalah 7,8 miliar (6,2 miliar + 1,6 miliar). Dataset pra-pelatihan yang digunakan oleh model adalah 30 juta pasangan “teks gambar China” berkualitas tinggi dan 300 juta pasangan “teks gambar bahasa Inggris” dalam set data CogView. Pada tahap fine-tuning, model dilatih pada kumpulan data jawaban pertanyaan visual yang panjang untuk menghasilkan jawaban yang sesuai dengan preferensi manusia.
- Performa: Menurut DataLearner, VisualGLM-6B mengintegrasikan teknologi kuantisasi model, dan pengguna dapat menerapkan model secara lokal pada kartu grafis kelas konsumen. Level kuantisasi INT4 hanya membutuhkan memori video 8,7G. Ini berarti bahwa bahkan pengguna dengan laptop gaming dapat dengan cepat dan secara pribadi menerapkan model tersebut, yang pertama untuk model mirip ChatGPT dengan ukuran ini.
UniDiffuser: UniDiffuser, kerangka kerja pemodelan probabilistik yang dirancang untuk multimodality
- Tim: Tim TSAIL yang dipimpin oleh Profesor Zhu Jun dari Departemen Ilmu Komputer, Universitas Tsinghua menerbitkan makalah “Satu Transformator Cocok untuk Semua Distribusi dalam Difusi Multi-Modal Berskala” pada 12 Maret, dan melakukan beberapa eksplorasi multi-modal.
- Teknologi: UniDiffuser mengadopsi arsitektur jaringan berbasis Transformer U-ViT yang diusulkan oleh tim, dan melatih model dengan satu miliar parameter pada versi 5 miliar parameter dari set data grafis skala besar open source LAION, memungkinkannya menjadi tinggi -kualitas menyelesaikan berbagai tugas generasi.
- Fungsi: Sederhananya, selain grafik yang dihasilkan vin satu arah, model ini juga dapat mewujudkan banyak fungsi seperti teks yang dihasilkan grafik, pembuatan gabungan grafik-teks, pembuatan teks-grafik tanpa syarat, penulisan ulang grafik-teks, dll ., dan mewujudkan transformasi timbal balik antara mode sewenang-wenang .
LLaVA: Performa beberapa instruksi sebanding dengan GPT-4
- Tim: LLaVA, diproduksi bersama oleh University of Wisconsin-Madison, Microsoft Research, dan Columbia University, memiliki kode, model, dan kumpulan data sumber terbuka di GitHub.
- Teknik: LLaVA adalah model besar multimodal end-to-end yang menghubungkan encoder visi dan model bahasa besar untuk visi umum dan pemahaman bahasa.
- Fungsi:
- Tugas berbasis teks: LLaVA dapat memproses dan menganalisis teks, memungkinkan pengguna untuk mengajukan pertanyaan, mengobrol dengan pengguna, atau menyelesaikan tugas yang dimasukkan oleh pengguna, seperti mengekstrak ringkasan dokumen, analisis sentimen, pengenalan entitas, dll.
- Tugas berbasis gambar: LLaVA dapat menganalisis gambar, mendeskripsikan gambar, melakukan pengenalan objek, serta menganalisis dan memahami adegan.
- Performa: Eksperimen awal menunjukkan bahwa kemampuan obrolan multimodal LLaVA terkadang dapat menghasilkan performa yang sebanding dengan GPT-4 pada gambar/perintah yang tidak terlihat, dan sebanding dengan GPT-4 pada kumpulan data yang mengikuti perintah multimoda sintetik, memperoleh skor relatif 85,1%.
MiniGPT-4: Model besar sumber terbuka multimodal yang lahir dari LLaMA, “pengganti” GPT-4 untuk pengguna individu
- Tim: Rilis model besar multi-modal GPT-4 telah mendorong antusiasme publik terhadap model besar ke klimaks baru. Namun, GPT-4 tidak sepenuhnya gratis untuk individu. Jika Anda ingin menggunakan GPT-4, Anda harus memberikan undangan resmi atau meningkatkan ke akun berbayar. Tetapi meskipun Anda membayar, beberapa area tidak dapat membeli layanan terkait. Di lingkungan ini, Deyao Zhu, Jun Chen, dan lainnya dari Universitas Sains dan Teknologi King Abdullah merilis MiniGPT-4 pada tanggal 23 April, yang bertujuan untuk menggabungkan informasi visual dari pembuat enkode visual terlatih dengan model bahasa besar yang canggih.
- Teknologi: Secara khusus, MiniGPT-4 menggunakan komponen visi pra-terlatih yang sama dengan BLIP-2, yang terdiri dari ViT-G/14 EVA-CLIP dan Q-Former, saat menggunakan model bahasa besar penyetelan Vicuna, dapat melakukan berbagai bahasa kompleks tugas.
- Fungsi: MiniGPT-4 dapat mewujudkan banyak cara untuk bermain, seperti mengunggah foto pesta makanan laut, Anda bisa mendapatkan resep; mengunggah gambar rendering produk, Anda bisa mendapatkan salinan dengan barang; kode HTML. Menurut umpan balik dari orang-orang yang telah menggunakannya, efek keseluruhan MiniGPT-4 bagus, tetapi dukungan untuk bahasa Mandarin saat ini perlu ditingkatkan.
mPLUG-Owl: Model Besar Multimodal Modular
- Tim: mPLUG-Owl adalah karya terbaru dari seri mPLUG Akademi DAMO Alibaba. Ini melanjutkan ide pelatihan modular dari seri mPLUG dan memigrasikan model bahasa besar menjadi model besar multimodal.
- Teknologi: mPLUG-Owl menggunakan CLIP ViT-L/14 sebagai modul visual dasar, menggunakan struktur yang diinisialisasi oleh LLaMA sebagai dekoder teks, dan menggunakan struktur Perceiver Resampler yang mirip dengan Flamingo untuk mengatur ulang fitur visual. Selain itu, mPLUG-Owl mengusulkan satu set tes Owl yang komprehensif untuk evaluasi instruksi terkait penglihatan untuk pertama kalinya.
- Fungsi: mPLUG-Owl memiliki kemampuan dialog multi-putaran yang kuat, kemampuan penalaran, dan kemampuan interpretasi lelucon. Selain itu, tim peneliti juga mengamati bahwa mPLUG-Owl mulai menunjukkan beberapa kemampuan yang tidak terduga, seperti asosiasi multi-gambar, multi-bahasa, pengenalan teks, dan pemahaman dokumen.
- Performa: Eksperimen membuktikan bahwa mPLUG-Owl lebih unggul dari BLIP2, LLaVA, dan MiniGPT4 dalam tugas respons perintah terkait penglihatan.
5.2 Spesialisasi: Kekuatan ekologi hilir, menyempurnakan model untuk tugas tertentu
Sumber terbuka model besar memberikan peluang bagus untuk pertumbuhan ekologi hilir yang kuat Di bawah pengembangan industri yang terbagi, model besar mulai dikembangkan lebih lanjut pada tugas-tugas tertentu dan mengubah kehidupan manusia. Sejak peluncuran LLaMA model besar open source, model khusus hilir berdasarkan penyempurnaan model pra-pelatihan LLaMA telah mulai muncul, seperti Huatuo di bidang konsultasi medis.
- Tim: Hua Tuo adalah model instruksi LLaMa yang disempurnakan berdasarkan pengetahuan medis Cina. Ini bekerja dengan baik pada tingkat interogasi cerdas dan dapat menghasilkan beberapa jawaban pengetahuan medis yang lebih andal. Dalam domain biomedis, model model bahasa besar yang diterbitkan berkinerja buruk karena kurangnya kumpulan keahlian medis tertentu. Pada 14 April, tim dari Harbin Institute of Technology merilis Hua Tuo, model konsultasi cerdas sumber terbuka untuk bidang medis, yang diperoleh setelah menyempurnakan model LLaMa.
- Teknologi: LLaMA memiliki banyak versi termasuk 7 miliar hingga 65 miliar parameter. Untuk melatih lebih cepat dan efisien serta menghemat biaya pelatihan, Huatuo menggunakan versi 7 miliar parameter LLaMA sebagai model dasar. Untuk memastikan keakuratan model dalam menjawab pertanyaan di bidang medis, para peneliti mengekstraksi pengetahuan medis yang relevan dari grafik pengetahuan medis China CMeKG, menghasilkan berbagai data instruksi, dan mengumpulkan lebih dari 8.000 data instruksi untuk penyempurnaan yang diawasi. untuk memastikan bahwa model menjawab Kebenaran faktual dari pertanyaan tersebut.

- Performa: Dalam hal performa model, HuaTuo dibandingkan dengan tiga model benchmark lainnya. Untuk mengevaluasi kinerja model, para peneliti merekrut lima dokter profesional dengan latar belakang medis untuk mengevaluasi tiga dimensi keselamatan, kegunaan, dan stasioneritas (SUS). Skala SUS berkisar dari 1 (tidak dapat diterima) hingga 3 (baik), dengan 2 menunjukkan respons yang dapat diterima. Skor SUS rata-rata ditunjukkan pada grafik di bawah ini. Hasilnya menunjukkan bahwa model HuaTuo secara signifikan meningkatkan ketersediaan pengetahuan tanpa mengorbankan terlalu banyak keamanan.

Huatuo mungkin menjadi paradigma untuk pengembangan model tugas spesifik hilir model besar open source di masa depan, yaitu, gunakan model besar open source kecil dengan volume parameter rendah sebagai model dasar, dan latih dengan data dari bidang profesional tertentu untuk mendapatkan model domain segmentasi kinerja yang lebih baik.
6. Saran Investasi
Pengembangan model besar sumber terbuka berdampak luas. Laporan ini memilih beberapa arah yang mungkin bermanfaat, dan menarik perhatian pasar.
6.1 Microsoft: Kerjasama mendalam dengan OpenAI
Kami percaya bahwa dalam jangka pendek, sistem ChatGPT masih merupakan model besar yang paling mumpuni, dan Microsoft akan mendapat manfaat dari kerja sama yang mendalam.
- Equity On, menurut laporan majalah “Fortune”, setelah gelombang pertama investor di OpenAI memulihkan modal awal, Microsoft akan berhak atas 75% keuntungan OpenAI hingga Microsoft memulihkan biaya investasi ($13 miliar); Setelah keuntungan OpenAI sebesar $92 miliar, pangsa Microsoft akan turun menjadi 49%. Pada saat yang sama, investor ventura lain dan karyawan OpenAI juga akan berhak atas 49% keuntungan OpenAI sampai mereka menghasilkan sekitar $150 miliar. Jika batas tersebut tercapai, saham Microsoft dan investor akan dikembalikan ke yayasan nirlaba OpenAI.
- Pada produk, selain memungkinkan mesin pencari Bing untuk mengintegrasikan ChatGPT, pada Januari 2023, Microsoft mengumumkan peluncuran layanan Azure OpenAI.Pelanggan Azure Global Enterprise dapat langsung menghubungi model OpenAI di platform cloud, termasuk model GPT3 5. Codex dan DALL.E, tak lama kemudian, Microsoft mengumumkan integrasi GPT4 ke dalam versi pemutakhiran Bing dan Office baru, Copilot.
Nvidia 6.2: Model besar sumber terbuka mendorong popularitas aplikasi, dan permintaan daya komputasi melonjak
Layanan daya komputasi adalah arah dengan manfaat dan kepastian yang kuat dalam gelombang model besar sumber terbuka.Ini memiliki keunggulan yang jelas dalam integrasi perangkat lunak dan perangkat keras, dan merupakan pemimpin saat ini dalam daya komputasi AI.
6.2.1 Permintaan daya komputasi model super besar akan mempertahankan pertumbuhan yang tinggi
Model super besar ini memiliki keunggulan kualitas yang luar biasa, dan pasar akan terus mengejarnya, dan permintaannya akan daya komputasi akan terus meningkat. Model super besar memiliki daya ekspresif yang kuat dan akurasi tinggi, serta memiliki keunggulan dalam kualitas, dan pasar akan terus mengejar model seperti itu. Skala model super besar, kumpulan data, dan aktivitas sehari-hari terus berkembang, dan daya komputasi yang dibutuhkan akan terus meningkat.
6.2.2 Pengejaran cepat model besar open source juga akan menguntungkan daya komputasi
Dalam jangka pendek, pasar akan menunggu dan melihat model besar open source. Model sumber terbuka besar memiliki keserbagunaan yang buruk dan tidak dapat bersaing dengan model berskala besar dalam waktu singkat. Selain itu, saat ini sulit untuk mengevaluasi secara sistematis kinerja model tertentu. Pasar memegang sikap menunggu dan melihat menuju model sumber terbuka besar, menunggu mereka membuktikan kinerja dan keunggulannya.
** Dalam jangka menengah dan panjang, model besar open source diharapkan dapat lebih meningkatkan kinerja, sehingga menempati pangsa pasar yang lebih besar. **Dibandingkan dengan model super besar, model skala besar sumber terbuka memiliki persyaratan daya komputasi yang lebih rendah dan lebih mudah diterapkan. Mereka juga dapat dioptimalkan untuk bidang profesional tertentu melalui penyetelan cepat dan metode lain, yang menarik dan praktis . Dalam jangka menengah hingga panjang, jika ada model besar open source yang dapat mendekati atau melampaui kinerja ChatGPT dalam hal kualitas, permintaan pasar untuk model tersebut dapat meningkat pesat. Sejalan dengan itu, permintaan daya komputasi jenis ini akan meningkat dengan cepat.
6.2.3 Katalis: Pengembangan Lisensi Model Besar Open Source, Standar, dan Sistem Evaluasi Kemampuan
- Lisensi: Kami percaya bahwa sistem lisensi yang telah lama dikembangkan oleh komunitas open source telah memperkaya pilihan pengembang dan membantu model besar memilih lisensi yang sesuai untuk mereka, sehingga mempromosikan aplikasi komersial. Kemakmuran dan pengembangan model besar jelas akan mendorong permintaan pasar akan daya komputasi.
- Standar: Kami berharap komunitas model besar juga dapat menghasilkan standar yang mirip dengan LSB standar pengembangan Linux. Standardisasi yang tepat akan mencegah ekologi model besar menjadi terlalu terfragmentasi. Kami optimis dengan vitalitas berkelanjutan dari komunitas open source untuk mempromosikan kinerja penyedia layanan daya komputasi seperti Nvidia.
- Sistem Evaluasi Kemampuan Model Besar: Sistem evaluasi kemampuan model besar yang kredibel akan membantu pasar dengan cepat membedakan model besar dan berkontribusi pada pengembangan track model besar.
6.3 Meta: Open source “pelopor”, memanfaatkan ekologi open source
Melihat kembali sejarah perkembangan Android, kami optimis dengan peran mirip Google dalam sistem “Google-Android”. Dalam sistem ini, Google sebagai pengembang sistem operasi open source Android menggunakan open source sebagai alatnya. untuk merangsang pengembangan ekologi hulu dan hilir, dan meningkatkan Eksposur layanan miliknya kepada pelanggan akhir.
Dipetakan ke model besar, kami percaya bahwa Meta sumber terbuka LLaMA dapat memperdalam kerja sama dengan produsen pengembangan model hilir besar melalui LLaMA, dan menjual produk berpemilik dalam sistemnya sendiri kepada pelanggan.
6.4 Lainnya
6.4.1 Edge Computing Power + Model Sumber Terbuka: Akselerator Pendaratan untuk Aplikasi AI
Daya komputasi tepi dapat menempatkan perhitungan penalaran pada perangkat pengguna, yang tidak hanya dapat meningkatkan kecepatan dan efisiensi pemrosesan data, sehingga mengurangi biaya penalaran, tetapi juga melindungi privasi dan keamanan pengguna.
- Modul pintar: Sebagai model terbaik untuk menghadirkan daya komputasi terdepan, ini adalah variasi yang paling deterministik dan fleksibel di bawah banyaknya volume produk pintar yang diwujudkan di masa depan. Disarankan untuk memperhatikan MeiG Intelligence dan Fibocom.
- Edge IDC: Dengan kelebihannya dalam waktu tunda dan biaya, ini adalah suplemen yang efektif untuk memenuhi distribusi daya komputasi “berbentuk tangga”. Disarankan untuk memperhatikan saham Longyu dan Teknologi Wangsu.
- Modul Optik: Zhongji InnoLight, Xinyisheng, Komunikasi Tianfu, Teknologi Yuanjie.
- Produsen chip komunikasi IoT tradisional: Diharapkan mendapat manfaat dari proses peningkatan industri. Disarankan untuk memperhatikan: ZTE, Fii, Tsinghua Unigroup, Jaringan Ruijie, Feiling Kesi, Teknologi Aojie, Informasi Chuling.
6.4.2 Perusahaan data besar: Optimis tentang kombinasi “model besar sumber terbuka + data besar milik sendiri”
Untuk perusahaan yang “memiliki banyak data tetapi daya komputasi tidak mencukupi”, menggunakan data mereka sendiri untuk sepenuhnya melatih dan menyempurnakan model komersial sumber terbuka lebih hemat biaya. Ini dapat meningkatkan akurasi dan penerapan model, dan juga dapat sangat mengurangi waktu dan biaya pelatihan model. Selain itu, model yang disesuaikan dapat memenuhi kebutuhan spesifik dan skenario bisnis perusahaan dengan lebih baik, sehingga meningkatkan daya saing dan kemampuan inovasi perusahaan. Dengan pengembangan berkelanjutan dan mempopulerkan teknologi, model fine-tuning independen telah menjadi sarana penting bagi perusahaan untuk menggunakan data mereka sendiri untuk mewujudkan aplikasi cerdas dengan cepat.
6.4.3 Penyedia Layanan Model Besar Sumber Terbuka: Utamakan Layanan
Melihat kembali sejarah pengembangan Red Hat, kami percaya bahwa meskipun model besar memasuki era open source, layanan berorientasi pelanggan 24*7 tetap penting, terutama untuk perusahaan. Kami optimis tentang penyedia layanan model besar sumber terbuka.
6.4.4 Apple: Dapatkan Bagi Hasil Aplikasi ChatGPT
ChatGPT terdaftar di App Store, dan menurut praktik App Store, Apple akan mendapat bagian dari pendapatan.