Autor | The Economist Translator |
Verantwortlicher Redakteur | Xia Meng
Eintrag | CSDN (ID: CSDNnews)
 Bildquelle: Erstellt von Unbounded AI
Bildquelle: Erstellt von Unbounded AI
Wenn die KI besser werden soll, muss sie mit weniger Ressourcen mehr leisten.
Wenn man von „Large Language Models“ (LLMs) wie dem GPT (Generative Pre-trained Transformer) von OpenAI spricht – dem Kernantrieb der beliebten Chatbots in den Vereinigten Staaten – ist der Name Programm. Solche modernen KI-Systeme werden von riesigen künstlichen neuronalen Netzen angetrieben, die die Funktionsweise biologischer Gehirne weitgehend nachahmen. GPT-3, veröffentlicht im Jahr 2020, ist ein großes Sprachmodell-Gigant mit 175 Milliarden „Parametern“, so die Bezeichnung für die simulierten Verbindungen zwischen Neuronen. GPT-3 wird trainiert, indem in wenigen Wochen Billionen von Textwörtern mit Tausenden von KI-fähigen GPUs verarbeitet werden, was geschätzte Kosten von mehr als 4,6 Millionen US-Dollar verursacht.
In der modernen KI-Forschung herrscht jedoch Konsens: „Größer ist besser und größer ist besser.“ Daher hat sich die Skalenwachstumsrate des Modells rasant weiterentwickelt. GPT-4 wurde im März veröffentlicht und verfügt schätzungsweise über etwa eine Billion Parameter – eine fast sechsfache Steigerung gegenüber der vorherigen Generation. Sam Altman, CEO von OpenAI, schätzt, dass die Entwicklung mehr als 100 Millionen US-Dollar gekostet hat. Und die Branche insgesamt zeigt den gleichen Trend. Das Forschungsunternehmen Epoch AI prognostiziert, dass sich die für das Training von Topmodellen erforderliche Rechenleistung im Jahr 2022 alle sechs bis zehn Monate verdoppeln wird (siehe Grafik unten).
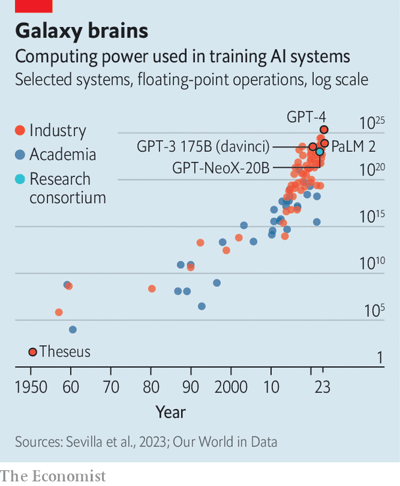 Die ständig zunehmende Größe der KI-Modellparameter wirft einige Probleme auf. Wenn die Vorhersagen von Epoch AI stimmen und sich die Trainingskosten alle zehn Monate verdoppeln, könnten die Trainingskosten bis 2026 eine Milliarde Dollar überschreiten – und das nur unter der Voraussetzung, dass die Daten nicht vorher erschöpft sind. Eine Analyse im Oktober 2022 prognostizierte, dass der hochwertige Text, der für die Schulung verwendet wird, im gleichen Zeitraum erschöpft sein könnte. Auch nach Abschluss des Modelltrainings können die tatsächlichen Kosten für den Betrieb eines großen Modells unerschwinglich hoch sein.
Die ständig zunehmende Größe der KI-Modellparameter wirft einige Probleme auf. Wenn die Vorhersagen von Epoch AI stimmen und sich die Trainingskosten alle zehn Monate verdoppeln, könnten die Trainingskosten bis 2026 eine Milliarde Dollar überschreiten – und das nur unter der Voraussetzung, dass die Daten nicht vorher erschöpft sind. Eine Analyse im Oktober 2022 prognostizierte, dass der hochwertige Text, der für die Schulung verwendet wird, im gleichen Zeitraum erschöpft sein könnte. Auch nach Abschluss des Modelltrainings können die tatsächlichen Kosten für den Betrieb eines großen Modells unerschwinglich hoch sein.
Anfang des Jahres schätzte Morgan Stanley, dass das Unternehmen zusätzliche 6 Milliarden US-Dollar pro Jahr kosten könnte, wenn die Hälfte der Google-Suchanfragen über aktuelle GPT-Programme abgewickelt würden. Diese Zahl wird wahrscheinlich weiter steigen, wenn die Größe des Modells zunimmt.
Infolgedessen ist die Ansicht vieler Menschen, dass KI-Modelle „groß, desto besser“ sind, nicht mehr gültig. Wenn sie KI-Modelle weiter verbessern (ganz zu schweigen von der Verwirklichung größerer KI-Träume), müssen Entwickler herausfinden, wie sie mit begrenzten Ressourcen eine bessere Leistung erzielen können. Wie Herr Altman diesen April im Rückblick auf die Geschichte der groß angelegten KI sagte: „Ich denke, wir haben das Ende einer Ära erreicht.“
Quantitatives Crunching
Stattdessen konzentrierten sich die Forscher auf die Verbesserung der Effizienz des Modells und nicht nur auf das Streben nach Skalierung. Eine Möglichkeit besteht darin, einen Kompromiss zu erreichen, indem die Anzahl der Parameter reduziert, aber mehr Daten zum Trainieren des Modells verwendet werden. Im Jahr 2022 trainierte die DeepMind-Abteilung von Google einen LLM mit 70 Milliarden Parametern namens Chinchilla auf einem Korpus von 1,4 Billionen Wörtern. Obwohl dieses Modell weniger Parameter als die 175 Milliarden von GPT-3 und Trainingsdaten von nur 300 Milliarden Wörtern hatte, übertraf es GPT-3. Wenn ein kleineres LLM mit mehr Daten versorgt wird, dauert das Training länger, das Ergebnis ist jedoch ein kleineres, schnelleres und kostengünstigeres Modell.
Eine andere Möglichkeit besteht darin, die Genauigkeit von Gleitkommazahlen reduzieren zu lassen. Durch die Reduzierung der Anzahl der Genauigkeitsstellen in jeder Zahl im Modell, d. h. durch Rundung, können die Hardwareanforderungen drastisch gesenkt werden. Forscher am Österreichischen Institut für Wissenschaft und Technologie haben im März gezeigt, dass Rundungen den Speicherverbrauch eines GPT-3-ähnlichen Modells drastisch reduzieren können, sodass das Modell auf einer High-End-GPU statt auf fünf mit „vernachlässigbarem Genauigkeitsverlust“ ausgeführt werden kann. " ".
Einige Benutzer stimmen ein allgemeines LLM so ab, dass es sich auf bestimmte Aufgaben wie die Erstellung von Rechtsdokumenten oder die Erkennung gefälschter Nachrichten konzentriert. Dies ist zwar nicht so komplex wie die erstmalige Ausbildung eines LLM, kann aber dennoch teuer und zeitaufwändig sein. Die Feinabstimmung des Open-Source-LLaMA-Modells mit 65 Milliarden Parametern von Meta (Facebooks Muttergesellschaft) erforderte mehrere GPUs und dauerte Stunden bis Tage.
Forscher der University of Washington haben eine effizientere Möglichkeit gefunden, ein neues Guanaco-Modell von LLaMA auf einer einzigen GPU an einem Tag mit vernachlässigbarem Leistungsverlust zu erstellen. Teil des Tricks ist eine Rundungstechnik ähnlich der der österreichischen Forscher. Sie verwendeten aber auch eine Technik namens Low-Rank Adaptation (LoRA), bei der die vorhandenen Parameter des Modells korrigiert und dann ein neuer, kleinerer Parametersatz hinzugefügt werden. Die Feinabstimmung erfolgt durch die Änderung nur dieser neuen Variablen. Das vereinfacht die Sache so weit, dass selbst ein relativ schwacher Computer, etwa ein Smartphone, dieser Aufgabe gewachsen ist. Wenn LLM auf dem Gerät des Benutzers statt im derzeitigen riesigen Rechenzentrum ausgeführt werden kann, kann dies zu einer stärkeren Personalisierung und einem besseren Datenschutz führen.
Unterdessen bietet ein Team bei Google neue Optionen für diejenigen an, die mit kleineren Modellen leben können. Dieser Ansatz konzentriert sich darauf, spezifisches Wissen aus einem großen allgemeinen Modell zu extrahieren und es in ein kleineres und spezialisiertes Modell umzuwandeln. Das große Modell fungiert als Lehrer und das kleine Modell als Schüler. Die Forscher ließen die Lehrer Fragen beantworten und ihre Argumentation demonstrieren. Sowohl die Antworten als auch die Schlussfolgerungen des Lehrermodells (großes Modell) werden zum Trainieren des Schülermodells (kleines Modell) verwendet. Das Team trainierte erfolgreich ein Schülermodell mit nur 7,7 Milliarden Parametern (das kleine Modell), um sein Lehrermodell mit 540 Milliarden Parametern (das große Modell) bei bestimmten Inferenzaufgaben zu übertreffen.
Ein anderer Ansatz besteht darin, die Art und Weise zu ändern, wie das Modell aufgebaut ist, anstatt sich auf die Funktionsweise des Modells zu konzentrieren. Die meisten KI-Modelle werden in der Python-Sprache entwickelt. Es ist so konzipiert, dass es einfach zu bedienen ist, sodass der Programmierer nicht darüber nachdenken muss, wie das Programm den Chip während der Ausführung bedient. Der Preis für das Maskieren dieser Details besteht darin, dass der Code langsamer ausgeführt wird. Diesen Implementierungsdetails mehr Aufmerksamkeit zu schenken, kann sich enorm auszahlen. Wie Thomas Wolf, wissenschaftlicher Leiter des Open-Source-KI-Unternehmens Hugging Face, es ausdrückt, ist dies „ein wichtiger Aspekt der aktuellen Forschung im Bereich der künstlichen Intelligenz“.
optimierter Code
Beispielsweise veröffentlichten Forscher der Stanford University im Jahr 2022 eine verbesserte Version des „Aufmerksamkeitsalgorithmus“, der es großen Sprachmodellen (LLMs) ermöglicht, die Zusammenhänge zwischen Wörtern und Konzepten zu lernen. Die Idee besteht darin, den Code zu modifizieren, um zu berücksichtigen, was auf dem Chip passiert, auf dem er läuft, insbesondere um zu verfolgen, wann bestimmte Informationen abgerufen oder gespeichert werden müssen. Ihrem Algorithmus gelang es, die Trainingsgeschwindigkeit von GPT-2, einem frühen großen Sprachmodell, zu verdreifachen und außerdem seine Fähigkeit zu verbessern, längere Abfragen zu verarbeiten.
Saubererer Code kann auch mit besseren Tools erreicht werden. Anfang dieses Jahres veröffentlichte Meta eine neue Version seines KI-Programmierframeworks PyTorch. Indem Programmierer dazu gebracht werden, mehr darüber nachzudenken, wie Berechnungen auf tatsächlichen Chips organisiert werden sollen, kann die Geschwindigkeit, mit der Modelle trainiert werden können, durch Hinzufügen einer einzigen Codezeile verdoppelt werden. Modular, ein von ehemaligen Apple- und Google-Ingenieuren gegründetes Startup, veröffentlichte letzten Monat eine neue KI-fokussierte Programmiersprache namens Mojo, die auf Python basiert. Mojo gibt Programmierern die Kontrolle über alle Details, die früher abgeschirmt waren, und in einigen Fällen kann mit Mojo geschriebener Code tausende Male schneller ausgeführt werden als ein entsprechender in Python geschriebener Codeblock.
Die letzte Option besteht darin, den Chip zu verbessern, der den Code ausführt. Obwohl GPUs ursprünglich für die komplexe Grafik moderner Videospiele entwickelt wurden, sind sie überraschend gut bei der Ausführung von KI-Modellen. Ein Hardwareforscher bei Meta sagte, dass GPUs für „Inferenz“ (d. h. die tatsächliche Ausführung eines Modells nach dem Training) nicht perfekt ausgelegt seien. Aus diesem Grund entwickeln einige Unternehmen ihre eigene, speziellere Hardware. Google betreibt die meisten seiner KI-Projekte bereits auf seinen hauseigenen „TPU“-Chips. Meta mit seinem MTIA-Chip und Amazon mit seinem Inferentia-Chip versuchen etwas Ähnliches.
Es kann überraschend sein, dass manchmal einfache Änderungen wie das Runden von Zahlen oder das Wechseln der Programmiersprache zu enormen Leistungssteigerungen führen können. Dies spiegelt jedoch die rasante Entwicklung großer Sprachmodelle (LLM) wider. Viele Jahre lang waren große Sprachmodelle in erster Linie ein Forschungsprojekt, und der Schwerpunkt lag hauptsächlich darauf, sie zum Laufen zu bringen und gültige Ergebnisse zu liefern, und nicht auf die Eleganz ihres Designs. Erst vor kurzem wurden sie in kommerzielle Massenmarktprodukte umgewandelt. Die meisten Experten sind sich einig, dass es noch viel Raum für Verbesserungen gibt. Chris Manning, ein Informatiker an der Stanford University, sagte: „Es gibt keinen Grund zu der Annahme, dass die derzeit verwendete neuronale Architektur (bezogen auf die aktuelle neuronale Netzwerkstruktur) optimal ist, und es ist nicht ausgeschlossen, dass fortschrittlichere Architekturen auftauchen werden.“ in der Zukunft."