Фахівці гуманітарних наук не завжди змінюють світ, але саме вони стикаються з його наслідками.
Часом здається, що продавці курсів із ШІ трактують його як магію: запропонуй чудову підказку — і можна все. Насправді все набагато складніше. Від заснування FUNES ми щоденно використовуємо ШІ у виробництві. Поруч із такими проєктами, як Fuyou Tiandi і моїми власними текстами, людських ресурсів стало недостатньо. Тому ми активно досліджували, як ШІ може підтримати наш контентний ринок і гуманітарні дослідження.
Коли з’явилися нові колеги, я підготував просту презентацію Keynote. Дізнавшись про неї, Jia Xingjia запросила мене виступити. Разом із партнером Keda ми дали доповіді назву “Посібник із використання ШІ для гуманітаріїв”. Спочатку це була приватна сесія, присвячена загальним принципам. З часом ми її доповнили й удосконалили.
Однак цей посібник вперше був оприлюднений лише цього року — під час запуску Shishufeng із Чунціном, де ми вперше обговорили його повністю. Текст нижче — адаптація подкасту “Посібник із використання ШІ для гуманітаріїв”, створена за допомогою ШІ і частково скорочена. Повну версію слухайте на офіційному сайті або знайдіть “Shishufeng” на Yuzhou чи Apple Podcasts.
QR-код Xiaoyuzhou
Протягом року я ділився цими практиками ШІ із колегами у сфері створення контенту, досліджень та знання. Мета — не навчити кількох магічних підказок чи сприймати ШІ як панацею. Це методологія: спосіб інтегрувати великі мовні моделі у написання, дослідження, редагування, вибір тем, організацію даних та виробничі процеси без кодування, забезпечуючи простежуваність, контроль і перевірку, аби ви могли впевнено підписуватися під результатом.
Такий підхід виник із реального досвіду: коли виробництво контенту масштабувалося, людських зусиль стало недостатньо; але пряме генерування ШІ призводить до галюцинацій, скорочень і штучного звучання тексту. Ми змушені були перетворити творчість на виробничу лінію, а лінію — на ітераційну систему.
Замість списку підказок я ділюся основними принципами.
Перед принципами: три базові умови цього посібника
Перш ніж перейти до методів, визначте три базові умови. Вони визначають і “як ви використовуєте ШІ”, і “чому саме так”.
Процес має бути простежуваним, контрольованим і перевіряним
- Не можна просто чекати результату і ігнорувати процес. Для гуманітарної роботи чорні ящики найнебезпечніші: галюцинації, неправильні цитати й концептуальні зсуви виникають у темряві.
Він має бути керованим
- Ви повинні визначати, як він працює, за якими стандартами, де сповільнити, а де бути суворим. Це виробництво, а не гра випадку.
Ви маєте бути готові підписатися під результатом
- “Чи готовий я підписати це своїм ім’ям?” — це остаточна перевірка якості. Якщо ні, це не питання моралі — просто ваш задум не реалізований у процесі, тому якість не гарантована.
Принцип 0: Не загадуйте бажання ШІ — сприймайте його як робочий стіл
Багато хто сприймає ШІ як машину для виконання бажань:
“Дай хороший жарт”, “Напиши для мене гарну статтю”, “Поясни цю статтю”.
Та “пояснити” має безліч тлумачень: для неспеціалістів, студентів, аспірантів чи колег. ШІ не знає вашого бекграунду, цілей, уподобань чи стандартів за замовчуванням. Якщо ви не уточнюєте, він обирає найпростіший шлях.
Сприймати великі моделі як робочий стіл означає: не просити готовий результат, а використовувати інструменти ШІ для процесу. Уточнюйте редакцію, стандарти та етапи.
Наприклад, якщо просите ШІ пояснити статтю
Перетворіть бажану підказку (“поясни цю статтю”) на завдання для робочого столу:
-
Визначте аудиторію: розумні, допитливі аспіранти, які не є експертами у сфері
-
Визначте стиль пояснення: евристичний, поетапний, академічно строгий
-
Визначте структуру: значення, бекграунд, процес дослідження, ключові технічні моменти, потім висновки
-
Визначте тон: поважний, не поблажливий, без припущення глибоких знань
Чим більше ваші інструкції схожі на “вимоги до завдання”, тим менше ШІ поводиться як ШІ і більше як компетентний помічник.
Принцип 1: Щоб ШІ був ефективним, рефлексуйте — ви відповідальні
Якби ви найняли секретаря, ви не сказали б:
“Виправ статтю Han Yang про американський Rust Belt.”
Ви додали б:
Чому існує ця стаття, для кого вона, де ви застрягли, яку проблему хочете вирішити, недоторкані розділи, бажаний стиль і що найважливіше.
ШІ не відрізняється. Сприймайте його як старанного, ввічливого колегу, який не має ваших неявних припущень. Справжній “інжиніринг підказок” — це питання відповідальності: завдання залишається вашим, ШІ лише допомагає виконати.
Якщо результат ШІ вас не задовольняє, найефективніший перший крок — не “ШІ не впорався”, а:
-
Чи я чітко визначив “аудиторію/мету/ціль”?
-
Чи я дав достатньо бекграунду та обмежень?
-
Чи я розбив “абстрактні бажання” на “конкретні дії”?
-
Чи я визначив стандарти оцінки?
Принцип 2: Запитуйте щонайменше три моделі — кожна ШІ має свою “особистість” і сильні сторони
У нашій компанії я раджу новим колегам спочатку звертатися до трьох різних ШІ з одним питанням. Як і люди, ШІ різні: одні краще пишуть, інші краще міркують, кодують чи використовують інструменти. Навіть моделі однієї компанії чи нові версії можуть змінювати “стиль” і “межі”.
Проста і ефективна звичка: запитайте щонайменше три ШІ одне питання, і ви швидко зрозумієте:
-
Хто краще пише, хто краще міркує, хто краще шукає, хто скорочує кути
-
Хто найкраще підходить для чорновиків, хто для перевірки
-
Хто краще для “тем/структури”, хто для “абзаців/речень”
Цінність не у виборі “найсильнішої моделі”, а у керуванні моделями як командою — не як єдиним оракулом.
Принцип 3: ШІ не всезнаючий — сприймайте його як “сильного студента”
Практичне очікування:
Здоровий глузд ШІ ≈ студент топового університету.
Якщо ви думаєте, що “навіть сильний студент цього може не знати”, припускайте, що ШІ теж не знає — або що він “майстерно вигадує”, коли не знає.
Це веде до двох прямих дій:
Ви повинні навчити його всьому, що виходить за межі здорового глузду
- Наприклад: хочете жарти, унікальний копірайт чи вузькоспеціалізовані аргументи? Не просто кажіть “зроби добре”. Дайте приклади, стандарти, заборонені зони та джерела. Якщо вам потрібно час, щоб пояснити другу, що таке хороше письмо, ШІ за замовчуванням цього не знає.
Сприймайте його як стажера, а не як божество
- Він може заповнювати каркас і вплітати ваші матеріали у читабельний текст. Але “каркас” і “напрямок” залишаються вашими.
Принцип 4: Ведіть ШІ поетапно — білий ящик, багатоступеневий підхід надійніший за чорний ящик, одноразовий
Сила ШІ — не у “миттєвих правильних відповідях”, а у надійному виконанні дрібних етапів вашого процесу. Чим більше ви вимагаєте “одноразового результату”, тим більше він скорочує кути.
Ясний приклад: скрипти для TTS (тексту в мовлення) чи озвучення. Замість “стеж за багатозначними символами, не помиляйся”, розбий завдання на етапи:
-
Познач паузи/наголоси/зміни темпу
-
Визнач потенційно багатозначні символи
-
Перевір з словниками чи авторитетними джерелами
-
Попередньо познач поширені, легко помилкові символи
-
За потреби заміни на однозначні омоніми
Люди автоматично виконують ці “очевидно правильні” етапи, але ШІ — ні. Якщо не уточнювати, ШІ обере найпростіший шлях і помилиться.
Принцип 5: Спочатку індустріалізуйте, потім автоматизуйте — не можна стрибати від натхнення до автоматизації
Якщо ваш робочий процес у написанні чи дослідженні хаотичний, випадковий і безсистемний, ШІ не допоможе. Він може обробляти лише те, що “описуване й повторюване”.
Практичніший шлях:
-
Спочатку перетворіть роботу на “виробничу лінію”: роздільну, повторювану, з контролем якості
-
Потім делегуйте підетапи ШІ: нехай він буде робочою станцією, а не божеством
Ми провели важливу вправу: розбили процес написання моєї документальної книги, включаючи:
Зрештою ми розділили процес на десятки етапів, кожен з яких обробляли різні ШІ. Результат:
Модель не стала сильнішою миттєво, але процес об’єднав її “інкрементальні” можливості.
Коли ви можете чітко описати “як створюється моя стаття”, зрозумієте: справжній ліміт якості — не “яку модель ви використовуєте”, а чи ваш робочий процес прозорий.
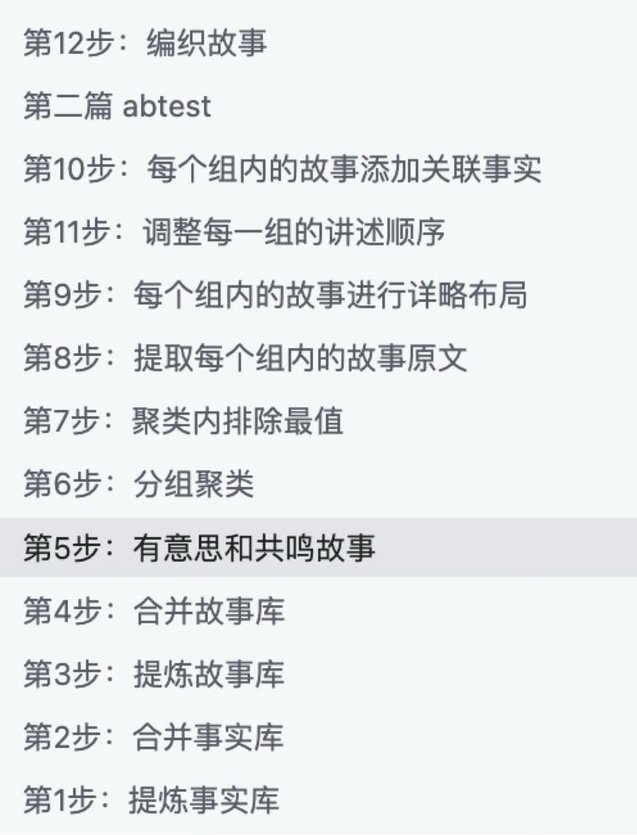
Деякі приклади етапів із наших тестів виробничої лінії
Рекомендую послухати програму для деталей.
Принцип 6: Передбачайте скорочення ШІ — він економить обчислення, тому ви усуваєте “бар’єри формату”
ШІ системно скорочує кути: якщо може не відкривати вебсторінку — не відкриє; якщо може не читати PDF — не читатиме. Це не злий умисел — з огляду на обчислення й час, він обирає найпростіший шлях.
Ваша роль: спрямувати ресурси ШІ на “розуміння тексту”, а не “обробку форматів”.
Ефективні стратегії:
-
Перетворюйте матеріали на чистий текст або Markdown перед введенням
-
Копіюйте веб-контент як чистий текст (без навігації, реклами, приміток)
-
Для довгих матеріалів спочатку витягуйте факти чи структуру, потім просіть ШІ писати
-
Стандартизуйте PDF/EPUB/вебсторінки у searchable TXT-базу
Багато хто чинить опір цій “чорній роботі”, вважаючи, що “машини мають це робити”. Але у співпраці PR-ШІ навпаки — якщо ви виконуєте механічні задачі, інтелект ШІ стає гострішим і надійнішим.
Принцип 7: Пам’ятайте про обмежений контекст — віддавайте перевагу “стисненню”, а не “розширенню з нічого”
У ШІ є контекстне вікно — обмеження пам’яті. Якщо дати 20 000 слів, він запам’ятає лише частину; 200 000 — лише заголовки. Уявіть людину, замкнену з книгою на 200 000 слів на день, потім попросіть переказати — це приблизно “пам’ять” ШІ.
Парадоксально, але важливо:
Стиснення легше за розширення
- Стиснути 1 000 000 слів до 10 000 надійніше, ніж розширити 10 000 до 1 000 000.
Це змінює підхід:
-
Не використовуйте 100-слівну підказку для запиту повної статті
-
Краще дайте максимум матеріалу (порціями, через retrieval war RAG тощо), а потім попросіть ШІ стиснути його у структуру, аргументи й основний текст
Під час написання ви вже “широко читаєте → відбираєте → організуєте → пишете”. Від ШІ очікуйте того ж — не вимагайте творення з нічого.
Принцип 8: Не піддавайтеся імпульсу “Я просто виправлю це” — ітеруйте процес, а не результат
Досвідчені автори часто спотикаються на ШІ:
ШІ створює чернетку на 59 балів; ви думаєте, що зможете підняти до 80, а зрештою переписуєте; після переписування вирішуєте “зроблю сам” і припиняєте використовувати ШІ.
Вирішення — не жорсткіше редагування, а зміщення фокусу на етапи:
-
Не вимагайте від ШІ ідеальних 100 балів
-
Спрямовуйте виробничу лінію на стабільні 75–80
-
Ітеруйте процес, щоб підняти середній бал, а не доводити кожен результат до ідеалу
Принцип 9: Сприймайте робочий процес як ітерацію продукту — цінність у надійності
Система, яка стабільно видає чернетку на 70 балів, цінна не тому, що “схожа на вас”, а тому, що:
-
Ви отримуєте придатний чернетковий текст майже без витрат
-
Можете зосередитися на важливих рішеннях: темі, структурі, доказах, стилі й компромісах
Вам не потрібна всемогутня заміна — лише надійна фабрика: стабільна, хоч і не ідеальна.
Принцип 10: Пріоритет кількості — генеруйте більше, а потім обирайте
Просити ШІ створити одну версію — шлях до посередності. Використовуйте “кількість”, щоб підняти середній рівень.
Ефективні тактики:
-
Резюме: просіть 5 варіантів одразу
-
Вступи: просіть 5 одразу, робіть AB-тести
-
Теми: просіть 50 одразу, потім групуйте й обирайте
-
Структури: просіть 3 комплекти, потім комбінуйте
-
Формулювання: просіть 10 різних виразів, потім обирайте найкраще
Коли підвищуєте середній бал і об’єм, з’являться “сюрпризні зразки” на 85 чи 90 балів. Часто досконалість — не “спалах генія”, а результат статистичного відбору.
Принцип 11: Не переходьте межу — керуйте як шеф-кухар: пробуйте, давайте фідбек, поверніть на доопрацювання
Якщо ви шеф-кухар, ви не готуєте кожну страву особисто. Ви:
-
Пробуєте
-
Оцінюєте відповідність стандартам
-
Даєте чіткий фідбек (що не так, як виправити)
-
Повертаєте кухарю на доопрацювання
Те саме й у співпраці з ШІ. Поважайте процес генерації — навчайте його своїм стандартам замість виправляти кожен результат самостійно.
Інакше нескінченне “дотягування” виснажить вас.
Основний принцип: поверніться до реальності — матеріали × смак визначають ліміт
У епоху ШІ якість вашої роботи дедалі більше залежить від:
Матеріали × смак.
Моделі змінюватимуться, методи еволюціонуватимуть, але ці два фактори залишаються:
Матеріали походять із реального світу
Або використати старішу модель, але з повними архівами, усними історіями й польовими дослідженнями
- Другий варіант часто дає кращі результати.
Смак формується тривалою практикою
-
Коли “генерація” стає дешевою, справді дефіцитним стає:
-
Знати, що варто писати
-
Знати, які докази переконливі
-
Знати, яка оповідь цікава
-
Готовність до глибокої роботи: глибокі занурення, ретельні дослідження, практична перевірка
ШІ змінює ефективність і спосіб роботи з матеріалами, але ви залишаєтесь автором, матеріали — предметом, а ШІ — лише інструментом.
 DiggingTG глибоко й практично для збору вихідних матеріалів
DiggingTG глибоко й практично для збору вихідних матеріалів
Висновок: перетворіть тривогу на експертизу
Багато хто стикається з труднощами у роботі з ШІ не через нестачу інтелекту, а через цикл “бажання — розчарування — відмова”. Справжній прорив — у сприйнятті ШІ як робочого столу, інжинірингу завдань, відкритості процесів і розвитку експертизи через практику.
Коли ви це зробите, менше ймовірно, що скажете “ШІ не працює”; ви станете новим типом професіонала — здатним керувати новими інструментами, без зверхності чи поклоніння, інтегруючи їх у свій робочий процес, свою реальність і роботи, які підписуєте з гордістю.
Я — Han Yang. Якщо вас цікавить моя творчість, підписуйтесь на X або читайте більше на моєму блозі.
Заява:
-
Ця стаття передрукована з [HanyangWang]. Авторські права належать оригінальному автору [HanyangWang]. Щодо питань передруку звертайтеся до команди Gate Learn. Команда оперативно розгляне ваш запит відповідно до встановлених процедур.
-
Відмова від відповідальності: думки й позиції, викладені в цій статті, належать лише автору і не є інвестиційною порадою.
-
Інші мовні версії цієї статті перекладені командою Gate Learn. Якщо не вказано Gate, не копіюйте, не поширюйте й не плагіюйте перекладену статтю.








