オープンソース レース: AI ビッグ モデルの「Linux の瞬間」が到来
オープンソースベンチマークLinuxの開発史からAI大型モデルの未来を見つめる。
執筆者: Song Jiaji、Sun Shuang
ChatGPT のリリース直後、Meta は GPT に似た大規模言語モデル LLaMA をオープンソース化しました。それ以来、Alpaca、Vicuna、Koala などのいくつかの大規模モデルが誕生しました。これらはモデル スケールで優れたパフォーマンスを達成し、コストははるかに低くなりました。これにより、業界関係者は「GoogleにもOpenAIにも外堀がなく、大規模モデルの敷居がオープンソースによって破られつつあり、協力しなければ置き換えられてしまうのではないか」と懸念している。資本市場も大規模モデルの将来の競争パターンに注目しています。小規模モデルはもはや多くの計算能力を必要としませんか?その中でデータはどのような役割を果たしますか? …このレポートは、オープンソースの大規模言語モデルのこの波の共通点を分析し、オープンソースのベンチマークである Linux の開発の歴史をレビューし、これらの質問に答えることを試みます。
**共通点 1: オープンソースから始める。 **オープンソース ≠ 無料. オープンソースのビジネス モデルには少なくとも以下が含まれます: 1. サービスによる収益化。その一例は、かつて上場したが後に IBM に買収された Linux エンタープライズ サービス会社である Red Hat です。企業は、より安定したタイムリーな技術サポートに対して喜んでお金を払います。 2. ライセンス料により実現します。 Android はオープンソースですが、Google は Android Google スイートの使用に対して EU 内のメーカーにライセンス料を請求しています。 3. ライセンス、規格、機能評価システムの開発は、オープンソースの大規模モデルの商業化を深化させる触媒となります。このオープンソースの大規模モデルの波で採用されているライセンス契約は、主に Apache 2.0 と MIT であり、商用利用は禁止されておらず、ユーザーがモデルを変更してソースを閉じることも禁止されていないため、企業がこのような大規模モデルを適用するのに役立ちます。
** 共通点 2: パラメータの削減と小型化。 **1,000 億のパラメータを持つ GPT3+ 超大規模モデルと比較すると、このオープンソースの大規模モデルのパラメータは一般に 10 億から 100 億のレベルです。現時点では体系的な大規模モデルの性能評価システムはなく、信頼性の高い採点基準を設けているタスクは一部のみである。大規模なオープンソース モデルの中でも、Vicuna はより高性能であり、一部のタスクでは 92% の GPT4 パフォーマンスを達成できます。一般的に言えば、OpenAI GPT システムは依然として最良ですが、トレーニング コストが高く、再現するのが困難です。オープンソースの大規模モデルは、より大規模な識別子トレーニング データセット、DeepSpeed、RLHF などの助けを借りて低トレーニング コストと高いパフォーマンスを実現しており、超大規模モデル以下の大規模モデルへの障壁はなくなりつつあります。
** 共通点 3: データセットは人の指示を重視しており、商用利用可能です。 **ChatGPT が GPT3 と比較して大幅に改善された重要な要素は、RLHF (人間のフィードバックに基づく強化学習) の使用です。つまり、トレーニング中に人間が生成した回答を使用し、AI が生成したコンテンツを並べ替えて AI が「調整」できるようにします。人間の好み。 LLaMA は命令の微調整を使用しませんが、LLaMA 後の多数の大規模モデルでは、オープンソースの命令データ セットを使用し、商用制限のある OpenAI を使用する代わりに、徐々に自己構築の命令データ セットを探索することで、再現の敷居がさらに低くなります。 GPT と商業利用可能性を拡大します。
**次にオープンソースのビッグモデルをどう見るか? **オープンソースの大規模モデルの波の中で、私たちは 2 つの傾向に気づきました: 1) マルチモーダリティとの統合、清華大学の VisualGLM-6B は、有名なオープンソース言語モデル ChatGLM のマルチモーダル アップグレード バージョンであり、私たちはそれが可能であると信じています。コンシューマ グレードのグラフィックス カードをベースにしたローカル展開が一般的な傾向です。 2) オープンソースモデル+エッジコンピューティングでAIの商用化を促進 ハルビン大学の中国医療相談モデル「Huatuo」と越境電子商取引での活用例。
投資の提案: 私たちは、大規模なモデルのビューは時間内に階層的に表示されるべきであると考えています。 1. 短期的には、OpenAI の GPT ベースの超大規模モデルは依然として他の大規模オープンソース モデルを上回っているため、株式や製品面で緊密な協力関係にある Microsoft、 ChatGPTiosApp の収益分配と超大型モデルのコンピューティングパワーサービスプロバイダーの獲得が可能 Nvidia など 2. 中長期的には、一部のオープンソース大型モデルの機能がさらに検証されれば、アプリケーションが迅速に展開される、大規模モデルはコンピューティング能力の好循環を形成する; 3. その他: エッジコンピューティング能力、ビッグデータ企業、オープンソース 大規模サービスのビジネスモデルも注目に値します。推奨される注意事項: 1) 光モジュール サービス プロバイダー: Zhongji InnoLight、Xinyisheng、Tianfu Communication、Yuanjie Technology; 2) スマート モジュール サービス プロバイダー: MeiG Smart、Fibocom; 3) エッジ IDC サービス プロバイダー: Longyu 株式、Wangsu Technology; 4) AIoT 通信チップおよび機器メーカー:ZTE、清華Unigroup、Ruijie Networks、Feiling Kesi、Fii、Aojie Technology、Chuling Information; 5) アプリケーション端末ラベル:Yingying Network、Shenzhou Taiyue、Jiaxun Feihong、Zhongke Jincaiなど。
**リスクに関する注意事項: 倫理的リスク、市場競争のリスク、政策および法的監督のリスク。 **
## I.はじめに
このレポートは、オープンソースの大規模言語モデルに対する世間の強い関心を引き起こしました。
1.1 「Google にも OpenAI にも堀はなく、オープンソースによって大規模モデルの敷居が破られつつある」
**「Google と OpenAI が姿勢を変えてオープンソース コミュニティと協力することを選択しない限り、後者に取って代わられるだろう。」 **ブルームバーグとセミアナリシスの報道によると、4 月初旬、Google エンジニアのルーク サーナウ氏は、人工知能ビッグ言語モデル (Large Language Models、LLM、以下「ラージ モデル」) の追跡では、Google と ChatGPT の起動者である OpenAI には堀がなく、オープンソース コミュニティが競争に勝ちつつあります。
この議論により、「年初のメタオープンソース大型モデルLLaMA以降、大量の大型モデルが登場する」という現象のクライマックスが世間の注目を集めた。と「データ」について、大規模モデルの将来の競争パターンはどうなるでしょうか? モデルが小さければ、大規模なモデルは多くの計算能力を必要としなくなりますか? その中でデータはどのような役割を果たしますか? …このレポートは、オープンソースの大規模モデルのこの波の共通点を分析し、オープンソースベンチマーク Linux の開発の歴史を振り返り、上記の質問に答え、大規模モデルの将来に期待することを試みます。

1.2 トレンドとも言えるオープンソースの大規模モデルが集中的に登場
2月24日にMetaがオープンソースの大規模モデルLLaMAをリリースして以来、市場には数多くの大規模モデルが登場しており、大まかに3つのカテゴリーに分けられます。
1.2.1「LLaMAシリーズ」:性能は良いが商品化の度合いは低い
LLaMA には、市販されていない 4 つの異なるパラメーター バージョン (70 億/130 億/330 億/650 億) が含まれており、コマンド データセットは OpenAI に基づいており、モデルのパフォーマンスは GPT-3** 以上となります。 **このうち、70 億と 130 億のパラメータ バージョンには 1 兆のトークンを含む事前トレーニング データ セットがあり、330 億と 650 億のパラメータ バージョンには 1.4 兆のトークンを含む事前トレーニング データ セットがあります。 GPT-3 と比較すると、LLaMA-70 億パラメータ バージョンは常識推論タスク、ゼロショット タスク、自然な質問、読解力に関して GPT-3 と同じレベルで実行しますが、130 億パラメータ以上のバージョン モデルは上記の分野のパフォーマンスは GPT-3 よりも優れています。
LLaMA モデル自体は命令データ セットを使用しませんが、GPT-3 よりも優れた ChatGPT が人間の命令データ セットを使用することを考慮すると、オープンソースの大規模モデルのバッチは OpenAI 命令データ セットを使用してパフォーマンスを最適化します。 LLaMA モデルに基づくモデル。Alpaca、GPT4All、Vicuna、Koala、Open Assistant、Hugging Chat が含まれます。 OpenAI 命令データ セットは市販されていないため、これらの LLaMA ベースのオープンソースの大規模モデルも市販されていません。

1.2.2 Dolly2.0、RedPajama、StableLM など: 高度な商用化
これらの大規模モデルは OpenAI 命令データセットを使用していないため、市販されていますが、ほとんどはまだ継続的に開発中です。
1.2.3 中国のジェミニ: ChatGLM-6B と MOSS
ChatGLM-6B と MOSS は、それぞれ清華大学と復丹大学の関連研究グループによって立ち上げられ、中国コミュニティではよく知られています。
これらのモデルにはいくつかの共通点もあり、以下のレポートで詳しく説明します。

2 番目の共通点 1: オープンソースから始める
** この波では、モデル自体であれ、モデルで使用されるデータセットであれ、最初の共通点は「オープンソース」です。 **
**2.1 なぜオープンソースなのか? **
大型モデルをオープンソース化する市場にとって重要な問題は、なぜオープンソース化する必要があるのか、そしてそれが大型モデル業界のビジネスモデルにダメージを与えるのかどうかということです。オープンソース化の理由について、いくつかの大規模モデルの自己申告を整理し、以下のようにまとめました。
2.1.1 モデルの観点: 大企業の独占を防止し、商業禁止制限を破る
人工知能研究を民主化し、オープンモデルとクローズドモデル間の品質ギャップを埋め、商業禁止制限を取り除くために、オープンソースの大規模モデルの精力的な開発が上記の目標を促進すると予想されます。
2.1.2 データの観点: 企業秘密を保護し、カスタマイズされたデータ トレーニングを可能にする
**データのプライバシーを保証し、企業が開発をカスタマイズできるようにします。 **多くの業界にとって、データは企業の生命線です。大規模モデルのオープンソースにより、企業はデータ制御を実現し、企業データのプライバシーを保護しながら、大規模モデルで独自のデータセットをトレーニングできるようになります。同時に、オープンソースの大規模モデルにより、企業開発者はモデルに基づいてカスタマイズされた開発を実行し、トレーニング データをターゲットにし、特定のトピックをフィルタリングして、モデルのサイズとデータのトレーニング コストを削減することができます。
2.1.3 コンピューティング能力の観点: コンピューティング能力のコストを削減し、大規模なモデルを「包括的」に使用する
**オープンソースの大規模モデルは、トレーニング段階での計算電力消費を節約し、企業の計算電力コストを削減し、大規模モデルの「包括的な」使用を促進します。 **合計の計算能力要件 = シナリオの数* 単一シナリオの計算能力要件。大規模モデルのトレーニングと使用では、計算電力消費は 2 つのシナリオ、つまりトレーニング コストの消費と推論のコストの消費に分けられます。
- トレーニングコストの点では、大規模モデルのトレーニングコストは高く、一般企業の計算能力リソースでは耐えられないほどですが、オープンソースの大規模モデルは主に企業の事前トレーニング段階での計算能力を節約します。ただし、さまざまな分野のトレーニング シナリオが豊富になったため、全体的なトレーニングの需要は増加しています。 ※推論コストに関しては、パラメータが巨大な大規模モデルの推論コストも高く、一般企業では日々の経費を維持することが困難であるため、モデルパラメータのサイズを小さくすることで企業の推論コストをさらに削減できるモデルコストを使用する場合。
**2.2 オープンソース、どのような土壌が必要ですか? **
**オープンソースのメガモデルの隆盛には前例がないわけではなく、世界最大のオープンソース ソフトウェア プロジェクトである Linux にも同様の経緯があります。 **Linux の開発史を研究することは、オープンソースの大規模モデルの将来を展望する上で参考となる意義があります。
2.2.1 オープンソース ベンチマーク Linux から始めましょう
**Linux は、GNU General Public License (GPL) に基づいてリリースされた無料のオープンソース オペレーティング システムです。 **誰でもこのソフトウェアを実行、研究、共有、変更することができます。変更されたコードは、同じライセンスの下でのみ再配布および販売することもできます。 Unix や Windows などの従来のオペレーティング システムは、ベンダーロックされ、現状のまま提供され、変更できない独自のシステムです。
世界最大の産業やビジネスの多くは Linux に依存しています。今日、Linux は、Wikipedia のような知識共有サイトからニューヨーク証券取引所、フリー ソフトウェアを含む Linux カーネルの専用ディストリビューションである Android を実行するモバイル デバイスに至るまで、あらゆる場所に存在しています。現在、Linux は、公共のインターネット サーバーで最も一般的に使用されているオペレーティング システムであるだけでなく、上位 500 の最速スーパーコンピューターで使用されている唯一のオペレーティング システムでもあります。
**サーバー市場では、Linux のシェアがオペレーティング システムの「祖父」である Unix のシェアをはるかに上回り、「Linux モーメント」が起こりました。 **中国市場を例に挙げると、CCID Consulting のデータと設置容量の統計によると、サーバー アーキテクチャの観点からは、Linux が市場の主流であり、市場シェア 79.1 で絶対的なリーダーの地位を占めています。 %。 Windows の市場シェアは 20.1% に低下し、Unix の市場シェアはわずか 0.8% でした。

2.2.2 Linux は独自の作品ではなく、コミュニティの背後にあるオープンソースの歴史を活用しています
Unix はオープンソースであり、Linux に火を与えています
**Unix、現代のオペレーティング システムの創始者。 **オペレーティング システムとは、システム ハードウェアとリソース (CPU、メモリ、ストレージ スペースなど) を直接管理するソフトウェアを指し、アプリケーションとハードウェアの間に位置し、すべてのソフトウェアと関連する物理リソース間の接続を確立する役割を果たします。 Unix は、現代のオペレーティング システムの祖先であると多くの人が考えています。
**Unix はかつてオープンソースでした。 **世界初の汎用コンピュータは 1946 年に誕生し、Unix は 1969 年に開発されました。 UNIX の所有者である AT&T は、10 年間にわたり、低コストまたは無料のライセンスで、研究や教育のために学術機関に Unix ソース コードをライセンスしてきました。多くの機関がこのソース コードを拡張および改良し、いわゆる「Unix」を形成しました。亜種」。その後、AT&T は Unix の商業的価値に気づき、Unix ソース コードを学術機関にライセンスすることをやめ、以前の Unix とその亜種に対する著作権を宣言しました。
クローズドソースに戻った後、Unix は高すぎるため、Linux の開発につながりました
Linux は、1991 年に Linux Torvalds によって設計され、発売されました。当時、彼はまだ大学生でしたが、当時普及していた商用オペレーティング システム Unix は高価すぎると考え、Unix に似たオペレーティング システム Minix をベースにした Linux を開発しました。そして、チームから自分と同じようにお金に余裕のない人々にそれを公開しました。
教育専用の Minix は、Linux の開発に影響を与えました
AT&T がソース コードを私有化した後、オランダのアムステルダム フリーイェ大学のタネンバウム教授は、授業で学生にオペレーティング システムの操作の実践的な詳細を教えるために、AT&T のソース コードを一切使用せずに UNIX 互換の宿題を開発することにしました。著作権紛争を回避します。彼はこれをmini-UNIX(ミニUNIX)という意味を込めてMINIXと呼んだ。 MINIX の最初のバージョンは 1987 年にリリースされ、使用するにはディスクを購入するだけで済みます。 Linux システムが独自のネイティブ ファイル システムを持たない前は、Minix のファイル システムが使用されていました。
オープンソース コミュニティ、ライセンス、標準サポート
** 最初からオープンソース。 **1991 年 8 月、Linux の創始者 Linus Torvalds は Linux を Minix Usenet ニュースグループに投稿しました。その後、より多くの人が一緒にカーネルを開発できるようにしたいと考え、Linux を FTP サイトにリリースしました。

**このライセンスは、生態系の繁栄と繁栄に役立ちます。 **Linux は、GNU GPL ライセンス (GNU の Not Unix General Public License、Genu Project General Public License) モデルに基づいています。 GPL ライセンスは、「フリー ソフトウェア」または「コピーレフト (公的著作権)」がユーザーに与える 4 つの自由を許可します。
- 自由ゼロ: いかなる目的でもソフトウェアを「使用」する自由。
- 自由の 1 つ: 「ソフトウェアがどのように動作するかを研究」し、ユーザー自身のニーズに合わせてソフトウェアを「変更」する自由。ソース コードへのアクセスは、この自由の前提条件です。 ※自由2:「ソフトウェアのコピーを配布する」自由があるので、誰もがフリーソフトウェアを配布することで善隣関係を築くことができます。 ※自由3:コミュニティ全体が利益を得られるように「改訂版を公開する」自由。ソース コードへのアクセスは、この自由の前提条件です。
GPL ライセンスでは、GPL プログラムの派生作品も GPL ライセンス モデルに従うことが求められます。対照的に、BSD スタイルのライセンスでは、派生作品をプロプライエタリ ソフトウェアにすることは禁止されていません。 GPL は、無料のオープンソース ソフトウェアの最も一般的なライセンスです。 GPL ライセンスに準拠することで、Linux エコシステムは発展を続けることができない「行き止まり」に陥らずに繁栄し続けることができます。
**規格は内部的には生態を「形は散在するが精神は散在しない」とし、内部的には「巨大なクジラ」を包含する。 **
- **社内統一規格。 ** Linux では、さまざまなチームの開発結果が大きく異なることを避けるために、開発を標準化するための標準 LSB (Linux Standard Base、Linux Standard Base) を策定しています。したがって、Linux 由来のさまざまな開発ツールは、スイート管理ツールやモードなどの点でのみ異なります。これにより、Linux オープンソース コミュニティの開発が「分散することはあっても、分散することはない」ため、Linux エコシステムの開発が崩壊することはないと考えています。
- **Unix と外部互換性があります。 ** Linux を Unix ソフトウェアと互換性を持たせるために、Linus Torvalds は POSIX (Portable Operating Interface) 標準を参照して Linux を修正し、これにより Linux の使用が大幅に増加しました。この規格は IEEE (米国電気電子学会) によって 1990 年代に開発された Linux の初期段階であり、移植性が Linux の推進に有利な環境を提供します。
**2.3 オープンソース、どうやってお金を稼ぐのか? **
「オープンソース」に関する市場の中心的な疑問はビジネスモデルです。 「オープンソース」自体は無料ですが、「オープンソース」が土壌であり、「オープンソースコミュニティ」がさまざまなビジネスモデルを育んできたということは、Linuxエコシステムから学ぶことができます。
2.3.1 Red Hat: サービスファースト
Red Hat は Linux エコシステムのリーダーです。フォーチュン 500 企業の 90% 以上が Red Hat を信頼しており、企業として大きな商業的価値を持っています。 1993 年に Red Hat が設立され、1999 年に Red Hat が Nasdaq に上場されました。IDC データを引用した Red Hat 目論見書によると、1998 年の時点で、認可された Linux オペレーティング システムの新規インストール全体の 56% が Red Hat からのものでした。 2012 年に Red Hat は収益が 10 億ドルを超える初のオープンソース テクノロジー企業となり、2019 年に IBM は約 340 億ドルで Red Hat を買収しました。
Linux と Red Hat のビジネス モデルについては、Curiosity Daily の例え話のようなものですが、ある意味、オープンソースの Linux カーネルは無料でオープンなレシピのようなもので、Red Hat はレストランのようなものです。レストランでは加工品を味わい、行き届いたサービスをお楽しみください。 Red Hat は、企業向けに Linux オペレーティング システムとサブスクリプション サービスを提供しています。主なサービスには、1. 24*7 テクニカル サポート、2. アップストリーム コミュニティおよびハードウェア メーカーと協力して、x86、ARM、 IBM Powerなど、3. 継続的な脆弱性アラート、方向性ガイダンス、自動修復サービス、4. 複数クラウドへの導入、5. リアルタイムカーネルパッチ適用やセキュリティ標準認証などのセキュリティ保護機能、6. パフォーマンス異常の検知と構築システムパフォーマンスの包括的なビュー、およびプリセット調整プロファイルの適用など。

2.3.2 Android システム (Android): Google が支援し、広告によって収益化されています
Statcounterのデータによると、2023年4月時点でAndroid(アンドロイド)は世界ナンバーワンの携帯電話OSで、市場シェアは69%で2位(iOS、31%)を大きく上回っている。 Android は Linux カーネルに基づいて開発され、2005 年に Google に買収されました。その後、GoogleがApacheの無償オープンソースライセンスの認可を受けてAndroidのソースコードを公開し、メーカーがAndroid搭載スマートフォンを迅速に発売できるようになり、Androidの普及が加速した。
ビジネスモデルとしては、地図、Google Play アプリストア、検索、Google Mail (Gmail) など、Android スマートフォンにプリインストールされているサービスの多くは Google 独自の製品によって提供されており、Android は無料でオープンソースですが、Googleモバイル市場は「都市と領土を包囲」し、ユーザー トラフィックを収益化します。
Google は、Android 携帯電話メーカーからも直接ライセンス料を請求しています。2018 年 10 月 29 日以降、Android ベースの携帯電話およびタブレットを使用する EU のメーカーは、デバイスごとにライセンス料を Google に支払う必要があります。機器の費用は最大 40 ドルになる場合があります。
2.4 オープンソース大規模モデルのメインストリーム ライセンスは商用利用をサポートします
オープンソース コミュニティには、GPL、BSD、Apache などのよく知られたライセンスがすでにあります。大規模モデルに関しては、2023 年 2 月にリリースされ、オープンソースの大規模モデルの波を先導した LLaMA は商用利用が禁止されており、研究目的でのみ使用できることがわかりました。特定の状況に応じた社会集団、学術関係者、業界の研究実験、部屋、モデルへのアクセス。このうち、LLaMA の推論コードは GPL3.0 ライセンスに基づいており、これは、1) LLaMA の推論コードを他人が変更した後はソースを閉じることができない、2) 新しいコードも GPL ライセンスを採用する必要があることを意味します。ただし、一部の開発者が、異なる種類のライセンスを使用して LLaMA に基づくバリアント モデルを開発していることに気づきました。たとえば、nanoGPT の LLaMA に基づく Lit-LLaMA の実装では、いくつかのモデルの重みが追加され、モデルのこの部分で使用されるライセンスは Apache2.0 です。
**オープンソースの大規模モデルで採用されているプロトコルは主に Apache 2.0 と MIT ライセンスです。 **Alpaca、Vicuna、Dolly、OpenAssistant、および MOSS はすべて Apache 2.0 ライセンスの下にあり、Koala および GPT4all は MIT ライセンスの下にあります。どちらのライセンスでも商用利用が許可されています。残念ながら、Alpaca、Vicuna、Koala、および GPT4all は、OpenAI または LLaMA の制限により市販されていません。同時に、Apache2.0 ライセンスと MIT ライセンスの両方がソース コードの変更とクローズを許可していることにも注目する価値があり、企業はオープン ソース モデルに基づいて独自のモデルを開発することも、より魅力的なものになるでしょう。会社。

3. 共通点 2: パラメータが少なく、小型化されたオープンソースの大規模モデル
「モデルのパラメータのサイズ」は、「モデルの計算能力の要求」と正の関係があります。
**3.1 超大型モデルと大型モデルの大きさはどれくらいですか? **
**事前トレーニングにより、モデルに基本的な機能が与えられます。 **自然言語処理 (NLP) における事前トレーニングとは、特定のタスクを微調整する前に、大規模なテキスト コーパスで言語モデルをトレーニングし、モデルに基本的な言語理解機能を与えることを指します。事前トレーニング中に、モデルは前のコンテキストに基づいて文内の次の単語を予測するようにトレーニングされます。これは、入力内の単語の一部をマスクしてモデルにそれらの予測を依頼することによって、または文内の前の単語に基づいて次の単語を予測する自己回帰手法 (GPT など) によって行うことができます。
事前トレーニング モデルには通常、多数のパラメーターと対応する事前トレーニング データ (通常は識別子、つまりトークンの数によって測定されます) が含まれています。 2017 年、Google Brain Team Transformer (トランスフォーマー) モデルの登場により NLP の様相が完全に変わり、モデルによる言語の理解と処理が向上し、NLP タスクの効果と精度が向上しました。

**特大モデルと大型モデルの大きさはどれくらいですか? **言語モデルのサイズは、主にニューロン間の接続強度の調整可能な値を記述するパラメータ量に従って測定されます。現在、大規模な言語モデルのパラメータは数百から数百億に及ぶのが一般的であり、GPT-3(パラメータ数1,750億)のように、パラメータ数が1,000億を超えるものは「超大規模モデル」と呼ばれています。
3.2 GPT超大型モデルは最強の能力を持つが再現が難しい
** 大型機種の性能評価基準は統一されていません。 **重要な理由は、大規模なモデルがコンテンツを生成するには多くの種類のタスクがあり、異なるアプリケーション シナリオやタスクでは、モデルのパフォーマンスを評価するために異なる指標や方法が必要になる可能性があることです。これらのタスクの中には、機械翻訳の BLEU など、信頼性の高いスコア基準があるものもありますが、ほとんどのタスクには同様の基準がありません。
** あいまいなコンセンサスは、非常に大規模なモデルが良好にパフォーマンスするということです。 **大規模言語モデルの現在の開発傾向はますます大きくなっています (詳細については、以下の図を参照)。これは、大規模モデルの方が事前トレーニング後の汎用性と安定性が優れているためです。たとえば、Google チームの超大規模モデル PaLM (パラメータ 5,400 億) は、ゼロサンプル テストと小規模サンプル テストの両方で良好な結果を示しており (詳細については、次の図を参照)、そのパフォーマンスはトレーニング識別子の数に応じてさらに向上する可能性があります。が増加します。これは理解するのが難しいことではなく、簡単に言うと、モデルをたくさん見れば見るほど、自然と知識が増えるということです。

**「Peer Review」、GPTベースの大型モデル「Peerless Beauty」。 **現在、OpenAI GPT システムの超大型モデルは、強力な機能と幅広いアプリケーションを備えており、自然言語タスクを処理する際に高い精度と強力な表現力を備えており、テキスト生成、質問などの多くの分野で使用されています。これらはいずれも優れた成果を上げており、自然言語処理分野における現在のベンチマークの 1 つとなっており、さまざまな大規模モデルの比較ベンチマークとして使用されています。 ChatGPT を再現するための敷居は下がっておらず、大規模なオープンソース モデルのほとんどは一部の点でパフォーマンスが優れているだけで、全体的な品質は依然として ChatGPT と比較できません。

また、最近では以下のような評価システムも注目されていますが、その評価方法には主に機械による自動評価(GPT4など)や人間によるブラインド評価などが含まれます。 、GPTシステム ビッグモデルはどれも一流です。
- 海外
- バークレー大学の Chatbot Arena は、ゲームの予選メカニズムを利用して、人間がモデルをペアで盲目的に評価できるようにしています。
- オープンソース ツールキット Zeno Build は、Hugging Face またはオンライン API を通じて、Critique を使用して複数の大規模モデルを評価します。
- 海外
- SuperCLUE は、中国の汎用大型モデルの総合評価ベンチマークであり、大型モデルの自動評価を試みています。
- C- 52 科目をカバーする 14,000 の多肢選択問題は、モデルの中国語能力を評価するために使用されますが、同様の基準にはまだ時間と市場テストが必要です。
3.2.1 ビクーニャ: GPT-4 による評価
**現時点では、ほとんどのオープンソースの大規模モデルのパフォーマンスは体系的に評価されておらず、多くは実験の初期段階にあります。 **パフォーマンスを評価するための大規模なオープンソース モデルの中で、Vicuna のレポートにある GPT-4 を使用した評価は比較的体系的であり、結果は最も印象的です。

3.2.2 Zeno ビルドの評価: より新しく、より包括的な
Zeno Build は GPT-2、LLaMA、Alpaca、Vicuna、MPT-Chat、Cohere Command、ChatGPT (gpt-3.5-turbo) の 7 つのモデルを評価し、結果は GPT-4 の結果と同様でした。 ChatGPT には明らかな利点があり、Vicuna はオープンソース モデルの中で最高のパフォーマンスを発揮します。

3.2.3 C-: 包括的な中国語基本モデル評価キット
C- 評価結果は、中国語能力の点でも GPT-4 が最高であることを示していますが、GPT-4 の正解率は 67% にすぎません。現時点では、大型モデルの中国語処理能力にはまだ多くの限界があります。改善の余地あり。

3.2.4 GPT 超大規模モデルのトレーニング コストは高く、短期間での再現は困難
**ChatGPT にはかなりのコンピューティング能力とトレーニング コストが必要です。 **ChatGPT の前世代 GPT-3 論文「言語モデルは少数のショット学習者である」の計算によると、日常の活動に関連性の高い推論プロセスに必要な計算能力は考慮せず、トレーニング プロセスのみを考慮します。 (1,750 億パラメータ版) 必要な計算能力は 3,640PF 日にも及びます (つまり、1 秒あたり 1 京回の浮動小数点演算を実行すると、3,640 日分の計算が必要になります)。 1 枚の Nvidia A100 グラフィックス カードの電力は約 0.6PFLOPS で、GPT-3 を 1 回トレーニングすると (1,750 億パラメータ バージョン)、約 6,000 枚の Nvidia A100 グラフィックス カードが必要になります。相互接続損失を考慮すると、約数万枚の A100 が必要になります。 A100チップ1個の価格は約10万元で、大規模なトレーニングには約10億元の投資が必要です。 OpenAI は、GPT-3 (1,750 億パラメータ) のトレーニングに 400 万ドル以上を費やし、理論的にはそれぞれより高い ChatGPT と GPT4 (パラメータ数は公表されていないが、さらに多くなることが予想される) の動作を維持するために費やしました。月。
3.3 オープンソースの大規模モデルはコスト効率が高く、超大規模モデル以下の大規模モデルの障壁はなくなりつつあります
**大規模なオープンソースモデルの小型化の傾向は明らかであり、パラメータは約数百億に達しており、質問の意味はコスト削減です。 **オープンソースの大規模モデルは通常、パラメータが少なく、設計、トレーニング、展開の点で必要なリソースとコストが比較的低くなります。このオープンソースの大規模モデルの波のパラメーターは一般に小さく、10 億から 100 億のレベルです。

「ボートが小さくて小回りが利く」という、既存のオープンソースの事前学習モデルをベースにした微調整も、オープンソースの大型モデルの利点の1つです。この方法は、さまざまなタスクやアプリケーション シナリオに適応するために事前トレーニングされたモデルに基づいて微調整および最適化するため、モデルのトレーニング時間とコストを大幅に削減できるだけでなく、モデルのパフォーマンスと効率も向上します。
**より多くの識別子トレーニング データと新しいテクノロジーにより、超大規模モデル以下の大規模モデルに対する障壁はなくなる傾向にあります。 **LLaMA は「オープンソース」であるため、誰もが使用できる大規模なモデルを所有しており、DeepSpeed や RLHF などのテクノロジーの発展により、数百億のモデルをコンシューマ グレードの GPU に展開できます。
- より多くのパラメータよりも多くの識別子のトレーニング データの方が重要である可能性があります: 2022 年 3 月 29 日に公開された DeepMind の研究「Training Compute-Optimal Large Language Models」では、モデル サイズとトレーニング データのサイズの関係が次のように明らかになりました。
- 大規模なモデルは十分にトレーニングされていないことが多く、その結果、計算能力が大幅に浪費されます。
- 小さいモデルを使用してより完全にトレーニングすると、大きいモデルよりも優れたパフォーマンスを達成できます。たとえば、DeepMind のチンチラ モデルには 700 億個のパラメータしかありませんが、1 兆 4000 億の識別子のトレーニング データ セットでトレーニングした後のテスト効果は、DeepMind の Gopher (2,800 億のパラメータ、3,000 億の識別子のトレーニング データ セット) や OpenAI の GPT よりも優れています。 -3 (1,750 億のパラメータ、3,000 億の識別子トレーニング データセット)。
- モデルのパフォーマンスを向上させるには、モデル パラメーターの数が 2 倍になるたびに、それに応じて識別子トレーニング データ セットのサイズも 2 倍にする必要があります。
- モデルが小さいということは、下流の微調整と推論のコストも小さいことを意味します。
- DeepSpeed テクノロジー: 大規模モデルのトレーニングにかかる時間とコストを大幅に削減できます。
- RLHF (ヒューマン フィードバックに基づく強化学習): 少量の識別子トレーニングでモデルのパフォーマンスと精度を向上させることができます。

4 番目、共通点 3: オープンソースの大規模モデル データセットは人間の指示を重視し、自立する
「データセットのサイズ」も「モデルに必要な計算能力」と正の関係があります。
4.1 ChatGPT 方法論を学び、人間による指示データセットを導入する
**微調整は、特定のパフォーマンスを向上させるための近道です。 **微調整とは、ラベル付きデータを含むタスク固有のデータセットを使用して、事前トレーニングされたモデル上でさらに小規模なトレーニングを行うことを指します。微調整により、コンピューティング能力をわずかに犠牲にしてモデルをタスク固有のデータやシナリオにさらに適合させることができるため、モデルのパフォーマンスと精度が向上します。現在、微調整は主に命令の微調整であり、命令データ セットは徐々にオープンソースの大規模モデルの標準構成になりつつあります。
RLHF (Reinforcement Learning from Human Feedback、人間のフィードバックに基づく強化学習) は、強化学習技術を使用して言語モデルをトレーニングし、人間のフィードバックに基づいてモデルの出力を調整する新しい微調整手法です。 RLHF (人間のフィードバックに基づく強化学習) は、ChatGPT の初期バージョン GPT3 にはない機能であり、わずか 13 億のパラメーターを持つ InstructGPT が、1,750 億のパラメーターを持つ GPT-3 よりも優れた信頼性、無害性、人間による指示を示します。準拠度は次のとおりです。学術的評価の側面に対する GPT-3 の効果を損なうことなく、アノテーターによってより認識されるようになります。
RLHF (ヒューマン フィードバックに基づく強化学習) は 3 つのステップに分かれています: 1) 教師あり微調整 (SFT): アノテーターに人間の質問に答えさせ、このアノテーション データを使用して GPT をトレーニングします; 2) 報酬モデル (RM) トレーニング:アノテーターに機械の回答を並べ替えさせる最初のステップでアノテーターが直接回答を書き込む生成ラベリングと比較して、識別ラベルとして分類するコストが低くなりますこのラベルを使用してモデルをトレーニングし、シミュレーションさせます人間による選別; 3) 人間による注釈なし、近接ポリシー最適化アルゴリズム (PPO) を使用した微調整モデル。
これら 3 つのステップに対応するデータ セットのサイズは、それぞれ 13,000、33,000、および 31,000 です。

大量のデータとある程度のコンピューティング能力を持つ企業の場合、微調整に自社のデータを使用することでモデルの特殊化機能を実証し、より少ないコンピューティング能力で大規模モデルに近い効果を達成できます。たとえば、複数の学校が共同開発したVicuna言語モデルは、MetaのLLaMA-130億パラメータバージョンモデルに基づいて、7万人のユーザーが共有するChatGPT対話命令を微調整し、一部のタスクでGPT4の効果の92%を達成しました。汎用性や安定性の点では超大型モデルを超えることはできませんが、微調整により機能を強化できる部分もあり、よりコストパフォーマンスが高く、より中小企業に適しています。
4.2 商用利用を目的としたデータセット
データセットは言語モデル開発の重要な基盤およびサポートであり、通常は企業や組織によって収集、整理、または直接購入されます。対照的に、オープンソース データセットは、ほとんどの場合、コミュニティまたは学術界によって共同で維持されており、データの量と種類は豊富ですが、特定のデータ品質の問題や適用性の違いが存在する可能性があります。
4.2.1 少量の事前トレーニング データセットが市販されています
**事前トレーニング データセットのオープンソースは、モデルの商用利用にとって非常に重要です。 ** ポスト LLaMA の時代には、大規模なオープンソース モデルが雨後の筍のように出現しましたが、すぐに LLaMA と OpenAI の制限により、それらに基づくモデルが商用利用できないことに誰もが気づきました (Alpaca、Koala、GPT4All、 Vicuna) は、この状況を打破するために、Dolly2.0 が主導権を握りました。「この問題を解決するために、私たちは商業利用向けに汚染されていない新しいデータ セットを作成する方法を探し始めました。 』に続いて『赤いパジャマ』と『MOSS』。
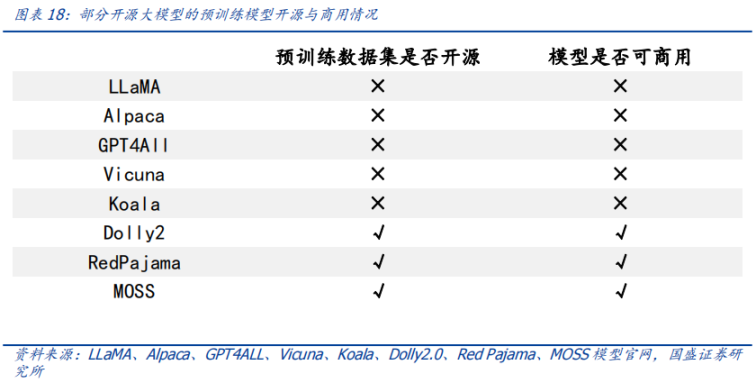
4.2.2 命令データセットの一部は市販されています
**オープンソースのエコロジーを構築し、それぞれが必要なものを取り入れます。 **初期のオープンソース プロジェクトでは、指示データが主に ChatGPT 生成または対話コンテンツからのものであったため、OpenAI の制限により商用利用できませんでした。研究目的での微調整に加えて、この制限を回避するために独自の命令データセットを構築することを選択するモデルが増えています。
**命令データセットは多様化しており、一部の機種の命令データセットは市販されています。 **このバッチの大規模モデルの上記の分類によると、LLaMA、LLaMA に基づいて開発されたモデル、OpenAI 命令データ セットを使用する StableLM を除き、他の大規模モデルの命令データ セットは OpenAI に基づいていないため、これらの商用大規模モデル用の命令データセットが利用可能になると、RLHF (ヒューマン フィードバックによる強化学習) トレーニング パラダイムを使用して、そのような大規模モデルの進化と開発が加速されます。

5. 今後の見通し
私たちは、オープンソースのメガモデルが同様の交差点に向かっていることに気づきました。
5.1 マルチモダリティ: 汎用人工知能 (AGI) の開発を促進
**マルチモーダルなオープンソースの大規模モデルが登場し始めており、大規模モデルを新たな頂点に押し上げ、人類が一般的な人工知能に移行するのを助けています。マルチモダリティとは、画像、音声、テキストなどのさまざまなモードを統合することを指します。マルチモーダル モデルは、複数の入力タイプを処理および分析できる機械学習技術に基づいており、大規模なモデルをより汎用性の高いものにします。マルチドメインの知識に基づいて、統合された、クロスシナリオ、マルチタスクのモデルを構築し、人類を汎用人工知能 (AGI) の時代へ推し進めます。 **
5.1.1 ImageBind がデビューし、画像を使用して 6 つのモードを開く
**ImageBind のオープンソースの大規模モデルは、単一の感覚体験を超えて、マシンに「関連付け」機能を持たせることができます。 ** 5 月 9 日、Meta Corporation はオープンソースのマルチモーダル大規模モデル ImageBind を発表しました。このモデルは画像をコアとして、画像(写真/ビデオ)、温度(赤外線画像)、テキスト、オーディオ、深度情報(3D)、モーションキャプチャセンサー(IMU)を含む6つのモードに接続できます。関連するソース コードは GitHub でホストされています。研究チームは、将来的には、触覚、嗅覚、脳磁気共鳴信号などのモダリティも追加される予定だと述べた。
技術的には、ImageBind はネットワーク データ (画像、テキストなど) を活用し、それを自然に発生するペアのデータ (音声、深度情報など) と組み合わせて、単一の結合埋め込み空間を学習し、ImageBind が暗黙的にテキストを結合するようにします。埋め込みは他のモダリティに合わせて調整されます。明示的な意味論的またはテキストのペアリングを必要とせずに、これらのモダリティでゼロショット認識を可能にします。
現在、ImageBind の一般的な使用例としては、犬の鳴き声をモデルに入力するとモデルが犬の写真を出力する、またはその逆、鳥の写真と海の波の音をモデルに入力する、などがあります。モデルはビーチにいる鳥の写真を出力し、その逆も同様です。

5.1.2 オープンソースの大規模モデルのマルチモーダルな探索は画像に焦点を当てていますが、進歩は急速です
現時点では、オープンソースの大規模モデルにおけるマルチモダリティの探求はまだ初期段階にあり、6 つのモダリティを公開した ImageBind を除いて、そのほとんどはまだテキストと画像の融合を探求していますが、そのスピードは非常に速いです。それらのいくつかを整理しました。
VisualGLM-6B: コンシューマ グラフィック カードにローカルに展開可能
- チーム: VisualGLM-6B は、オープンソースの大規模言語モデル ChatGLM-6B のマルチモーダル アップグレード バージョンで、画像、中国語、英語をサポートしており、清華大学の知識工学およびデータ マイニング グループによってリリースされています。 ※技術:VisualGLM-6Bは言語モデルChatGLM-6Bと画像モデルBLP2-Qformerを組み合わせたもので、両者を組み合わせたパラメータは78億(62億+16億)となります。このモデルで使用される事前トレーニング データセットは、CogView データセット内の 3,000 万の高品質の「中国語の画像とテキスト」のペアと 3 億の「英語の画像とテキスト」のペアです。微調整段階では、人間の好みに合った回答を生成するために、長い視覚的な質問応答データセットでモデルがトレーニングされます。
- パフォーマンス: DataLearner によると、VisualGLM-6B はモデル量子化テクノロジを統合しており、ユーザーはコンシューマー グレードのグラフィック カードにモデルをローカルに展開できます。INT4 量子化レベルでは 8.7G のビデオ メモリのみが必要です。これは、ゲーム用ラップトップを使用しているユーザーでもモデルを迅速かつプライベートに展開できることを意味します。これは、このサイズの ChatGPT のようなモデルとしては初めてのことです。
UniDiffuser: UniDiffuser、マルチモダリティ向けに設計された確率的モデリング フレームワーク
*チーム:清華大学コンピューターサイエンス学部のZhu Jun教授が率いるTSAILチームは、3月12日に論文「One Transformer fits All Distributions in Multi-Modal Diffusion at Scale」を発表し、いくつかのマルチモーダル探索を実施した。 ※技術:UniDiffuserは、同チームが提案したTransformerベースのネットワークアーキテクチャU-ViTを採用し、オープンソースの大規模グラフィックデータセットLAIONの50億パラメータ版で10億パラメータのモデルを学習させることで、高処理を可能にしました。 -品質はさまざまな生成タスクを完了します。
- 機能: 簡単に言えば、このモデルは、一方向の vin 生成グラフに加えて、グラフ生成テキスト、グラフテキスト結合生成、無条件グラフテキスト生成、グラフテキスト書き換えなどの複数の機能も実現できます。 、任意のモード間の相互変換を実現します。
LLaVA: 一部の命令のパフォーマンスは GPT-4 に匹敵します
- チーム: LLaVA はウィスコンシン大学マディソン校、マイクロソフト リサーチ、コロンビア大学が共同制作し、GitHub でコード、モデル、データセットをオープンソース化しています。
- 技術: LLaVA は、一般的な視覚と言語の理解のためにビジョン エンコーダーと大規模な言語モデルを接続する、エンドツーエンドのマルチモーダル大規模モデルです。
- 関数:
- テキストベースのタスク: LLaVA はテキストを処理および分析し、ユーザーが質問したり、ユーザーとチャットしたり、文書の概要の抽出、センチメント分析、エンティティ認識など、ユーザーが入力したタスクを完了したりできます。
- 画像ベースのタスク: LLaVA は、画像の分析、画像の説明、オブジェクト認識の実行、シーンの分析と理解が可能です。
- パフォーマンス: 初期の実験では、LLaVA のマルチモーダル チャット機能が、目に見えない画像/コマンドでは GPT-4 に匹敵するパフォーマンスを出力できる場合があり、合成マルチモーダル コマンドに従うデータセットでは GPT-4 に匹敵するパフォーマンスを出力できることが示され、85.1% の相対スコアが得られました。
MiniGPT-4: LLaMA から生まれたマルチモーダルなオープンソースの大規模モデル、個人ユーザー向けの GPT-4 の「代替品」
- チーム: マルチモーダル GPT-4 大型モデルのリリースにより、大型モデルに対する国民の熱意は新たな最高潮に達しました。ただし、GPT-4 は個人にとって完全に無料ではないため、GPT-4 を使用したい場合は、正式な招待に合格するか、有料アカウントにアップグレードする必要があります。ただし、有料であっても、一部の地域では関連サービスを購入できない場合があります。このような環境において、キング・アブドラ科学技術大学の Deyao Zhu 氏、Jun Chen 氏らは 4 月 23 日に MiniGPT-4 をリリースしました。これは、事前トレーニングされた視覚エンコーダーからの視覚情報を高度な大規模言語モデルと結合することを目的としています。
- テクノロジー: 具体的には、MiniGPT-4 は、EVA-CLIP の ViT-G/14 と Q-Former で構成される BLIP-2 と同じ事前トレーニング済みビジョン コンポーネントを使用し、大規模な言語モデル Vicuna チューニングを使用して、さまざまな複雑な言語を実行できます。タスク。
- 機能: MiniGPT-4 は、シーフードのごちそうの写真をアップロードするとレシピを取得でき、製品のレンダリングの写真をアップロードすると商品と一緒にコピーを取得できる、HTML コードなど、さまざまな遊び方を実現できます。 MiniGPT-4 を使用した人のフィードバックによると、MiniGPT-4 の全体的な効果は良好ですが、現在の中国語のサポートを改善する必要があります。
mPLUG-Owl: モジュール式マルチモーダル大規模モデル
- チーム: mPLUG-Owl は、Alibaba DAMO Academy の mPLUG シリーズの最新作であり、mPLUG シリーズのモジュール型トレーニングのアイデアを継承し、大規模な言語モデルをマルチモーダルな大規模モデルに移行します。
- テクノロジー: mPLUG-Owl は、基本的なビジュアル モジュールとして CLIP ViT-L/14 を使用し、テキスト デコーダとして LLaMA によって初期化された構造を使用し、視覚機能を再構成するために Flamingo と同様の Perceiver Resampler 構造を使用します。さらに、mPLUG-Owl は、視覚関連の指導評価のための包括的なテスト セット Owl を初めて提案します。
- 機能: mPLUG-Owl は、強力なマルチターン対話能力、推論能力、ジョーク解釈能力を備えています。さらに、研究チームは、mPLUG-Owl が複数画像の関連付け、複数言語、テキスト認識、文書理解などの予期せぬ機能を示し始めていることも観察しました。
- パフォーマンス: 視覚関連のコマンド応答タスクにおいて、mPLUG-Owl が BLIP2、LLaVA、および MiniGPT4 よりも優れていることが実験により証明されています。
5.2 専門分野: 下流の生態学的力、特定のタスクに合わせてモデルを微調整する
大規模モデルのオープンソースは、下流生態系の活発な成長に絶好の機会を提供し、細分化された産業の発展の下で、特定のタスクに基づいて大規模モデルがさらに開発され始め、人間の生活を変えます。オープンソースの大規模モデル LLaMA の発表以来、医療相談分野の Huatuo など、LLaMA の事前トレーニング モデルの微調整に基づく下流の特殊モデルが登場し始めています。
- チーム: Hua Tuo は、中国の医学知識に基づいた LLaMa 指示の微調整モデルであり、インテリジェントな尋問のレベルで優れたパフォーマンスを発揮し、より信頼性の高い医学知識の回答を生成できます。生物医学分野では、特定の医療専門知識コーパスが欠如しているため、公開されている大規模な言語モデルのパフォーマンスが低くなります。 4月14日、ハルビン工業大学のチームは、LLaMaモデルを微調整した後に得られた、医療分野向けのオープンソースのインテリジェント診察モデルであるHua Tuoをリリースした。
- テクノロジー: LLaMA には 70 億から 650 億のパラメーターを含む複数のバージョンがありますが、より迅速かつ効率的にトレーニングし、トレーニング コストを節約するために、Huatuo は 70 億パラメーターの LLaMA バージョンを基本モデルとして使用します。医療分野での質問に答える際のモデルの精度を確保するために、研究者らは中国の医学知識グラフCMeKGから関連する医学知識を抽出し、さまざまな指導データを生成し、教師付き微調整のために8,000以上の指導データを収集しました。モデルの回答が質問の事実に基づいて正確であることを確認するため。

- パフォーマンス: モデルのパフォーマンスに関して、HuaTuo は他の 3 つのベンチマーク モデルと比較されます。モデルのパフォーマンスを評価するために、研究者らは医学的背景を持つ 5 人の専門医師を採用し、安全性、使いやすさ、定常性 (SUS) の 3 つの側面で評価しました。 SUS スケールは 1 (許容できない) から 3 (良好) までで、2 は許容できる応答を示します。 SUS スコアの平均を以下のグラフに示します。結果は、HuaTuo モデルがセキュリティをあまり犠牲にすることなく、知識の可用性を大幅に向上させることを示しています。

Huatuo は、将来、オープンソースの大規模モデルの下流で特定のタスク モデルを開発するためのパラダイムになる可能性があります。つまり、パラメーター量が少ない小規模なオープンソースの大規模モデルを基本モデルとして使用し、特定のタスクのデータでトレーニングするというものです。より優れたパフォーマンスのセグメンテーション ドメイン モデルを取得するための専門分野。
6. 投資アドバイス
オープンソースの大規模モデルの開発は広範囲に影響を及ぼしますが、このレポートでは恩恵を受ける可能性のあるいくつかの方向性を選択し、市場の注目を集めています。
6.1 Microsoft: OpenAI との緊密な連携
私たちは、短期的には ChatGPT システムが依然として最も有能な大規模モデルであり、Microsoft はその綿密な協力から恩恵を受けると考えています。
- Equity On の「Fortune」誌の報道によると、OpenAI の最初の投資家が初期資金を回収した後、Microsoft が投資コスト (130 億ドル) を回収するまで、Microsoft は OpenAI の利益の 75% を受け取る権利があるとのことです。 OpenAIの920億ドルの利益を受けて、Microsoftのシェアは49%に低下する。同時に、他のベンチャー投資家やOpenAI従業員も、約1500億ドルを稼ぐまでOpenAIの利益の49%を受け取る権利が得られる。これらの上限に達した場合、Microsoft と投資家の株式は OpenAI 非営利財団に返還されます。
- 製品では、検索エンジン Bing に ChatGPT を統合できるようにすることに加えて、2023 年 1 月に Microsoft は Azure OpenAI サービスの開始を発表しました。Azure Global Enterprise の顧客はクラウド プラットフォーム上で OpenAI モデルを直接呼び出すことができ、 5. Codex および DALL.E モデルの直後、Microsoft は新しい Bing および Office アップグレード バージョン Copilot への GPT4 の統合を発表しました。
6.2 Nvidia: オープンソースの大規模モデルがアプリケーションの人気を促進し、コンピューティング能力の需要が急増しています
コンピューティングパワーサービスは、オープンソースの大規模モデルの波の中で大きな利益と確実性をもたらす方向であり、ソフトウェアとハードウェアの統合において明確な最先端を有しており、AIコンピューティングパワーの現在のリーダーです。
6.2.1 超大型モデルの計算能力に対する需要は高い成長を維持する
超大型モデルには優れた品質上の利点があり、市場は今後もこのモデルを追求し、そのコンピューティング能力に対する需要は成長し続けるでしょう。超大型モデルは表現力や精度が高く、品質面でも有利であり、今後も市場はこうしたモデルを追い求めていくだろう。超大規模モデル、データセット、日常業務の規模は拡大し続けており、必要なコンピューティング能力は増加し続けるでしょう。
6.2.2 オープンソースの大規模モデルの急速な追い上げは、コンピューティング能力にも恩恵をもたらします
短期的には、市場はオープンソースのビッグモデルに対して様子見の姿勢をとるでしょう。大規模なオープンソースモデルは汎用性が低く、短期間では大規模モデルに太刀打ちできない上に、モデルの具体的な性能を体系的に評価することが現時点では困難であり、市場では様子見の姿勢が続いている。大規模なオープンソース モデルに向けて、そのパフォーマンスと利点が証明されるのを待っています。
** 中長期的には、オープンソースの大型モデルの性能がさらに向上し、市場でより大きなシェアを占めることが予想されます。 **オープンソースの大規模モデルは、超大規模モデルと比較して、計算能力要件が低く、導入が容易であり、素早い微調整やその他の方法により、特定の専門分野向けに最適化することもでき、魅力的かつ実用的です。 。中長期的には、品質の面で ChatGPT のパフォーマンスに近づくか、それを超えるオープンソースの大規模モデルがあれば、そのようなモデルに対する市場の需要は急速に高まる可能性があります。それに応じて、この種のコンピューティング能力の需要も急速に増加するでしょう。
6.2.3 Catalyst: オープンソースの大規模モデルライセンス、標準および能力評価システムの開発
- ライセンス: オープンソース コミュニティで長年開発されてきたライセンス システムにより、開発者の選択肢が豊富になり、大規模なモデルが独自のライセンスを選択できるようになり、それによって商用アプリケーションが促進されてきたと私たちは考えています。大規模モデルの繁栄と発展により、コンピューティング能力に対する市場の需要が高まるのは明らかです。
- 標準: 大規模モデル コミュニティも、Linux 開発標準 LSB と同様の標準を作成する可能性があると予想しています。適切な標準化により、大規模モデルのエコロジーが過度に細分化されるのを防ぐことができます。私たちは、Nvidia などのコンピューティング パワー サービス プロバイダーのパフォーマンスを促進するオープンソース コミュニティの継続的な活力について楽観的です。
- 大型モデル機能評価システム: 信頼できる大型モデル機能評価システムは、市場が大型モデルを迅速に区別するのに役立ち、大型モデル トラックの開発に貢献します。
6.3 メタ: オープンソース エコロジーの恩恵を受けるオープンソースの「前衛」
Android の開発の歴史を振り返ると、Google はオープンソース オペレーティング システム Android の開発者として、オープンソースをツールとして利用する「Google-Android」システムにおける Google の役割に楽観的です。生態系の上流と下流の発展を刺激し、エンド顧客への独自サービスの提供を強化します。
大型モデルにマッピングされたLLaMAのオープンソースメタは、LLaMAを通じて下流の大型モデル開発メーカーとの連携を深め、自社システムで独自製品を顧客に販売できる可能性があると考えています。
6.4 その他
6.4.1 エッジ コンピューティング能力 + オープンソース モデル: AI アプリケーション向けランディング アクセラレータ
エッジ コンピューティングの能力により、推論計算をユーザーのデバイスに配置できるため、データ処理の速度と効率が向上し、推論のコストが削減されるだけでなく、ユーザーのプライバシーとセキュリティも保護されます。
- スマート モジュール: エッジ コンピューティング パワーを搭載する最適なモデルとして、将来の大量の具体化されたスマート製品の下で最も決定的で柔軟な品種です。 MeiG IntelligenceとFibocomに注目することをお勧めします。
- エッジ IDC: 時間遅延とコストの面で利点があり、「はしご型」のコンピューティング能力分布を満たす効果的な補助手段です。 Longyu株とWangsu Technologyに注目することをお勧めします。
- 光学モジュール: Zhongji InnoLight、Xinyisheng、Tianfu Communication、Yuanjie Technology。
- 従来の IoT 通信チップ メーカー: 業界の上昇プロセスから恩恵を受けることが期待されています。 ZTE、Fii、Tsinghua Unigroup、Ruijie Networks、Feiling Kesi、Aojie Technology、Chuling Information に注意を払うことをお勧めします。
6.4.2 ビッグデータ企業: 「オープンソースの大規模モデル + 自社所有の大規模データ」の組み合わせに楽観的
「大量のデータを持っているがコンピューティング能力が不十分」な企業にとっては、自社のデータを使用してオープンソースの商用モデルを完全に事前トレーニングし、微調整する方がコスト効率が高くなります。これにより、モデルの精度と適用性が向上し、モデルのトレーニング時間とコストも大幅に削減できます。さらに、微調整されたモデルは企業の特定のニーズとビジネス シナリオをより適切に満たすことができるため、企業の競争力とイノベーション能力が向上します。テクノロジーの継続的な開発と普及により、企業が独自のデータを使用してインテリジェントなアプリケーションを迅速に実現するための独立した微調整モデルが重要な手段になりました。
6.4.3 オープンソースの大規模モデル サービス プロバイダー: サービス ファースト
Red Hat の開発の歴史を振り返ると、たとえ大規模モデルがオープンソース時代に入ったとしても、24*7 の顧客志向のサービスは、特に企業にとって依然として不可欠であると考えています。私たちは、オープンソースの大規模モデルのサービス プロバイダーについて楽観的です。
6.4.4 Apple: ChatGPT アプリの収益シェアを取得
ChatGPT は App Store に掲載されており、App Store の慣例に従って、Apple が収益の一部を取得します。