Irysはデータをどのように保存しているのでしょうか。分散型データのアップロード、検証、取得プロセスについて詳しく解説します。
従来型ブロックチェーンはデータを副次的要素と捉え、ストレージと実行を分離しています。この構造では、オンチェーンアプリケーションが大規模データを直接活用することが難しくなり、外部サービスへの依存度が高まります。Irysは、データ保存・検証・実行を統合したフレームワークを提供し、こうしたアーキテクチャ上の課題を根本から解決します。
Irysを理解するには、データのアップロード、ネットワーク全体での検証、アクセスや活用方法といった、完全なデータライフサイクルの把握が不可欠です。その基盤となるパーティションストレージとマイニングメカニズム(Partition Lifecycle)は、検証可能性を理解する上で重要な要素です。
Irysデータストレージの基本原則:分散型データレイヤーと検証可能ストレージ
IrysはDatachainアーキテクチャを採用し、データを直接ブロックチェーンのコンセンサスメカニズムに組み込んでいます。従来型ストレージとは異なり、データは単なる保存対象ではなく、検証可能なオンチェーン状態となります。
このモデルでは、すべてのデータが本当に存在しアクセス可能であることをネットワークが必ず確認します。これにより、データは受動的な保存対象から証明可能な存在へと転換し、システム全体の信頼性が向上します。
さらに、Irysはデータと実行環境を統合し、オンチェーン計算においてデータの読み出しと処理を可能にしています。これにより、Irysは単なるストレージプロトコルから基盤的なデータインフラレイヤーへと進化しています。
データアップロードプロセス:ユーザー投稿からオンチェーン記録まで
Irysでのデータアップロードは、ブロックチェーンのトランザクションに類似しています。ユーザーはデータをパッケージ化してネットワークに送信し、その後データはオンチェーン処理パイプラインに入ります。
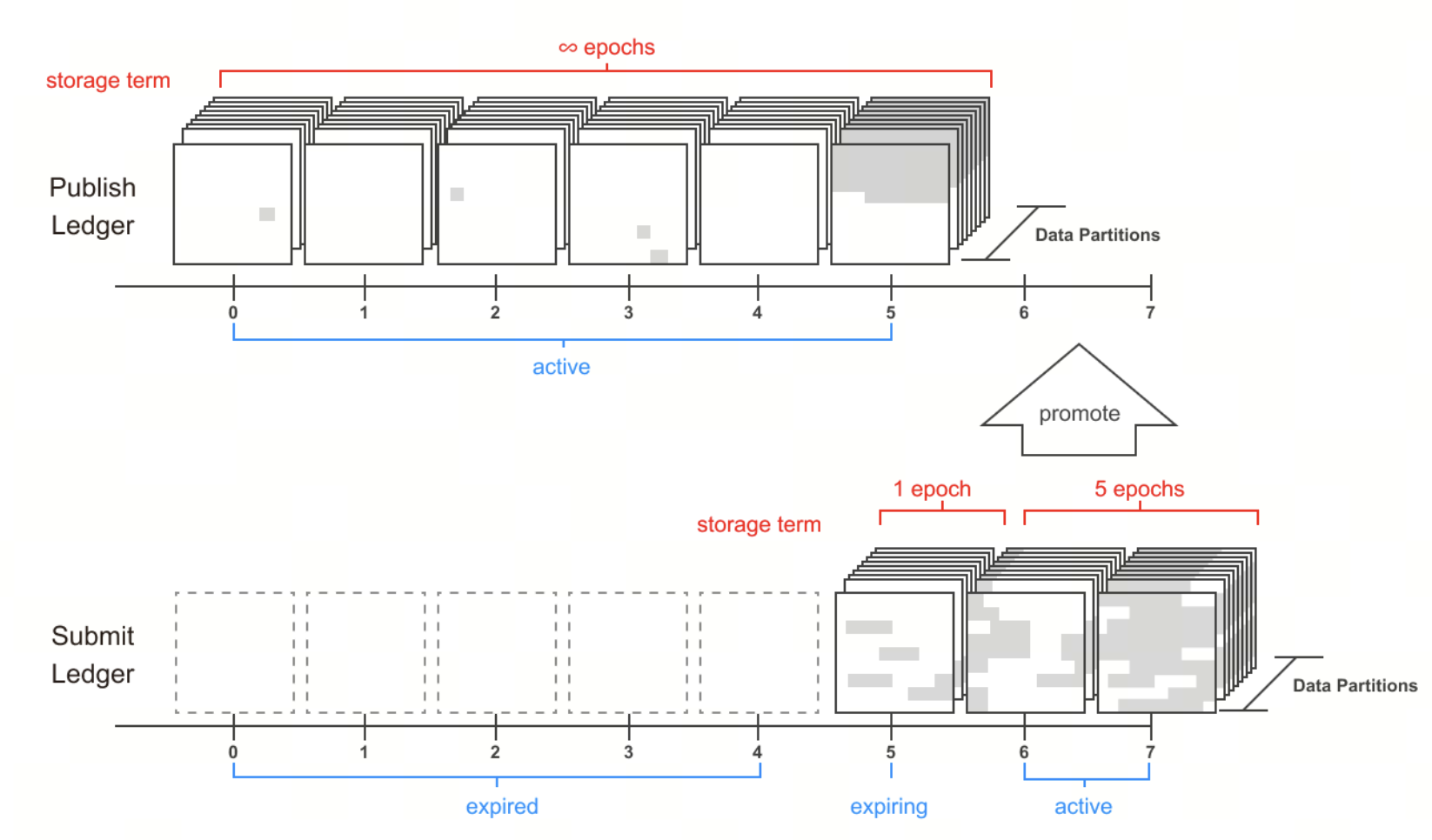
データは中央集約型で保存されることなく、ネットワーク内の複数のストレージパーティションに分割・分散されます。各パーティションは約16TBの容量を持ち、Irysのストレージ構造の基本単位としてスケーラビリティとコスト管理を実現します。
データがブロックに書き込まれると、その状態がオンチェーンに記録され、後続の検証ステップへと進みます。このプロセスによって、完全なデータ書き込みパスが確立され、後の検証や取得の基盤となります。
出典:irys.xyz
データ検証メカニズム:Irysが実現する検証可能なデータ(Proof of Storage / Availability)
Irysの最大の革新は、データ検証をコンセンサスメカニズムに組み込んでいる点です。各ブロックはトランザクションだけでなく、データが実際に存在しアクセス可能であることも証明します。
これは、データサンプリングとハッシュ検証によって実現されます。ネットワークはノードに継続的にデータの一部を読み取らせ、計算を行わせることで、本物の保存状態であることを確認します。
Irysはストレージマイニングメカニズムを導入しており、ノードはブロック生成に参加するために、常時データブロックの読み取りと検証を行う必要があります。これにより、データ検証がネットワーク運用の中核となり、補助的な機能にとどまりません。
この設計により、分散型ストレージ最大の課題である「信頼に頼らずデータの存在を確認する」ことが可能となります。
データ取得とクエリ:Irysデータのアクセス・インデックス・呼び出し
データが保存され検証されると、ユーザーはデータ識別子を使ってクエリや取得が可能です。ネットワークノードはリクエストに応じて該当データを返します。
従来型ストレージと異なり、Irysではデータの読み出しだけでなく、オンチェーンアプリケーションから直接呼び出すこともできます。スマートコントラクトはこのデータを基にロジックを実行でき、外部APIに依存する必要がありません。
この「読み取り・計算可能」な構造により、IrysはWeb3アプリケーション、特にデータ駆動型用途に最適なインフラレイヤーとなっています。
データ可用性の確保:ノード・コンセンサス・パーティションライフサイクル
IrysはPartition Lifecycleメカニズムによって長期的なデータ可用性を保証します。
ネットワークはストレージを複数の16TBパーティションに分割し、以下のプロセスで維持します。
- Partition Pledging:ノードがトークンをステーキングしてストレージに参加
- Partition Packing:Matrix PackingがデータとノードIDを紐付け、複製攻撃を防止
- Partition Mining:ノードがデータを継続的に読み取り計算し、データ存在を証明
- Ledger Assignment:高パフォーマンスノードほど本物のデータ割り当てと高収益を獲得
このライフサイクル全体を通じて、ノードはストレージ能力を継続的に証明しなければならず、そうでなければ報酬の喪失やペナルティが課されます。
ノードがネットワークを離脱した場合も、システムは自動的にデータを再割り当てし、ノードダウンによるデータ損失を防ぎます。この仕組みにより、データ可用性はシステムの本質的な特性となっています。
Irysストレージメカニズムの利点と制約:検証可能性・コスト・パフォーマンス
Irys最大の利点は検証可能なデータです。データはネットワークによって継続的に存在が証明され、信頼に頼らない高信頼性アプリケーションを実現します。
データと実行の統合により、アプリケーションはオンチェーンデータを直接活用でき、外部システムへの依存を低減します。これはDeFiやAIデータなどの用途で特に価値があります。
一方、パーティション・検証・コンセンサスメカニズムなど、システムは複雑で大量のストレージ・計算リソースが必要です。
そのため、Irysは単純なファイル保存ではなく、高いデータ信頼性が求められる環境に最適です。
まとめ
Irysは、データ保存・検証・実行を統合することで新たなWeb3データインフラを確立しています。その中核的な革新は、データの存在・証明・計算への参加を可能にすることです。
パーティショニングと継続的な検証を通じて、Irysは長期的なデータ可用性を担保し、外部システムへの依存を最小化します。このアーキテクチャにより、Irysは従来のストレージプロトコルとは一線を画し、検証可能なデータレイヤーのリーダーとしての地位を確立しています。
よくある質問(FAQ)
1. なぜIrysのデータには検証が必要ですか?
分散型ネットワークは単一ノードに依存できないため、本物のデータ存在を確認する検証メカニズムが必要です。
2. パーティションとは何ですか?
パーティションはIrysにおける基本的なストレージ単位で、一定量のデータ保存と検証に使用されます。
3. Matrix Packingの目的は何ですか?
データをノードに紐付け、データ複製による不正行為を防止します。
4. Irysはどのようにデータ損失を防ぎますか?
分散型ストレージとパーティション再割り当てによって、ノード離脱時でもデータの完全性を確保します。
5. Irysと従来型ストレージの主な違いは何ですか?
従来型ストレージはデータの保存に重点を置きますが、Irysは計算に活用できる検証可能なデータを重視しています。
共有
内容
暗号資産デリバティブ・プラットフォームのLiquidが$18M を調達、NeoとLeft Lane Capitalが主導するシリーズA
ハイパースケール・データのビットコイン保有が急増し、675 BTC超に:価値は$53.1M
EXIOグループとFinoverse AIがToken Planetをローンチ、初期段階プロジェクト向けのAIパワードRWAローンチパッド
中国のMIIT、AIディープシンセシス画像システム仕様を含む690件の産業標準を承認
ハイテク株が市場回復をけん引。暗号資産とベンチャー資金調達が歩調をそろえて回復


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

Plasma(XPL)トークノミクス分析:供給、分配、価値捕捉

